 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Modal Embeddings from Structured Data
Oct 06, 2021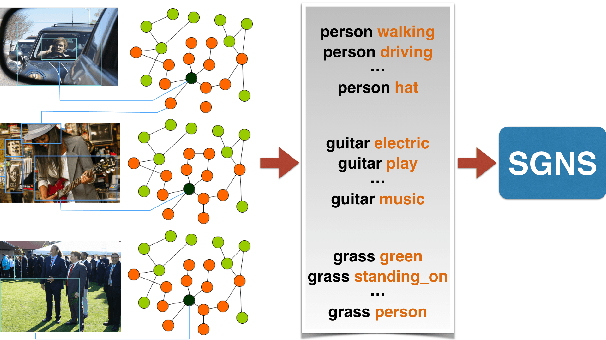

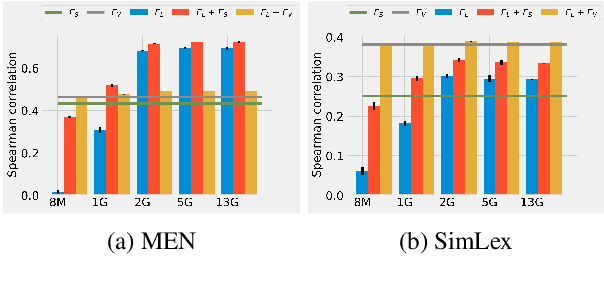
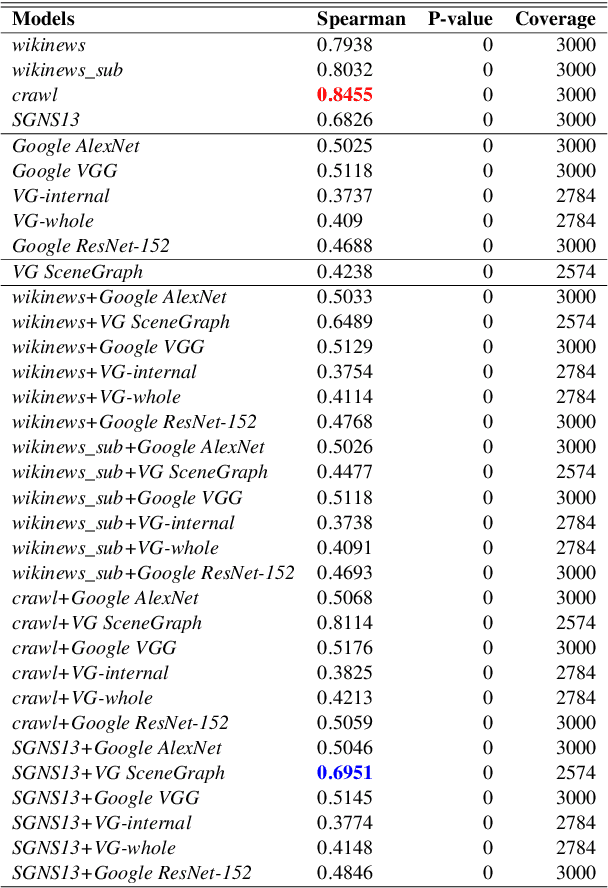
Multi-modal word semantics aims to enhance embeddings with perceptual input, assuming that human meaning representation is grounded in sensory experience. Most research focuses on evaluation involving direct visual input, however, visual grounding can contribute to linguistic applications as well. Another motivation for this paper is the growing need for more interpretable models and for evaluating model efficiency regarding size and performance. This work explores the impact of visual information for semantics when the evaluation involves no direct visual input, specifically semantic similarity and relatedness. We investigate a new embedding type in-between linguistic and visual modalities, based on the structured annotations of Visual Genome. We compare uni- and multi-modal models including structured, linguistic and image based representations. We measure the efficiency of each model with regard to data and model size, modality / data distribution and information gain. The analysis includes an interpretation of embedding structures. We found that this new embedding conveys complementary information for text based embeddings. It achieves comparable performance in an economic way, using orders of magnitude less resources than visual models.
TIAGE: A Benchmark for Topic-Shift Aware Dialog Modeling
Sep 09, 2021



Human conversations naturally evolve around different topics and fluently move between them. In research on dialog systems, the ability to actively and smoothly transition to new topics is often ignored. In this paper we introduce TIAGE, a new topic-shift aware dialog benchmark constructed utilizing human annotations on topic shifts. Based on TIAGE, we introduce three tasks to investigate different scenarios of topic-shift modeling in dialog settings: topic-shift detection, topic-shift triggered response generation and topic-aware dialog generation. Experiments on these tasks show that the topic-shift signals in TIAGE are useful for topic-shift response generation. On the other hand, dialog systems still struggle to decide when to change topic. This indicates further research is needed in topic-shift aware dialog modeling.
Morphologically Aware Word-Level Translation
Nov 15, 2020

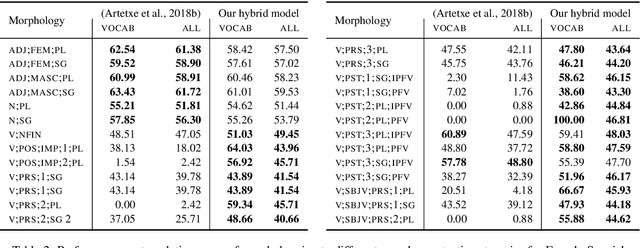

We propose a novel morphologically aware probability model for bilingual lexicon induction, which jointly models lexeme translation and inflectional morphology in a structured way. Our model exploits the basic linguistic intuition that the lexeme is the key lexical unit of meaning, while inflectional morphology provides additional syntactic information. This approach leads to substantial performance improvements - 19% average improvement in accuracy across 6 language pairs over the state of the art in the supervised setting and 16% in the weakly supervised setting. As another contribution, we highlight issues associated with modern BLI that stem from ignoring inflectional morphology, and propose three suggestions for improving the task.
Going Beneath the Surface: Evaluating Image Captioning for Grammaticality, Truthfulness and Diversity
Dec 19, 2019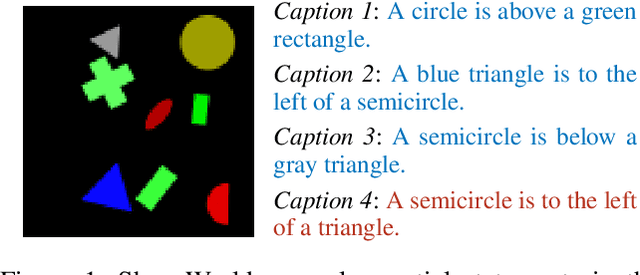
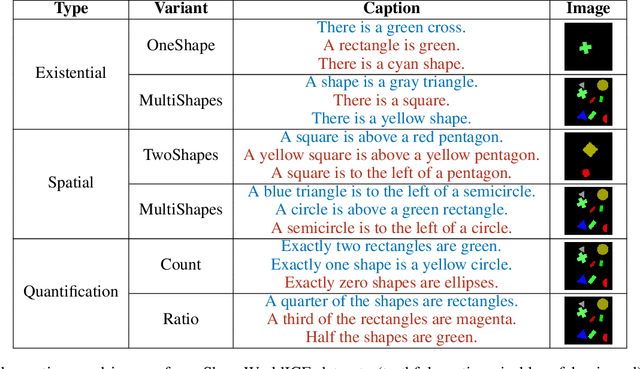
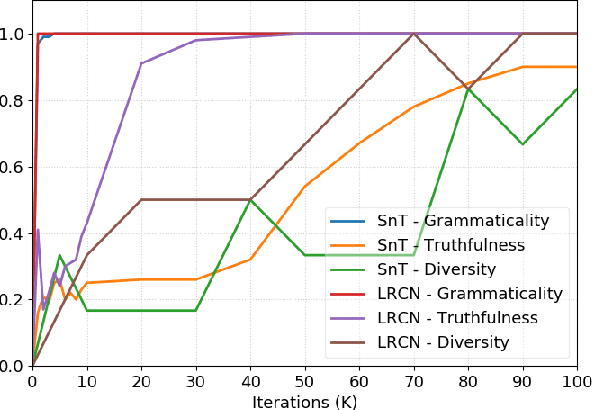
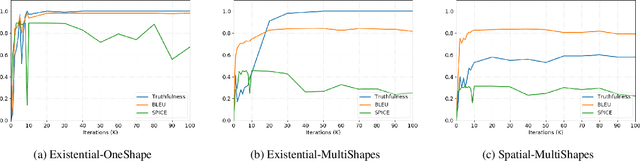
Image captioning as a multimodal task has drawn much interest in recent years. However, evaluation for this task remains a challenging problem. Existing evaluation metrics focus on surface similarity between a candidate caption and a set of reference captions, and do not check the actual relation between a caption and the underlying visual content. We introduce a new diagnostic evaluation framework for the task of image captioning, with the goal of directly assessing models for grammaticality, truthfulness and diversity (GTD) of generated captions. We demonstrate the potential of our evaluation framework by evaluating existing image captioning models on a wide ranging set of synthetic datasets that we construct for diagnostic evaluation. We empirically show how the GTD evaluation framework, in combination with diagnostic datasets, can provide insights into model capabilities and limitations to supplement standard evaluations.
Don't Forget the Long Tail! A Comprehensive Analysis of Morphological Generalization in Bilingual Lexicon Induction
Sep 06, 2019


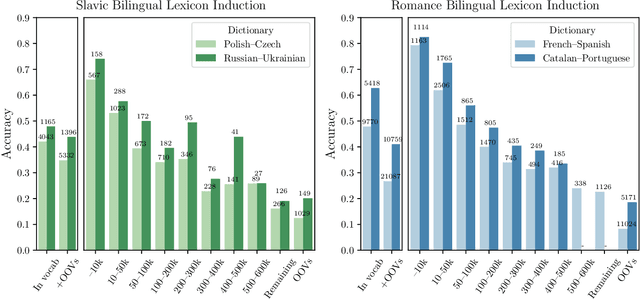
Human translators routinely have to translate rare inflections of words - due to the Zipfian distribution of words in a language. When translating from Spanish, a good translator would have no problem identifying the proper translation of a statistically rare inflection such as habl\'aramos. Note the lexeme itself, hablar, is relatively common. In this work, we investigate whether state-of-the-art bilingual lexicon inducers are capable of learning this kind of generalization. We introduce 40 morphologically complete dictionaries in 10 languages and evaluate three of the state-of-the-art models on the task of translation of less frequent morphological forms. We demonstrate that the performance of state-of-the-art models drops considerably when evaluated on infrequent morphological inflections and then show that adding a simple morphological constraint at training time improves the performance, proving that the bilingual lexicon inducers can benefit from better encoding of morphology.
What is needed for simple spatial language capabilities in VQA?
Aug 17, 2019
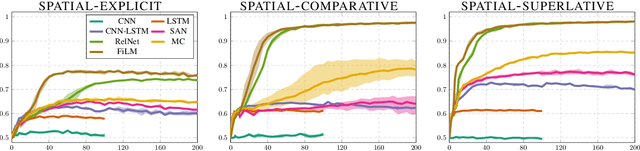
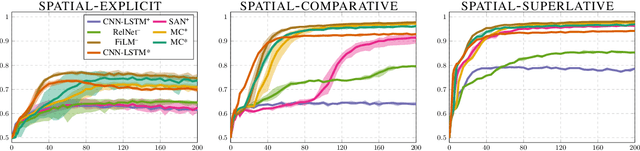
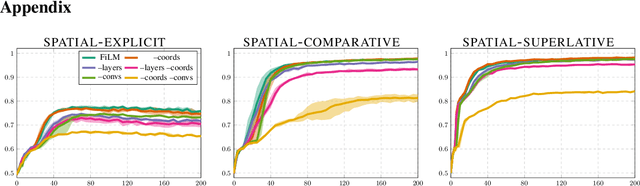
Visual question answering (VQA) comprises a variety of language capabilities. The diagnostic benchmark dataset CLEVR has fueled progress by helping to better assess and distinguish models in basic abilities like counting, comparing and spatial reasoning in vitro. Following this approach, we focus on spatial language capabilities and investigate the question: what are the key ingredients to handle simple visual-spatial relations? We look at the SAN, RelNet, FiLM and MC models and evaluate their learning behavior on diagnostic data which is solely focused on spatial relations. Via comparative analysis and targeted model modification we identify what really is required to substantially improve upon the CNN-LSTM baseline.
The meaning of "most" for visual question answering models
Dec 31, 2018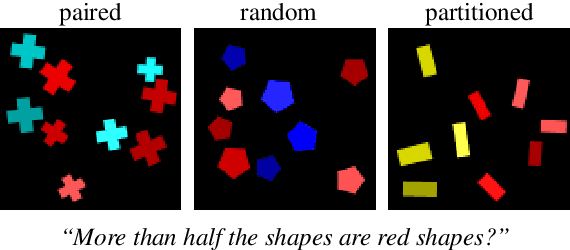


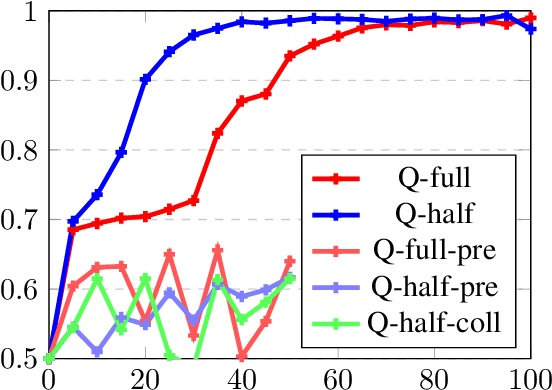
The correct interpretation of quantifier statements in the context of a visual scene requires non-trivial inference mechanisms. For the example of "most", we discuss two strategies which rely on fundamentally different cognitive concepts. Our aim is to identify what strategy deep learning models for visual question answering learn when trained on such questions. To this end, we carefully design data to replicate experiments from psycholinguistics where the same question was investigated for humans. Focusing on the FiLM visual question answering model, our experiments indicate that a form of approximate number system emerges whose performance declines with more difficult scenes as predicted by Weber's law. Moreover, we identify confounding factors, like spatial arrangement of the scene, which impede the effectiveness of this system.
How clever is the FiLM model, and how clever can it be?
Sep 09, 2018
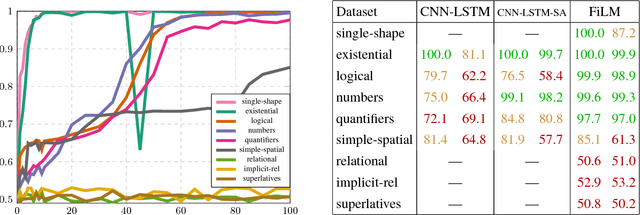
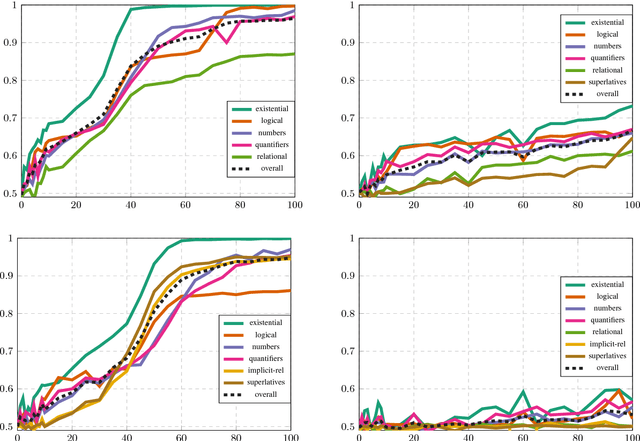
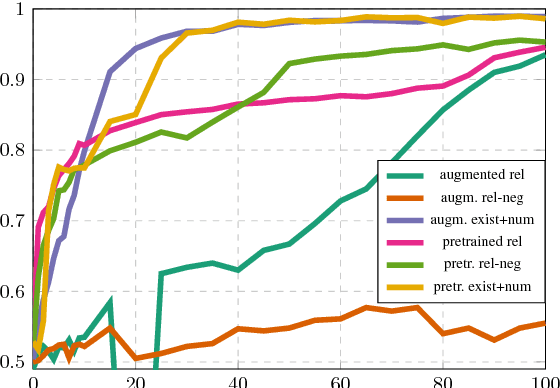
The FiLM model achieves close-to-perfect performance on the diagnostic CLEVR dataset and is distinguished from other such models by having a comparatively simple and easily transferable architecture. In this paper, we investigate in more detail the ability of FiLM to learn various linguistic constructions. Our main results show that (a) FiLM is not able to learn relational statements straight away except for very simple instances, (b) training on a broader set of instances as well as pretraining on simpler instance types can help alleviate these learning difficulties, (c) mixing is less robust than pretraining and very sensitive to the compositional structure of the dataset. Overall, our results suggest that the approach of big all-encompassing datasets and the paradigm of "the effectiveness of data" may have fundamental limitations.
Deep learning evaluation using deep linguistic processing
May 12, 2018

We discuss problems with the standard approaches to evaluation for tasks like visual question answering, and argue that artificial data can be used to address these as a complement to current practice. We demonstrate that with the help of existing 'deep' linguistic processing technology we are able to create challenging abstract datasets, which enable us to investigate the language understanding abilities of multimodal deep learning models in detail, as compared to a single performance value on a static and monolithic dataset.
Functional Distributional Semantics
Jun 26, 2016



Vector space models have become popular in distributional semantics, despite the challenges they face in capturing various semantic phenomena. We propose a novel probabilistic framework which draws on both formal semantics and recent advances in machine learning. In particular, we separate predicates from the entities they refer to, allowing us to perform Bayesian inference based on logical forms. We describe an implementation of this framework using a combination of Restricted Boltzmann Machines and feedforward neural networks. Finally, we demonstrate the feasibility of this approach by training it on a parsed corpus and evaluating it on established similarity datasets.