 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Dynamics of Deep Networks using Stochastic Gradient Descent via Neural Tangent Kernel
Paper and Code


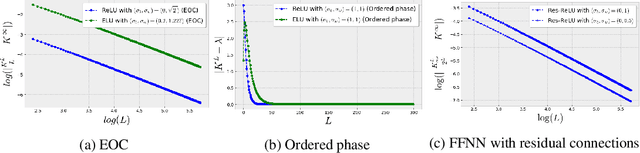
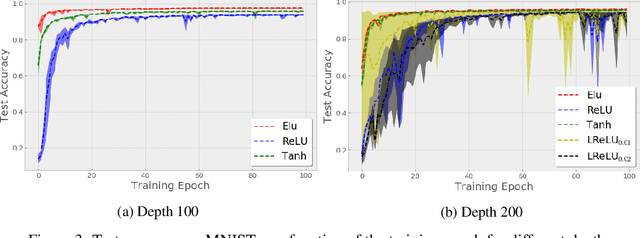
Stochastic Gradient Descent (SGD) is widely used to train deep neural networks. However, few theoretical results on the training dynamics of SGD are available. Recent work by Jacot et al. (2018) has showed that training a neural network of any kind with a full batch gradient descent in parameter space is equivalent to kernel gradient descent in function space with respect to the Neural Tangent Kernel (NTK). Lee et al. (2019) built on this result to show that the output of a neural network trained using full batch gradient descent can be approximated by a linear model for wide neural networks. We show here how these results can be extended to SGD. In this case, the resulting training dynamics is given by a stochastic differential equation dependent on the NTK which becomes a simple mean-reverting process for the squared loss. When the network depth is also large, we provide a comprehensive analysis on the impact of the initialization and the activation function on the NTK, and thus on the corresponding training dynamics under SGD. We provide experiments illustrating our theoretical results.