 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA principled framework for uncertainty decomposition in TabPFN
Feb 04, 2026TabPFN is a transformer that achieves state-of-the-art performance on supervised tabular tasks by amortizing Bayesian prediction into a single forward pass. However, there is currently no method for uncertainty decomposition in TabPFN. Because it behaves, in an idealised limit, as a Bayesian in-context learner, we cast the decomposition challenge as a Bayesian predictive inference (BPI) problem. The main computational tool in BPI, predictive Monte Carlo, is challenging to apply here as it requires simulating unmodeled covariates. We therefore pursue the asymptotic alternative, filling a gap in the theory for supervised settings by proving a predictive CLT under quasi-martingale conditions. We derive variance estimators determined by the volatility of predictive updates along the context. The resulting credible bands are fast to compute, target epistemic uncertainty, and achieve near-nominal frequentist coverage. For classification, we further obtain an entropy-based uncertainty decomposition.
Adaptive Diffusion Guidance via Stochastic Optimal Control
May 25, 2025Guidance is a cornerstone of modern diffusion models, playing a pivotal role in conditional generation and enhancing the quality of unconditional samples. However, current approaches to guidance scheduling--determining the appropriate guidance weight--are largely heuristic and lack a solid theoretical foundation. This work addresses these limitations on two fronts. First, we provide a theoretical formalization that precisely characterizes the relationship between guidance strength and classifier confidence. Second, building on this insight, we introduce a stochastic optimal control framework that casts guidance scheduling as an adaptive optimization problem. In this formulation, guidance strength is not fixed but dynamically selected based on time, the current sample, and the conditioning class, either independently or in combination. By solving the resulting control problem, we establish a principled foundation for more effective guidance in diffusion models.
Convergence of Diffusion Models Under the Manifold Hypothesis in High-Dimensions
Sep 27, 2024Denoising Diffusion Probabilistic Models (DDPM) are powerful state-of-the-art methods used to generate synthetic data from high-dimensional data distributions and are widely used for image, audio and video generation as well as many more applications in science and beyond. The manifold hypothesis states that high-dimensional data often lie on lower-dimensional manifolds within the ambient space, and is widely believed to hold in provided examples. While recent results has provided invaluable insight into how diffusion models adapt to the manifold hypothesis, they do not capture the great empirical success of these models, making this a very fruitful research direction. In this work, we study DDPMs under the manifold hypothesis and prove that they achieve rates independent of the ambient dimension in terms of learning the score. In terms of sampling, we obtain rates independent of the ambient dimension w.r.t. the Kullback-Leibler divergence, and $O(\sqrt{D})$ w.r.t. the Wasserstein distance. We do this by developing a new framework connecting diffusion models to the well-studied theory of extrema of Gaussian Processes.
Nonparametric regression on random geometric graphs sampled from submanifolds
May 31, 2024We consider the nonparametric regression problem when the covariates are located on an unknown smooth compact submanifold of a Euclidean space. Under defining a random geometric graph structure over the covariates we analyze the asymptotic frequentist behaviour of the posterior distribution arising from Bayesian priors designed through random basis expansion in the graph Laplacian eigenbasis. Under Holder smoothness assumption on the regression function and the density of the covariates over the submanifold, we prove that the posterior contraction rates of such methods are minimax optimal (up to logarithmic factors) for any positive smoothness index.
Posterior Contraction Rates for Matérn Gaussian Processes on Riemannian Manifolds
Sep 22, 2023


Gaussian processes are used in many machine learning applications that rely on uncertainty quantification. Recently, computational tools for working with these models in geometric settings, such as when inputs lie on a Riemannian manifold, have been developed. This raises the question: can these intrinsic models be shown theoretically to lead to better performance, compared to simply embedding all relevant quantities into $\mathbb{R}^d$ and using the restriction of an ordinary Euclidean Gaussian process? To study this, we prove optimal contraction rates for intrinsic Mat\'ern Gaussian processes defined on compact Riemannian manifolds. We also prove analogous rates for extrinsic processes using trace and extension theorems between manifold and ambient Sobolev spaces: somewhat surprisingly, the rates obtained turn out to coincide with those of the intrinsic processes, provided that their smoothness parameters are matched appropriately. We illustrate these rates empirically on a number of examples, which, mirroring prior work, show that intrinsic processes can achieve better performance in practice. Therefore, our work shows that finer-grained analyses are needed to distinguish between different levels of data-efficiency of geometric Gaussian processes, particularly in settings which involve small data set sizes and non-asymptotic behavior.
Scalable Variational Bayes methods for Hawkes processes
Dec 01, 2022



Multivariate Hawkes processes are temporal point processes extensively applied to model event data with dependence on past occurrences and interaction phenomena. In the generalised nonlinear model, positive and negative interactions between the components of the process are allowed, therefore accounting for so-called excitation and inhibition effects. In the nonparametric setting, learning the temporal dependence structure of Hawkes processes is often a computationally expensive task, all the more with Bayesian estimation methods. In general, the posterior distribution in the nonlinear Hawkes model is non-conjugate and doubly intractable. Moreover, existing Monte-Carlo Markov Chain methods are often slow and not scalable to high-dimensional processes in practice. Recently, efficient algorithms targeting a mean-field variational approximation of the posterior distribution have been proposed. In this work, we unify existing variational Bayes inference approaches under a general framework, that we theoretically analyse under easily verifiable conditions on the prior, the variational class, and the model. We notably apply our theory to a novel spike-and-slab variational class, that can induce sparsity through the connectivity graph parameter of the multivariate Hawkes model. Then, in the context of the popular sigmoid Hawkes model, we leverage existing data augmentation technique and design adaptive and sparsity-inducing mean-field variational methods. In particular, we propose a two-step algorithm based on a thresholding heuristic to select the graph parameter. Through an extensive set of numerical simulations, we demonstrate that our approach enjoys several benefits: it is computationally efficient, can reduce the dimensionality of the problem by selecting the graph parameter, and is able to adapt to the smoothness of the underlying parameter.
Fast Bayesian Coresets via Subsampling and Quasi-Newton Refinement
Mar 18, 2022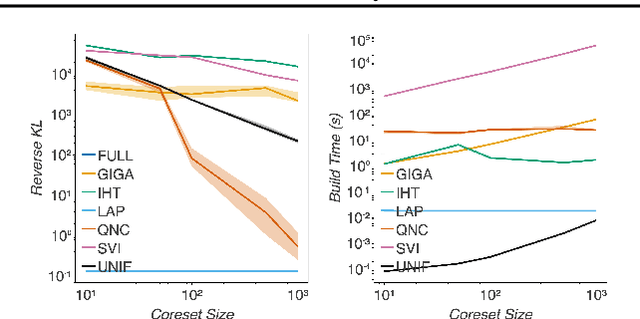

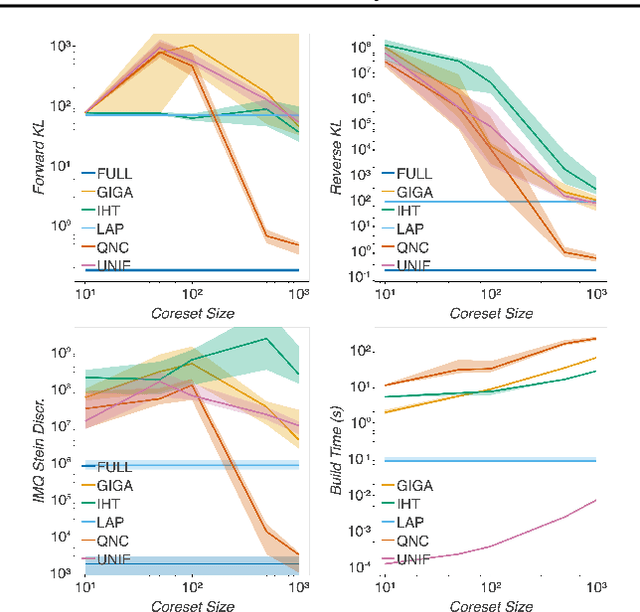

Bayesian coresets approximate a posterior distribution by building a small weighted subset of the data points. Any inference procedure that is too computationally expensive to be run on the full posterior can instead be run inexpensively on the coreset, with results that approximate those on the full data. However, current approaches are limited by either a significant run-time or the need for the user to specify a low-cost approximation to the full posterior. We propose a Bayesian coreset construction algorithm that first selects a uniformly random subset of data, and then optimizes the weights using a novel quasi-Newton method. Our algorithm is simple to implement, does not require the user to specify a low-cost posterior approximation, and is the first to come with a general high-probability bound on the KL divergence of the output coreset posterior. Experiments demonstrate that the method provides orders of magnitude improvement in construction time against the state-of-the-art black-box method. Moreover, it provides significant improvements in coreset quality against alternatives with comparable construction times, with far less storage cost and user input required.
Stable ResNet
Oct 24, 2020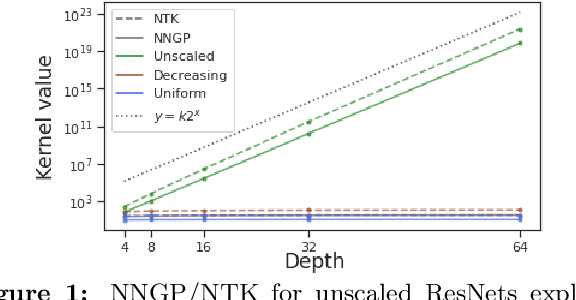
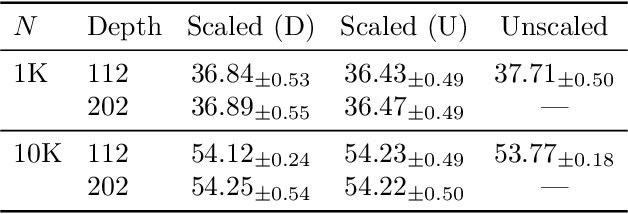
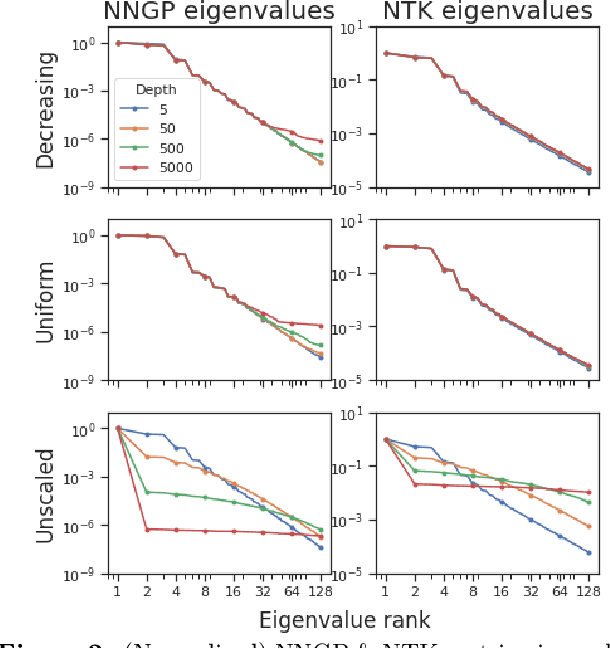
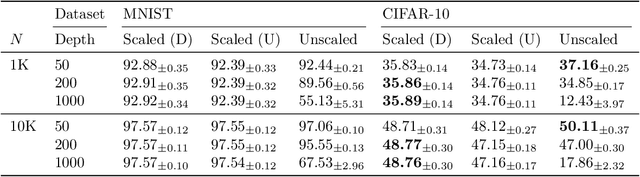
Deep ResNet architectures have achieved state of the art performance on many tasks. While they solve the problem of gradient vanishing, they might suffer from gradient exploding as the depth becomes large (Yang et al. 2017). Moreover, recent results have shown that ResNet might lose expressivity as the depth goes to infinity (Yang et al. 2017, Hayou et al. 2019). To resolve these issues, we introduce a new class of ResNet architectures, called Stable ResNet, that have the property of stabilizing the gradient while ensuring expressivity in the infinite depth limit.
Training Dynamics of Deep Networks using Stochastic Gradient Descent via Neural Tangent Kernel
Jun 07, 2019

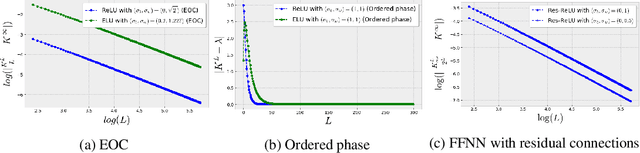
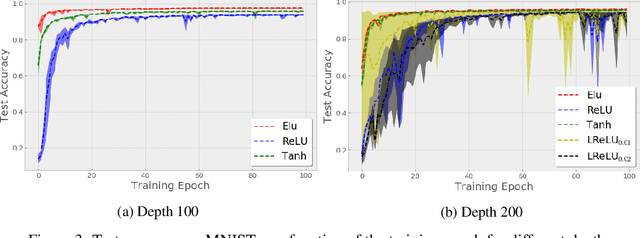
Stochastic Gradient Descent (SGD) is widely used to train deep neural networks. However, few theoretical results on the training dynamics of SGD are available. Recent work by Jacot et al. (2018) has showed that training a neural network of any kind with a full batch gradient descent in parameter space is equivalent to kernel gradient descent in function space with respect to the Neural Tangent Kernel (NTK). Lee et al. (2019) built on this result to show that the output of a neural network trained using full batch gradient descent can be approximated by a linear model for wide neural networks. We show here how these results can be extended to SGD. In this case, the resulting training dynamics is given by a stochastic differential equation dependent on the NTK which becomes a simple mean-reverting process for the squared loss. When the network depth is also large, we provide a comprehensive analysis on the impact of the initialization and the activation function on the NTK, and thus on the corresponding training dynamics under SGD. We provide experiments illustrating our theoretical results.
On the Impact of the Activation Function on Deep Neural Networks Training
Feb 19, 2019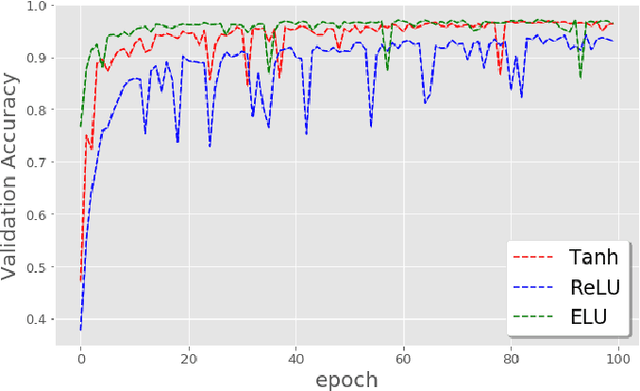
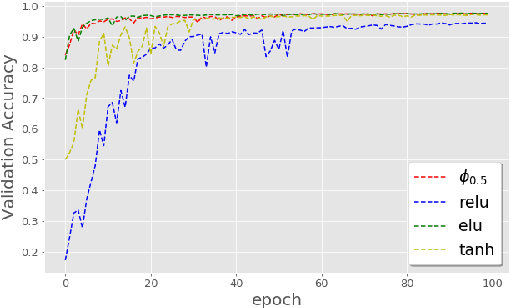
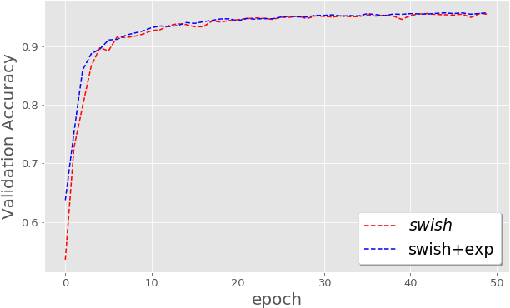
The weight initialization and the activation function of deep neural networks have a crucial impact on the performance of the training procedure. An inappropriate selection can lead to the loss of information of the input during forward propagation and the exponential vanishing/exploding of gradients during back-propagation. Understanding the theoretical properties of untrained random networks is key to identifying which deep networks may be trained successfully as recently demonstrated by Samuel et al (2017) who showed that for deep feedforward neural networks only a specific choice of hyperparameters known as the `Edge of Chaos' can lead to good performance. While the work by Samuel et al (2017) discuss trainability issues, we focus here on training acceleration and overall performance. We give a comprehensive theoretical analysis of the Edge of Chaos and show that we can indeed tune the initialization parameters and the activation function in order to accelerate the training and improve the performance.