 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Spatial Reasoning
Paper and Code



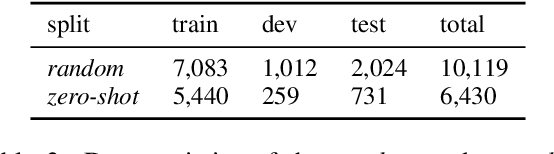
Spatial relations are fundamental to human cognition and are the most basic knowledge for us to understand and communicate about our physical surroundings. In this paper, we ask the critical question: Are current vision-and-language models (VLMs) able to correctly understand spatial relations? To answer this question, we propose Visual Spatial Reasoning (VSR), a novel benchmark task with human labelled dataset for investigating VLMs' capabilities in recognising 65 types of spatial relationships (e.g., under, in front of, facing etc.) in natural text-image pairs. Specifically, given a caption and an image, the model needs to perform binary classification and decide if the caption accurately describes the spatial relationships of two objects presented in the image. While being seemingly simple and straightforward, the task shows a large gap between human and model performance (human ceiling on the VSR task is above 95% and models only achieve around 70%). With fine-grained categorisation and control on both concepts and relations, our VSR benchmark enables us to perform interesting probing analysis to pinpoint VLMs' failure cases and the reasons behind. We observe that VLMs' by-relation performances have little correlation with the number of training examples and the tested models are in general incapable of recognising relations that concern orientations of objects. Also, VLMs have poor zero-shot generalisation toward unseen concepts. The dataset and code are released at github.com/cambridgeltl/visual-spatial-reasoning.