 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident Rankings with Fewer Items: Adaptive LLM Evaluation with Continuous Scores
Jan 20, 2026Computerized Adaptive Testing (CAT) has proven effective for efficient LLM evaluation on multiple-choice benchmarks, but modern LLM evaluation increasingly relies on generation tasks where outputs are scored continuously rather than marked correct/incorrect. We present a principled extension of IRT-based adaptive testing to continuous bounded scores (ROUGE, BLEU, LLM-as-a-Judge) by replacing the Bernoulli response distribution with a heteroskedastic normal distribution. Building on this, we introduce an uncertainty aware ranker with adaptive stopping criteria that achieves reliable model ranking while testing as few items and as cheaply as possible. We validate our method on five benchmarks spanning n-gram-based, embedding-based, and LLM-as-judge metrics. Our method uses 2% of the items while improving ranking correlation by 0.12 τ over random sampling, with 95% accuracy on confident predictions.
Failure Modes in Multi-Hop QA: The Weakest Link Law and the Recognition Bottleneck
Jan 18, 2026Despite scaling to massive context windows, Large Language Models (LLMs) struggle with multi-hop reasoning due to inherent position bias, which causes them to overlook information at certain positions. Whether these failures stem from an inability to locate evidence (recognition failure) or integrate it (synthesis failure) is unclear. We introduce Multi-Focus Attention Instruction (MFAI), a semantic probe to disentangle these mechanisms by explicitly steering attention towards selected positions. Across 5 LLMs on two multi-hop QA tasks (MuSiQue and NeoQA), we establish the "Weakest Link Law": multi-hop reasoning performance collapses to the performance level of the least visible evidence. Crucially, this failure is governed by absolute position rather than the linear distance between facts (performance variance $<3%$). We further identify a duality in attention steering: while matched MFAI resolves recognition bottlenecks, improving accuracy by up to 11.5% in low-visibility positions, misleading MFAI triggers confusion in real-world tasks but is successfully filtered in synthetic tasks. Finally, we demonstrate that "thinking" models that utilize System-2 reasoning, effectively locate and integrate the required information, matching gold-only baselines even in noisy, long-context settings.
Steer Model beyond Assistant: Controlling System Prompt Strength via Contrastive Decoding
Jan 10, 2026Large language models excel at complex instructions yet struggle to deviate from their helpful assistant persona, as post-training instills strong priors that resist conflicting instructions. We introduce system prompt strength, a training-free method that treats prompt adherence as a continuous control. By contrasting logits from target and default system prompts, we isolate and amplify the behavioral signal unique to the target persona by a scalar factor alpha. Across five diverse benchmarks spanning constraint satisfaction, behavioral control, pluralistic alignment, capability modulation, and stylistic control, our method yields substantial improvements: up to +8.5 strict accuracy on IFEval, +45pp refusal rate on OffTopicEval, and +13% steerability on Prompt-Steering. Our approach enables practitioners to modulate system prompt strength, providing dynamic control over model behavior without retraining.
Value of Information: A Framework for Human-Agent Communication
Jan 10, 2026Large Language Model (LLM) agents deployed for real-world tasks face a fundamental dilemma: user requests are underspecified, yet agents must decide whether to act on incomplete information or interrupt users for clarification. Existing approaches either rely on brittle confidence thresholds that require task-specific tuning, or fail to account for the varying stakes of different decisions. We introduce a decision-theoretic framework that resolves this trade-off through the Value of Information (VoI), enabling agents to dynamically weigh the expected utility gain from asking questions against the cognitive cost imposed on users. Our inference-time method requires no hyperparameter tuning and adapts seamlessly across contexts-from casual games to medical diagnosis. Experiments across four diverse domains (20 Questions, medical diagnosis, flight booking, and e-commerce) show that VoI consistently matches or exceeds the best manually-tuned baselines, achieving up to 1.36 utility points higher in high-cost settings. This work provides a parameter-free framework for adaptive agent communication that explicitly balances task risk, query ambiguity, and user effort.
Confidence Estimation for LLMs in Multi-turn Interactions
Jan 05, 2026While confidence estimation is a promising direction for mitigating hallucinations in Large Language Models (LLMs), current research dominantly focuses on single-turn settings. The dynamics of model confidence in multi-turn conversations, where context accumulates and ambiguity is progressively resolved, remain largely unexplored. Reliable confidence estimation in multi-turn settings is critical for many downstream applications, such as autonomous agents and human-in-the-loop systems. This work presents the first systematic study of confidence estimation in multi-turn interactions, establishing a formal evaluation framework grounded in two key desiderata: per-turn calibration and monotonicity of confidence as more information becomes available. To facilitate this, we introduce novel metrics, including a length-normalized Expected Calibration Error (InfoECE), and a new "Hinter-Guesser" paradigm for generating controlled evaluation datasets. Our experiments reveal that widely-used confidence techniques struggle with calibration and monotonicity in multi-turn dialogues. We propose P(Sufficient), a logit-based probe that achieves comparatively better performance, although the task remains far from solved. Our work provides a foundational methodology for developing more reliable and trustworthy conversational agents.
All Roads Lead to Rome: Graph-Based Confidence Estimation for Large Language Model Reasoning
Sep 16, 2025Confidence estimation is essential for the reliable deployment of large language models (LLMs). Existing methods are primarily designed for factual QA tasks and often fail to generalize to reasoning tasks. To address this gap, we propose a set of training-free, graph-based confidence estimation methods tailored to reasoning tasks. Our approach models reasoning paths as directed graphs and estimates confidence by exploiting graph properties such as centrality, path convergence, and path weighting. Experiments with two LLMs on three reasoning datasets demonstrate improved confidence estimation and enhanced performance on two downstream tasks.
A Survey on Prompt Tuning
Jul 09, 2025This survey reviews prompt tuning, a parameter-efficient approach for adapting language models by prepending trainable continuous vectors while keeping the model frozen. We classify existing approaches into two categories: direct prompt learning and transfer learning. Direct prompt learning methods include: general optimization approaches, encoder-based methods, decomposition strategies, and mixture-of-experts frameworks. Transfer learning methods consist of: general transfer approaches, encoder-based methods, and decomposition strategies. For each method, we analyze method designs, innovations, insights, advantages, and disadvantages, with illustrative visualizations comparing different frameworks. We identify challenges in computational efficiency and training stability, and discuss future directions in improving training robustness and broadening application scope.
Reinforcement Learning for Better Verbalized Confidence in Long-Form Generation
May 29, 2025



Hallucination remains a major challenge for the safe and trustworthy deployment of large language models (LLMs) in factual content generation. Prior work has explored confidence estimation as an effective approach to hallucination detection, but often relies on post-hoc self-consistency methods that require computationally expensive sampling. Verbalized confidence offers a more efficient alternative, but existing approaches are largely limited to short-form question answering (QA) tasks and do not generalize well to open-ended generation. In this paper, we propose LoVeC (Long-form Verbalized Confidence), an on-the-fly verbalized confidence estimation method for long-form generation. Specifically, we use reinforcement learning (RL) to train LLMs to append numerical confidence scores to each generated statement, serving as a direct and interpretable signal of the factuality of generation. Our experiments consider both on-policy and off-policy RL methods, including DPO, ORPO, and GRPO, to enhance the model calibration. We introduce two novel evaluation settings, free-form tagging and iterative tagging, to assess different verbalized confidence estimation methods. Experiments on three long-form QA datasets show that our RL-trained models achieve better calibration and generalize robustly across domains. Also, our method is highly efficient, as it only requires adding a few tokens to the output being decoded.
UNCLE: Uncertainty Expressions in Long-Form Generation
May 22, 2025Large Language Models (LLMs) are prone to hallucination, particularly in long-form generations. A promising direction to mitigate hallucination is to teach LLMs to express uncertainty explicitly when they lack sufficient knowledge. However, existing work lacks direct and fair evaluation of LLMs' ability to express uncertainty effectively in long-form generation. To address this gap, we first introduce UNCLE, a benchmark designed to evaluate uncertainty expression in both long- and short-form question answering (QA). UNCLE spans five domains and comprises 4k long-form QA instances and over 20k short-form QA pairs. Our dataset is the first to directly bridge short- and long-form QA with paired questions and gold-standard answers. Along with the benchmark, we propose a suite of new metrics to assess the models' capabilities to selectively express uncertainty. Using UNCLE, we then demonstrate that current models fail to convey uncertainty appropriately in long-form generation. We further explore both prompt-based and training-based methods to improve models' performance, with the training-based methods yielding greater gains. Further analysis of alignment gaps between short- and long-form uncertainty expression highlights promising directions for future research using UNCLE.
PT-MoE: An Efficient Finetuning Framework for Integrating Mixture-of-Experts into Prompt Tuning
May 14, 2025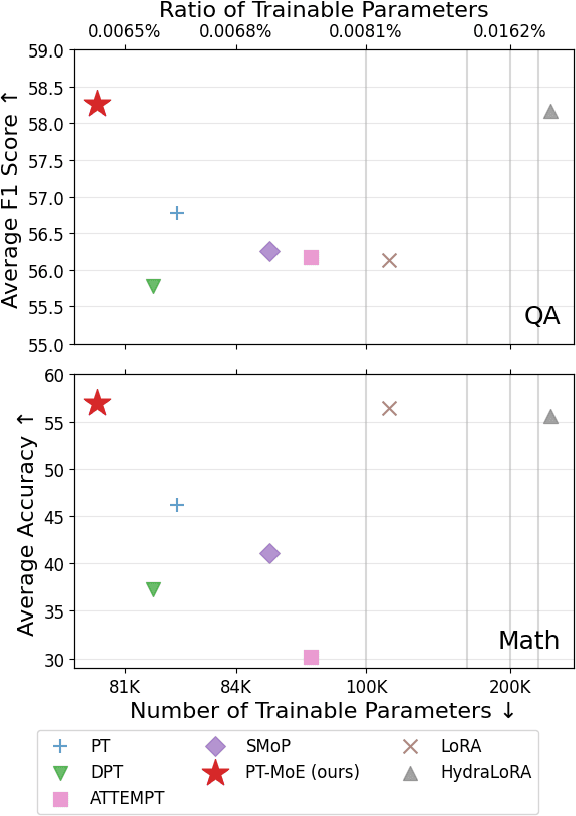

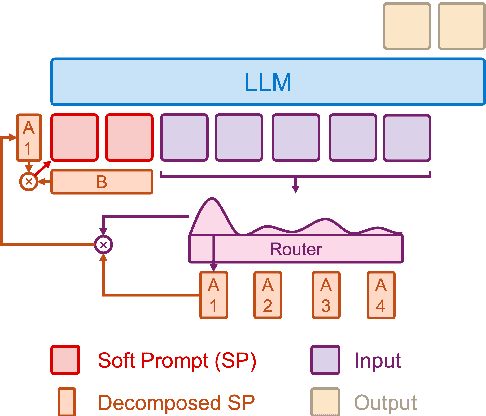
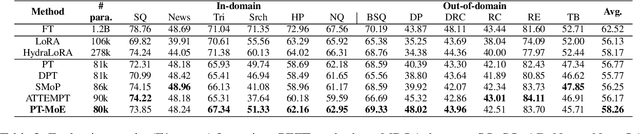
Parameter-efficient fine-tuning (PEFT) methods have shown promise in adapting large language models, yet existing approaches exhibit counter-intuitive phenomena: integrating router into prompt tuning (PT) increases training efficiency yet does not improve performance universally; parameter reduction through matrix decomposition can improve performance in specific domains. Motivated by these observations and the modular nature of PT, we propose PT-MoE, a novel framework that integrates matrix decomposition with mixture-of-experts (MoE) routing for efficient PT. Results across 17 datasets demonstrate that PT-MoE achieves state-of-the-art performance in both question answering (QA) and mathematical problem solving tasks, improving F1 score by 1.49 points over PT and 2.13 points over LoRA in QA tasks, while enhancing mathematical accuracy by 10.75 points over PT and 0.44 points over LoRA, all while using 25% fewer parameters than LoRA. Our analysis reveals that while PT methods generally excel in QA tasks and LoRA-based methods in math datasets, the integration of matrix decomposition and MoE in PT-MoE yields complementary benefits: decomposition enables efficient parameter sharing across experts while MoE provides dynamic adaptation, collectively enabling PT-MoE to demonstrate cross-task consistency and generalization abilities. These findings, along with ablation studies on routing mechanisms and architectural components, provide insights for future PEFT methods.