 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-aware Stopping for Bayesian Optimization
Jul 16, 2025In automated machine learning, scientific discovery, and other applications of Bayesian optimization, deciding when to stop evaluating expensive black-box functions is an important practical consideration. While several adaptive stopping rules have been proposed, in the cost-aware setting they lack guarantees ensuring they stop before incurring excessive function evaluation costs. We propose a cost-aware stopping rule for Bayesian optimization that adapts to varying evaluation costs and is free of heuristic tuning. Our rule is grounded in a theoretical connection to state-of-the-art cost-aware acquisition functions, namely the Pandora's Box Gittins Index (PBGI) and log expected improvement per cost. We prove a theoretical guarantee bounding the expected cumulative evaluation cost incurred by our stopping rule when paired with these two acquisition functions. In experiments on synthetic and empirical tasks, including hyperparameter optimization and neural architecture size search, we show that combining our stopping rule with the PBGI acquisition function consistently matches or outperforms other acquisition-function--stopping-rule pairs in terms of cost-adjusted simple regret, a metric capturing trade-offs between solution quality and cumulative evaluation cost.
The Gittins Index: A Design Principle for Decision-Making Under Uncertainty
Jun 12, 2025The Gittins index is a tool that optimally solves a variety of decision-making problems involving uncertainty, including multi-armed bandit problems, minimizing mean latency in queues, and search problems like the Pandora's box model. However, despite the above examples and later extensions thereof, the space of problems that the Gittins index can solve perfectly optimally is limited, and its definition is rather subtle compared to those of other multi-armed bandit algorithms. As a result, the Gittins index is often regarded as being primarily a concept of theoretical importance, rather than a practical tool for solving decision-making problems. The aim of this tutorial is to demonstrate that the Gittins index can be fruitfully applied to practical problems. We start by giving an example-driven introduction to the Gittins index, then walk through several examples of problems it solves - some optimally, some suboptimally but still with excellent performance. Two practical highlights in the latter category are applying the Gittins index to Bayesian optimization, and applying the Gittins index to minimizing tail latency in queues.
Stochastic Poisson Surface Reconstruction with One Solve using Geometric Gaussian Processes
Mar 24, 2025Poisson Surface Reconstruction is a widely-used algorithm for reconstructing a surface from an oriented point cloud. To facilitate applications where only partial surface information is available, or scanning is performed sequentially, a recent line of work proposes to incorporate uncertainty into the reconstructed surface via Gaussian process models. The resulting algorithms first perform Gaussian process interpolation, then solve a set of volumetric partial differential equations globally in space, resulting in a computationally expensive two-stage procedure. In this work, we apply recently-developed techniques from geometric Gaussian processes to combine interpolation and surface reconstruction into a single stage, requiring only one linear solve per sample. The resulting reconstructed surface samples can be queried locally in space, without the use of problem-dependent volumetric meshes or grids. These capabilities enable one to (a) perform probabilistic collision detection locally around the region of interest, (b) perform ray casting without evaluating points not on the ray's trajectory, and (c) perform next-view planning on a per-slice basis. They also improve reconstruction quality, by not requiring one to approximate kernel matrix inverses with diagonal matrices as part of intermediate computations. Results show that our approach provides a cleaner, more-principled, and more-flexible stochastic surface reconstruction pipeline.
An Adversarial Analysis of Thompson Sampling for Full-information Online Learning: from Finite to Infinite Action Spaces
Feb 21, 2025We develop an analysis of Thompson sampling for online learning under full feedback - also known as prediction with expert advice - where the learner's prior is defined over the space of an adversary's future actions, rather than the space of experts. We show regret decomposes into regret the learner expected a priori, plus a prior-robustness-type term we call excess regret. In the classical finite-expert setting, this recovers optimal rates. As an initial step towards practical online learning in settings with a potentially-uncountably-infinite number of experts, we show that Thompson sampling with a certain Gaussian process prior widely-used in the Bayesian optimization literature has a $\mathcal{O}(\beta\sqrt{T\log(1+\lambda)})$ rate against a $\beta$-bounded $\lambda$-Lipschitz adversary.
The GeometricKernels Package: Heat and Matérn Kernels for Geometric Learning on Manifolds, Meshes, and Graphs
Jul 10, 2024
Kernels are a fundamental technical primitive in machine learning. In recent years, kernel-based methods such as Gaussian processes are becoming increasingly important in applications where quantifying uncertainty is of key interest. In settings that involve structured data defined on graphs, meshes, manifolds, or other related spaces, defining kernels with good uncertainty-quantification behavior, and computing their value numerically, is less straightforward than in the Euclidean setting. To address this difficulty, we present GeometricKernels, a software package which implements the geometric analogs of classical Euclidean squared exponential - also known as heat - and Mat\'ern kernels, which are widely-used in settings where uncertainty is of key interest. As a byproduct, we obtain the ability to compute Fourier-feature-type expansions, which are widely used in their own right, on a wide set of geometric spaces. Our implementation supports automatic differentiation in every major current framework simultaneously via a backend-agnostic design. In this companion paper to the package and its documentation, we outline the capabilities of the package and present an illustrated example of its interface. We also include a brief overview of the theory the package is built upon and provide some historic context in the appendix.
Cost-aware Bayesian optimization via the Pandora's Box Gittins index
Jun 28, 2024
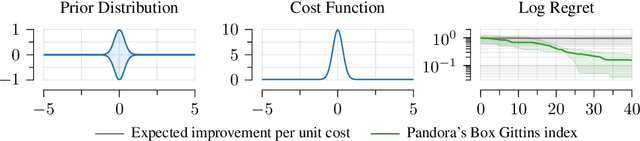
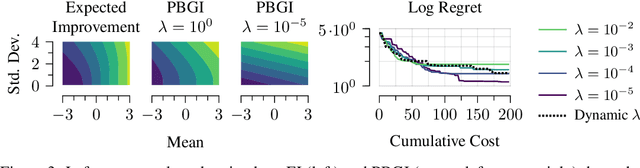
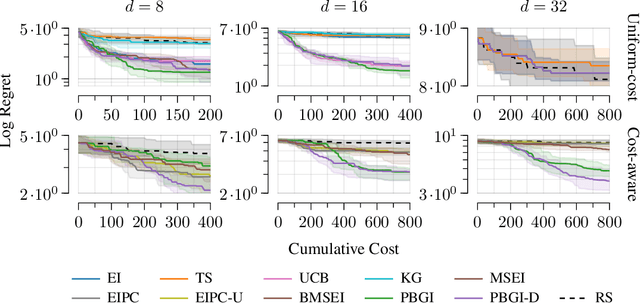
Bayesian optimization is a technique for efficiently optimizing unknown functions in a black-box manner. To handle practical settings where gathering data requires use of finite resources, it is desirable to explicitly incorporate function evaluation costs into Bayesian optimization policies. To understand how to do so, we develop a previously-unexplored connection between cost-aware Bayesian optimization and the Pandora's Box problem, a decision problem from economics. The Pandora's Box problem admits a Bayesian-optimal solution based on an expression called the Gittins index, which can be reinterpreted as an acquisition function. We study the use of this acquisition function for cost-aware Bayesian optimization, and demonstrate empirically that it performs well, particularly in medium-high dimensions. We further show that this performance carries over to classical Bayesian optimization without explicit evaluation costs. Our work constitutes a first step towards integrating techniques from Gittins index theory into Bayesian optimization.
Stochastic Gradient Descent for Gaussian Processes Done Right
Oct 31, 2023



We study the optimisation problem associated with Gaussian process regression using squared loss. The most common approach to this problem is to apply an exact solver, such as conjugate gradient descent, either directly, or to a reduced-order version of the problem. Recently, driven by successes in deep learning, stochastic gradient descent has gained traction as an alternative. In this paper, we show that when done right$\unicode{x2014}$by which we mean using specific insights from the optimisation and kernel communities$\unicode{x2014}$this approach is highly effective. We thus introduce a particular stochastic dual gradient descent algorithm, that may be implemented with a few lines of code using any deep learning framework. We explain our design decisions by illustrating their advantage against alternatives with ablation studies and show that the new method is highly competitive. Our evaluations on standard regression benchmarks and a Bayesian optimisation task set our approach apart from preconditioned conjugate gradients, variational Gaussian process approximations, and a previous version of stochastic gradient descent for Gaussian processes. On a molecular binding affinity prediction task, our method places Gaussian process regression on par in terms of performance with state-of-the-art graph neural networks.
Posterior Contraction Rates for Matérn Gaussian Processes on Riemannian Manifolds
Sep 22, 2023


Gaussian processes are used in many machine learning applications that rely on uncertainty quantification. Recently, computational tools for working with these models in geometric settings, such as when inputs lie on a Riemannian manifold, have been developed. This raises the question: can these intrinsic models be shown theoretically to lead to better performance, compared to simply embedding all relevant quantities into $\mathbb{R}^d$ and using the restriction of an ordinary Euclidean Gaussian process? To study this, we prove optimal contraction rates for intrinsic Mat\'ern Gaussian processes defined on compact Riemannian manifolds. We also prove analogous rates for extrinsic processes using trace and extension theorems between manifold and ambient Sobolev spaces: somewhat surprisingly, the rates obtained turn out to coincide with those of the intrinsic processes, provided that their smoothness parameters are matched appropriately. We illustrate these rates empirically on a number of examples, which, mirroring prior work, show that intrinsic processes can achieve better performance in practice. Therefore, our work shows that finer-grained analyses are needed to distinguish between different levels of data-efficiency of geometric Gaussian processes, particularly in settings which involve small data set sizes and non-asymptotic behavior.
The Cambridge Law Corpus: A Corpus for Legal AI Research
Sep 22, 2023



We introduce the Cambridge Law Corpus (CLC), a corpus for legal AI research. It consists of over 250 000 court cases from the UK. Most cases are from the 21st century, but the corpus includes cases as old as the 16th century. This paper presents the first release of the corpus, containing the raw text and meta-data. Together with the corpus, we provide annotations on case outcomes for 638 cases, done by legal experts. Using our annotated data, we have trained and evaluated case outcome extraction with GPT-3, GPT-4 and RoBERTa models to provide benchmarks. We include an extensive legal and ethical discussion to address the potentially sensitive nature of this material. As a consequence, the corpus will only be released for research purposes under certain restrictions.
A Unifying Variational Framework for Gaussian Process Motion Planning
Sep 02, 2023To control how a robot moves, motion planning algorithms must compute paths in high-dimensional state spaces while accounting for physical constraints related to motors and joints, generating smooth and stable motions, avoiding obstacles, and preventing collisions. A motion planning algorithm must therefore balance competing demands, and should ideally incorporate uncertainty to handle noise, model errors, and facilitate deployment in complex environments. To address these issues, we introduce a framework for robot motion planning based on variational Gaussian Processes, which unifies and generalizes various probabilistic-inference-based motion planning algorithms. Our framework provides a principled and flexible way to incorporate equality-based, inequality-based, and soft motion-planning constraints during end-to-end training, is straightforward to implement, and provides both interval-based and Monte-Carlo-based uncertainty estimates. We conduct experiments using different environments and robots, comparing against baseline approaches based on the feasibility of the planned paths, and obstacle avoidance quality. Results show that our proposed approach yields a good balance between success rates and path quality.