 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow clever is the FiLM model, and how clever can it be?
Paper and Code
Sep 09, 2018
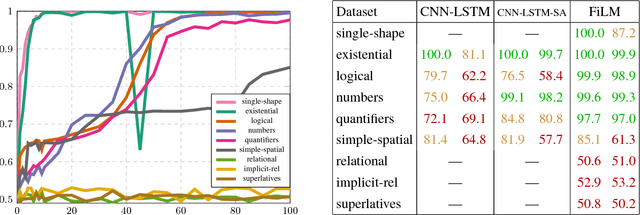
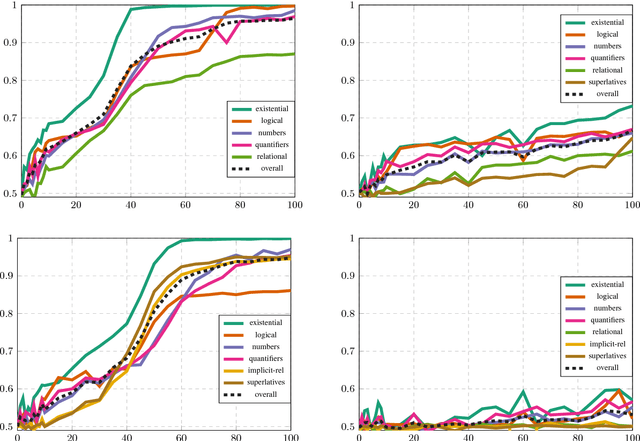
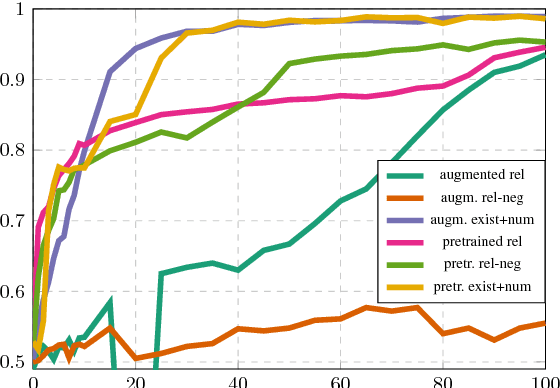
The FiLM model achieves close-to-perfect performance on the diagnostic CLEVR dataset and is distinguished from other such models by having a comparatively simple and easily transferable architecture. In this paper, we investigate in more detail the ability of FiLM to learn various linguistic constructions. Our main results show that (a) FiLM is not able to learn relational statements straight away except for very simple instances, (b) training on a broader set of instances as well as pretraining on simpler instance types can help alleviate these learning difficulties, (c) mixing is less robust than pretraining and very sensitive to the compositional structure of the dataset. Overall, our results suggest that the approach of big all-encompassing datasets and the paradigm of "the effectiveness of data" may have fundamental limitations.