 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Inclusion Hypothesis and Quantifications: Probing Hypernymy in Functional Distributional Semantics
Sep 15, 2023Functional Distributional Semantics (FDS) models the meaning of words by truth-conditional functions. This provides a natural representation for hypernymy, but no guarantee that it is learnt when FDS models are trained on a corpus. We demonstrate that FDS models learn hypernymy when a corpus strictly follows the Distributional Inclusion Hypothesis. We further introduce a training objective that allows FDS to handle simple universal quantifications, thus enabling hypernymy learning under the reverse of DIH. Experimental results on both synthetic and real data sets confirm our hypotheses and the effectiveness of our proposed objective.
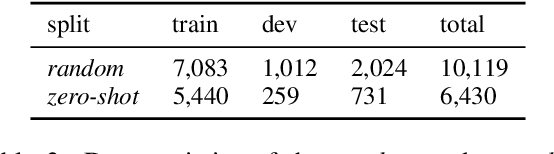
Using dependency parsing for few-shot learning in distributional semantics
May 12, 2022
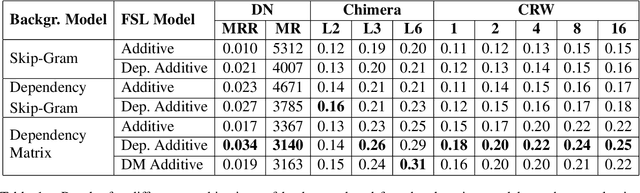
In this work, we explore the novel idea of employing dependency parsing information in the context of few-shot learning, the task of learning the meaning of a rare word based on a limited amount of context sentences. Firstly, we use dependency-based word embedding models as background spaces for few-shot learning. Secondly, we introduce two few-shot learning methods which enhance the additive baseline model by using dependencies.
Visual Spatial Reasoning
Apr 30, 2022


Spatial relations are fundamental to human cognition and are the most basic knowledge for us to understand and communicate about our physical surroundings. In this paper, we ask the critical question: Are current vision-and-language models (VLMs) able to correctly understand spatial relations? To answer this question, we propose Visual Spatial Reasoning (VSR), a novel benchmark task with human labelled dataset for investigating VLMs' capabilities in recognising 65 types of spatial relationships (e.g., under, in front of, facing etc.) in natural text-image pairs. Specifically, given a caption and an image, the model needs to perform binary classification and decide if the caption accurately describes the spatial relationships of two objects presented in the image. While being seemingly simple and straightforward, the task shows a large gap between human and model performance (human ceiling on the VSR task is above 95% and models only achieve around 70%). With fine-grained categorisation and control on both concepts and relations, our VSR benchmark enables us to perform interesting probing analysis to pinpoint VLMs' failure cases and the reasons behind. We observe that VLMs' by-relation performances have little correlation with the number of training examples and the tested models are in general incapable of recognising relations that concern orientations of objects. Also, VLMs have poor zero-shot generalisation toward unseen concepts. The dataset and code are released at github.com/cambridgeltl/visual-spatial-reasoning.
Learning Functional Distributional Semantics with Visual Data
Apr 22, 2022
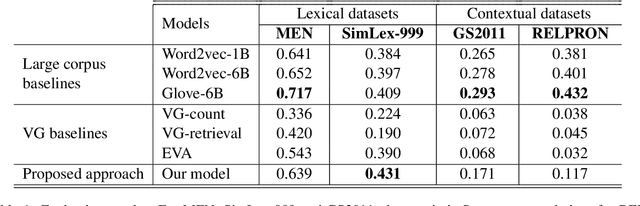
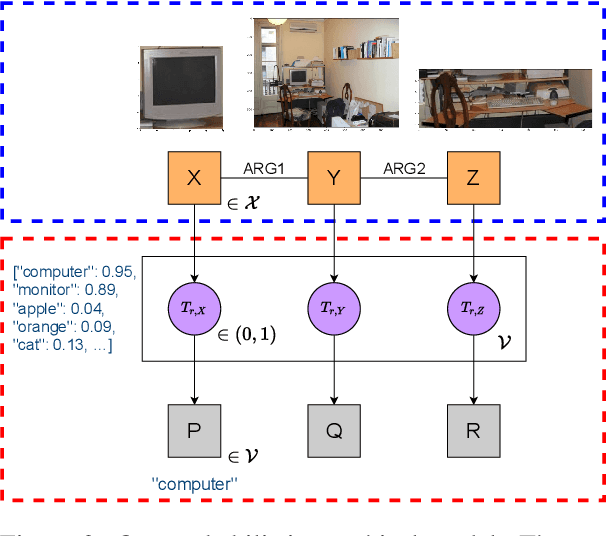
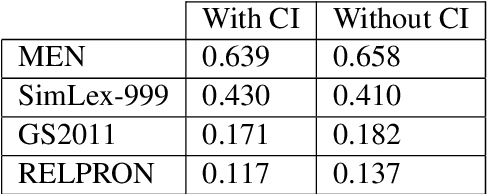
Functional Distributional Semantics is a recently proposed framework for learning distributional semantics that provides linguistic interpretability. It models the meaning of a word as a binary classifier rather than a numerical vector. In this work, we propose a method to train a Functional Distributional Semantics model with grounded visual data. We train it on the Visual Genome dataset, which is closer to the kind of data encountered in human language acquisition than a large text corpus. On four external evaluation datasets, our model outperforms previous work on learning semantics from Visual Genome.
Incremental Beam Manipulation for Natural Language Generation
Feb 10, 2021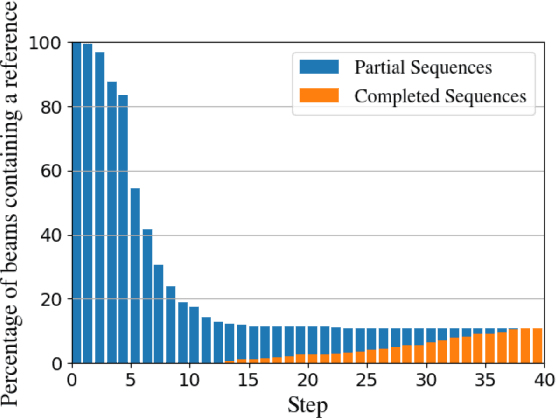
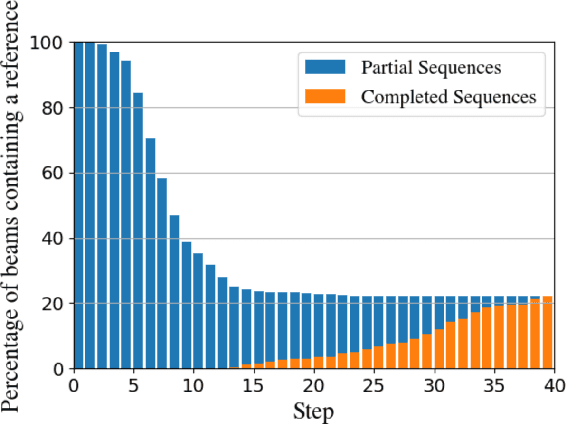
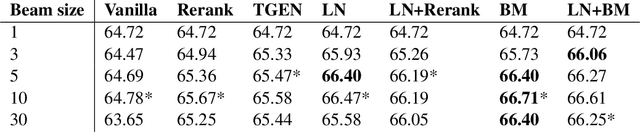

The performance of natural language generation systems has improved substantially with modern neural networks. At test time they typically employ beam search to avoid locally optimal but globally suboptimal predictions. However, due to model errors, a larger beam size can lead to deteriorating performance according to the evaluation metric. For this reason, it is common to rerank the output of beam search, but this relies on beam search to produce a good set of hypotheses, which limits the potential gains. Other alternatives to beam search require changes to the training of the model, which restricts their applicability compared to beam search. This paper proposes incremental beam manipulation, i.e. reranking the hypotheses in the beam during decoding instead of only at the end. This way, hypotheses that are unlikely to lead to a good final output are discarded, and in their place hypotheses that would have been ignored will be considered instead. Applying incremental beam manipulation leads to an improvement of 1.93 and 5.82 BLEU points over vanilla beam search for the test sets of the E2E and WebNLG challenges respectively. The proposed method also outperformed a strong reranker by 1.04 BLEU points on the E2E challenge, while being on par with it on the WebNLG dataset.
Investigating Cross-Linguistic Adjective Ordering Tendencies with a Latent-Variable Model
Oct 09, 2020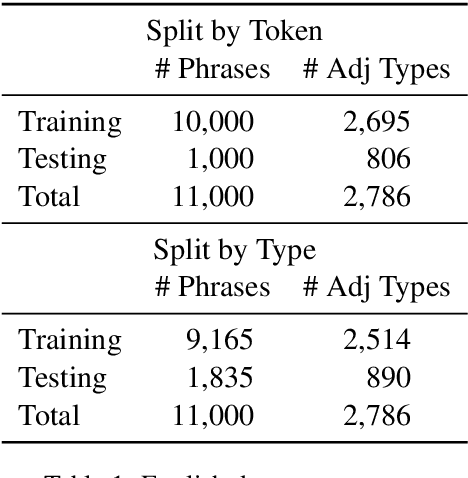
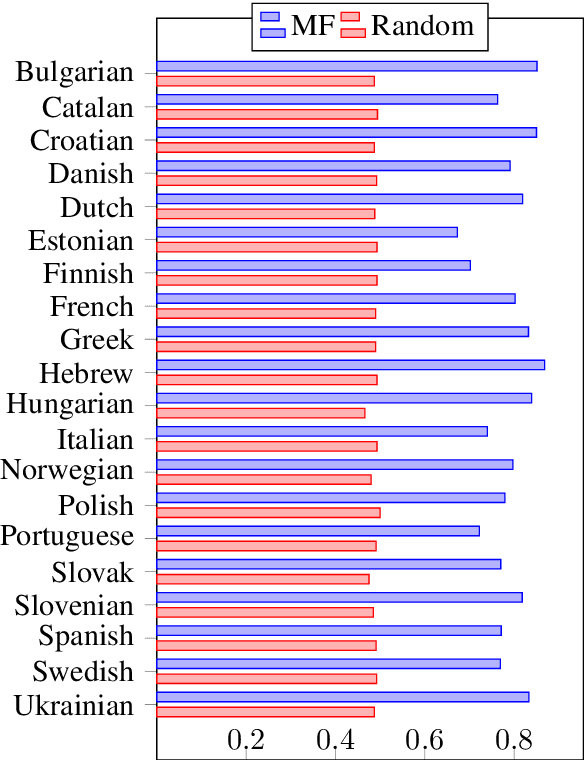
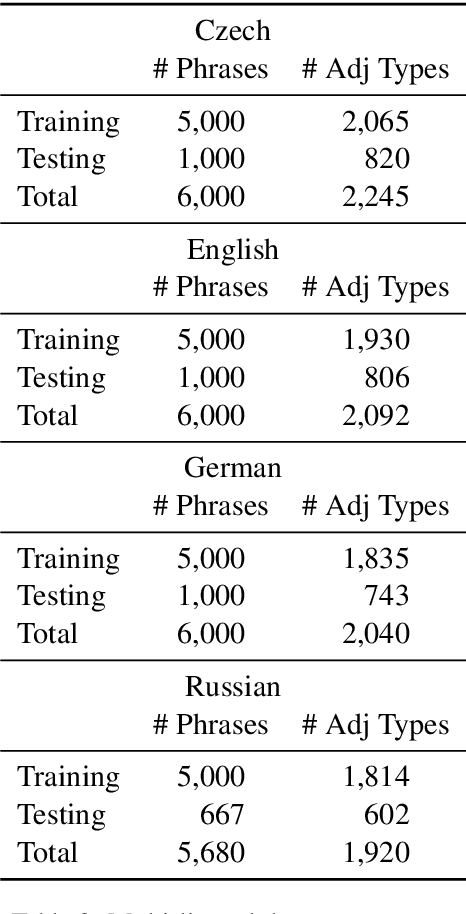
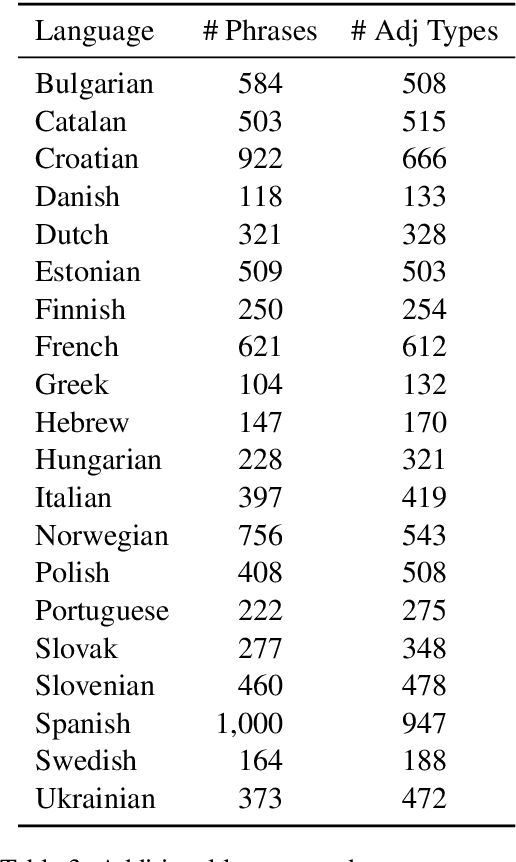
Across languages, multiple consecutive adjectives modifying a noun (e.g. "the big red dog") follow certain unmarked ordering rules. While explanatory accounts have been put forward, much of the work done in this area has relied primarily on the intuitive judgment of native speakers, rather than on corpus data. We present the first purely corpus-driven model of multi-lingual adjective ordering in the form of a latent-variable model that can accurately order adjectives across 24 different languages, even when the training and testing languages are different. We utilize this novel statistical model to provide strong converging evidence for the existence of universal, cross-linguistic, hierarchical adjective ordering tendencies.
Linguists Who Use Probabilistic Models Love Them: Quantification in Functional Distributional Semantics
Jun 04, 2020
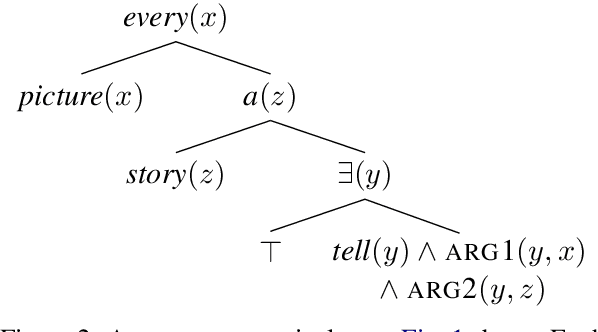


Functional Distributional Semantics provides a computationally tractable framework for learning truth-conditional semantics from a corpus. Previous work in this framework has provided a probabilistic version of first-order logic, recasting quantification as Bayesian inference. In this paper, I show how the previous formulation gives trivial truth values when a precise quantifier is used with vague predicates. I propose an improved account, avoiding this problem by treating a vague predicate as a distribution over precise predicates. I connect this account to recent work in the Rational Speech Acts framework on modelling generic quantification, and I extend this to modelling donkey sentences. Finally, I explain how the generic quantifier can be both pragmatically complex and yet computationally simpler than precise quantifiers.
Autoencoding Pixies: Amortised Variational Inference with Graph Convolutions for Functional Distributional Semantics
May 10, 2020

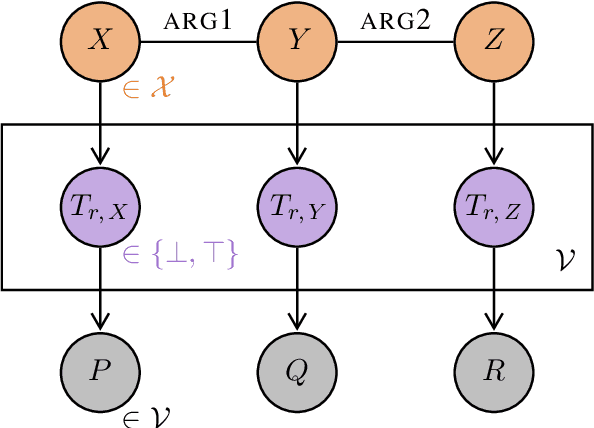

Functional Distributional Semantics provides a linguistically interpretable framework for distributional semantics, by representing the meaning of a word as a function (a binary classifier), instead of a vector. However, the large number of latent variables means that inference is computationally expensive, and training a model is therefore slow to converge. In this paper, I introduce the Pixie Autoencoder, which augments the generative model of Functional Distributional Semantics with a graph-convolutional neural network to perform amortised variational inference. This allows the model to be trained more effectively, achieving better results on two tasks (semantic similarity in context and semantic composition), and outperforming BERT, a large pre-trained language model.
What are the Goals of Distributional Semantics?
May 06, 2020Distributional semantic models have become a mainstay in NLP, providing useful features for downstream tasks. However, assessing long-term progress requires explicit long-term goals. In this paper, I take a broad linguistic perspective, looking at how well current models can deal with various semantic challenges. Given stark differences between models proposed in different subfields, a broad perspective is needed to see how we could integrate them. I conclude that, while linguistic insights can guide the design of model architectures, future progress will require balancing the often conflicting demands of linguistic expressiveness and computational tractability.
Bad Form: Comparing Context-Based and Form-Based Few-Shot Learning in Distributional Semantic Models
Oct 01, 2019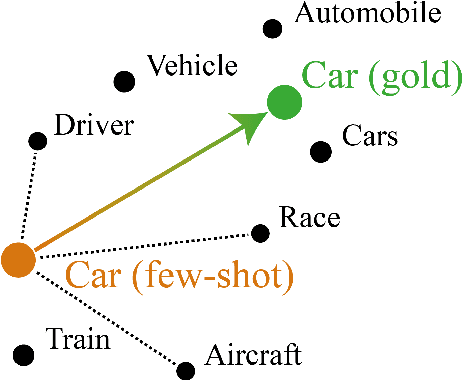

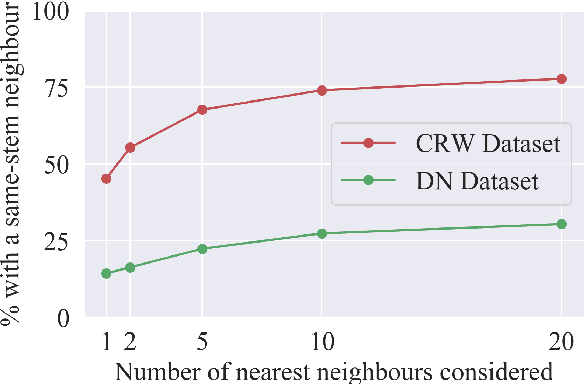
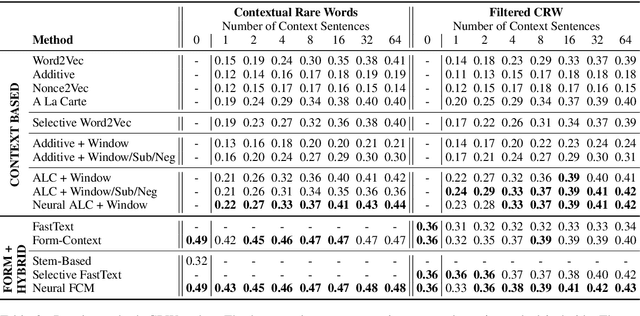
Word embeddings are an essential component in a wide range of natural language processing applications. However, distributional semantic models are known to struggle when only a small number of context sentences are available. Several methods have been proposed to obtain higher-quality vectors for these words, leveraging both this context information and sometimes the word forms themselves through a hybrid approach. We show that the current tasks do not suffice to evaluate models that use word-form information, as such models can easily leverage word forms in the training data that are related to word forms in the test data. We introduce 3 new tasks, allowing for a more balanced comparison between models. Furthermore, we show that hyperparameters that have largely been ignored in previous work can consistently improve the performance of both baseline and advanced models, achieving a new state of the art on 4 out of 6 tasks.