 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguaGame: A Linguistically Grounded Game-Theoretic Paradigm for Multi-Agent Dialogue Generation
Jan 08, 2026Large Language Models (LLMs) have enabled Multi-Agent Systems (MASs) where agents interact through natural language to solve complex tasks or simulate multi-party dialogues. Recent work on LLM-based MASs has mainly focused on architecture design, such as role assignment and workflow orchestration. In contrast, this paper targets the interaction process itself, aiming to improve agents' communication efficiency by helping them convey their intended meaning more effectively through language. To this end, we propose LinguaGame, a linguistically-grounded game-theoretic paradigm for multi-agent dialogue generation. Our approach models dialogue as a signalling game over communicative intents and strategies, solved with a training-free equilibrium approximation algorithm for inference-time decision adjustment. Unlike prior game-theoretic MASs, whose game designs are often tightly coupled with task-specific objectives, our framework relies on linguistically informed reasoning with minimal task-specific coupling. Specifically, it treats dialogue as intentional and strategic communication, requiring agents to infer what others aim to achieve (intents) and how they pursue those goals (strategies). We evaluate our framework in simulated courtroom proceedings and debates, with human expert assessments showing significant gains in communication efficiency.
LexRel: Benchmarking Legal Relation Extraction for Chinese Civil Cases
Dec 14, 2025Legal relations form a highly consequential analytical framework of civil law system, serving as a crucial foundation for resolving disputes and realizing values of the rule of law in judicial practice. However, legal relations in Chinese civil cases remain underexplored in the field of legal artificial intelligence (legal AI), largely due to the absence of comprehensive schemas. In this work, we firstly introduce a comprehensive schema, which contains a hierarchical taxonomy and definitions of arguments, for AI systems to capture legal relations in Chinese civil cases. Based on this schema, we then formulate legal relation extraction task and present LexRel, an expert-annotated benchmark for legal relation extraction in Chinese civil law. We use LexRel to evaluate state-of-the-art large language models (LLMs) on legal relation extractions, showing that current LLMs exhibit significant limitations in accurately identifying civil legal relations. Furthermore, we demonstrate that incorporating legal relations information leads to consistent performance gains on other downstream legal AI tasks.
Legal$Δ$: Enhancing Legal Reasoning in LLMs via Reinforcement Learning with Chain-of-Thought Guided Information Gain
Aug 17, 2025
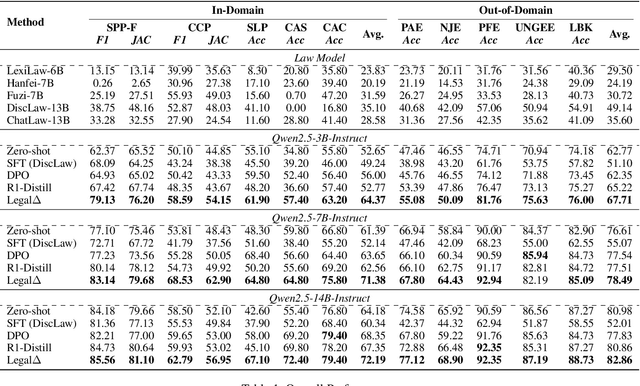

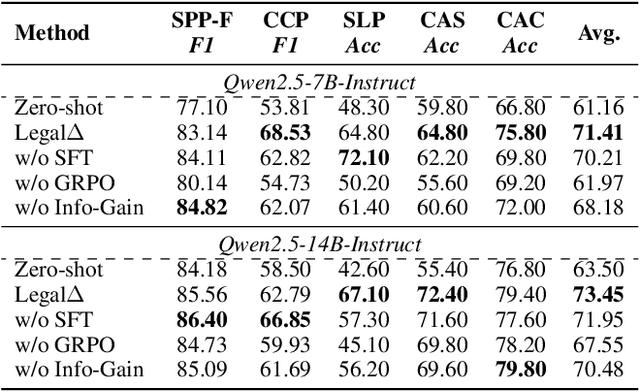
Legal Artificial Intelligence (LegalAI) has achieved notable advances in automating judicial decision-making with the support of Large Language Models (LLMs). However, existing legal LLMs still struggle to generate reliable and interpretable reasoning processes. They often default to fast-thinking behavior by producing direct answers without explicit multi-step reasoning, limiting their effectiveness in complex legal scenarios that demand rigorous justification. To address this challenge, we propose Legal$\Delta$, a reinforcement learning framework designed to enhance legal reasoning through chain-of-thought guided information gain. During training, Legal$\Delta$ employs a dual-mode input setup-comprising direct answer and reasoning-augmented modes-and maximizes the information gain between them. This encourages the model to acquire meaningful reasoning patterns rather than generating superficial or redundant explanations. Legal$\Delta$ follows a two-stage approach: (1) distilling latent reasoning capabilities from a powerful Large Reasoning Model (LRM), DeepSeek-R1, and (2) refining reasoning quality via differential comparisons, combined with a multidimensional reward mechanism that assesses both structural coherence and legal-domain specificity. Experimental results on multiple legal reasoning tasks demonstrate that Legal$\Delta$ outperforms strong baselines in both accuracy and interpretability. It consistently produces more robust and trustworthy legal judgments without relying on labeled preference data. All code and data will be released at https://github.com/NEUIR/LegalDelta.
The CLC-UKET Dataset: Benchmarking Case Outcome Prediction for the UK Employment Tribunal
Sep 12, 2024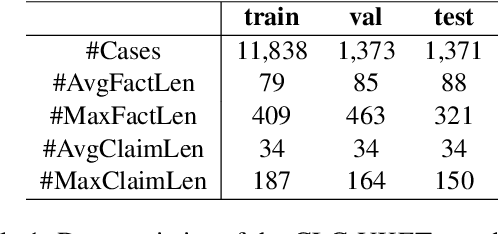
This paper explores the intersection of technological innovation and access to justice by developing a benchmark for predicting case outcomes in the UK Employment Tribunal (UKET). To address the challenge of extensive manual annotation, the study employs a large language model (LLM) for automatic annotation, resulting in the creation of the CLC-UKET dataset. The dataset consists of approximately 19,000 UKET cases and their metadata. Comprehensive legal annotations cover facts, claims, precedent references, statutory references, case outcomes, reasons and jurisdiction codes. Facilitated by the CLC-UKET data, we examine a multi-class case outcome prediction task in the UKET. Human predictions are collected to establish a performance reference for model comparison. Empirical results from baseline models indicate that finetuned transformer models outperform zero-shot and few-shot LLMs on the UKET prediction task. The performance of zero-shot LLMs can be enhanced by integrating task-related information into few-shot examples. We hope that the CLC-UKET dataset, along with human annotations and empirical findings, can serve as a valuable benchmark for employment-related dispute resolution.
Automatic Information Extraction From Employment Tribunal Judgements Using Large Language Models
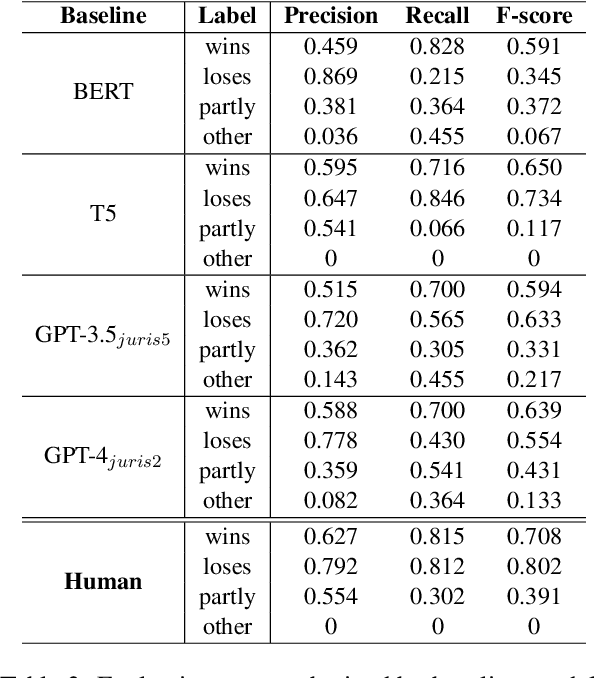
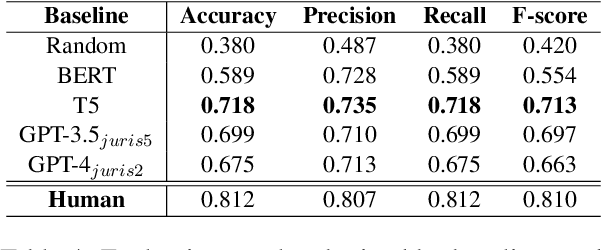
Mar 19, 2024Court transcripts and judgments are rich repositories of legal knowledge, detailing the intricacies of cases and the rationale behind judicial decisions. The extraction of key information from these documents provides a concise overview of a case, crucial for both legal experts and the public. With the advent of large language models (LLMs), automatic information extraction has become increasingly feasible and efficient. This paper presents a comprehensive study on the application of GPT-4, a large language model, for automatic information extraction from UK Employment Tribunal (UKET) cases. We meticulously evaluated GPT-4's performance in extracting critical information with a manual verification process to ensure the accuracy and relevance of the extracted data. Our research is structured around two primary extraction tasks: the first involves a general extraction of eight key aspects that hold significance for both legal specialists and the general public, including the facts of the case, the claims made, references to legal statutes, references to precedents, general case outcomes and corresponding labels, detailed order and remedies and reasons for the decision. The second task is more focused, aimed at analysing three of those extracted features, namely facts, claims and outcomes, in order to facilitate the development of a tool capable of predicting the outcome of employment law disputes. Through our analysis, we demonstrate that LLMs like GPT-4 can obtain high accuracy in legal information extraction, highlighting the potential of LLMs in revolutionising the way legal information is processed and utilised, offering significant implications for legal research and practice.
The Cambridge Law Corpus: A Corpus for Legal AI Research
Sep 22, 2023



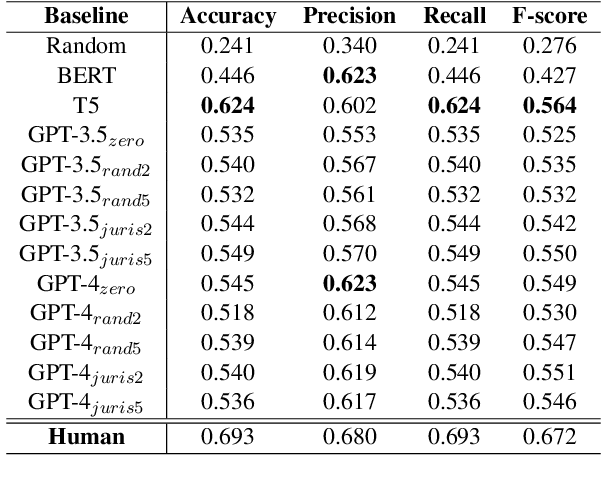
We introduce the Cambridge Law Corpus (CLC), a corpus for legal AI research. It consists of over 250 000 court cases from the UK. Most cases are from the 21st century, but the corpus includes cases as old as the 16th century. This paper presents the first release of the corpus, containing the raw text and meta-data. Together with the corpus, we provide annotations on case outcomes for 638 cases, done by legal experts. Using our annotated data, we have trained and evaluated case outcome extraction with GPT-3, GPT-4 and RoBERTa models to provide benchmarks. We include an extensive legal and ethical discussion to address the potentially sensitive nature of this material. As a consequence, the corpus will only be released for research purposes under certain restrictions.
TIAGE: A Benchmark for Topic-Shift Aware Dialog Modeling
Sep 09, 2021



Human conversations naturally evolve around different topics and fluently move between them. In research on dialog systems, the ability to actively and smoothly transition to new topics is often ignored. In this paper we introduce TIAGE, a new topic-shift aware dialog benchmark constructed utilizing human annotations on topic shifts. Based on TIAGE, we introduce three tasks to investigate different scenarios of topic-shift modeling in dialog settings: topic-shift detection, topic-shift triggered response generation and topic-aware dialog generation. Experiments on these tasks show that the topic-shift signals in TIAGE are useful for topic-shift response generation. On the other hand, dialog systems still struggle to decide when to change topic. This indicates further research is needed in topic-shift aware dialog modeling.
Going Beneath the Surface: Evaluating Image Captioning for Grammaticality, Truthfulness and Diversity
Dec 19, 2019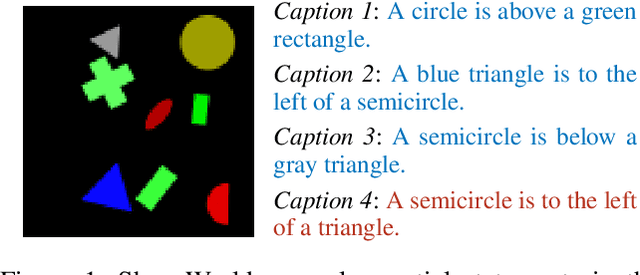
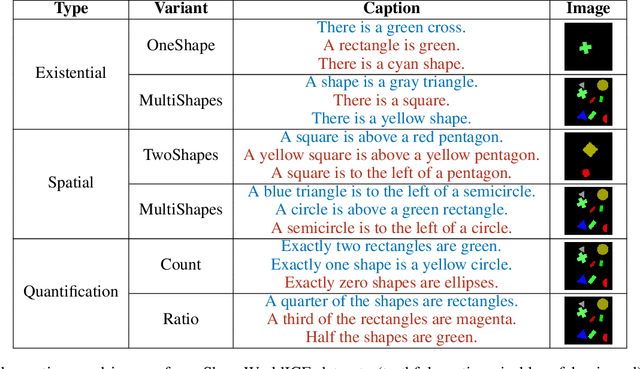
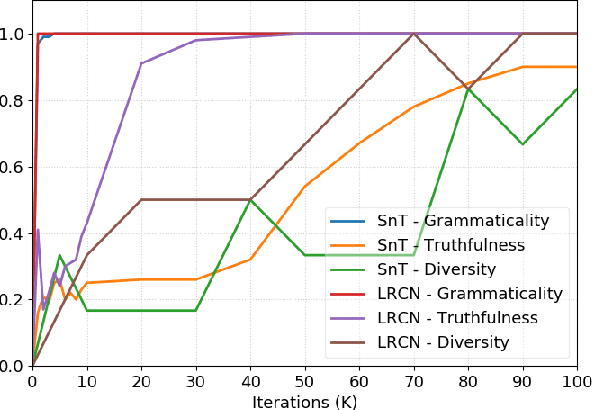
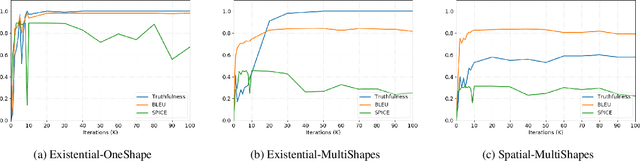
Image captioning as a multimodal task has drawn much interest in recent years. However, evaluation for this task remains a challenging problem. Existing evaluation metrics focus on surface similarity between a candidate caption and a set of reference captions, and do not check the actual relation between a caption and the underlying visual content. We introduce a new diagnostic evaluation framework for the task of image captioning, with the goal of directly assessing models for grammaticality, truthfulness and diversity (GTD) of generated captions. We demonstrate the potential of our evaluation framework by evaluating existing image captioning models on a wide ranging set of synthetic datasets that we construct for diagnostic evaluation. We empirically show how the GTD evaluation framework, in combination with diagnostic datasets, can provide insights into model capabilities and limitations to supplement standard evaluations.
How clever is the FiLM model, and how clever can it be?
Sep 09, 2018
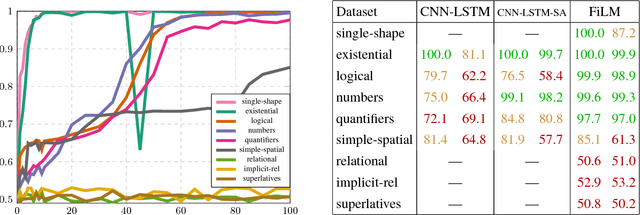
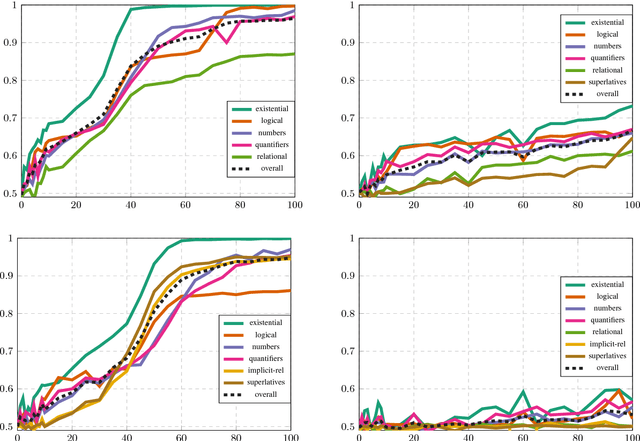
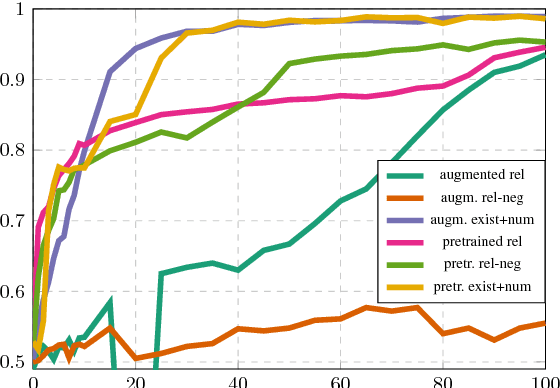
The FiLM model achieves close-to-perfect performance on the diagnostic CLEVR dataset and is distinguished from other such models by having a comparatively simple and easily transferable architecture. In this paper, we investigate in more detail the ability of FiLM to learn various linguistic constructions. Our main results show that (a) FiLM is not able to learn relational statements straight away except for very simple instances, (b) training on a broader set of instances as well as pretraining on simpler instance types can help alleviate these learning difficulties, (c) mixing is less robust than pretraining and very sensitive to the compositional structure of the dataset. Overall, our results suggest that the approach of big all-encompassing datasets and the paradigm of "the effectiveness of data" may have fundamental limitations.