 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomic Calibration of LLMs in Long-Form Generations
Paper and Code
Oct 17, 2024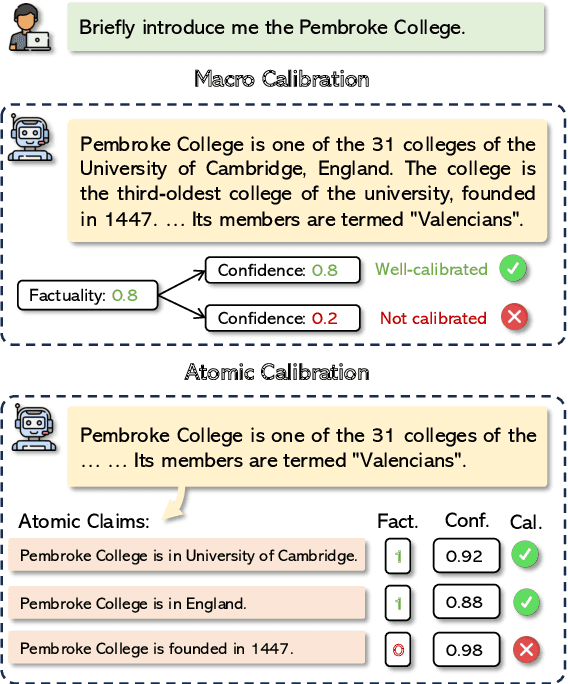



Large language models (LLMs) often suffer from hallucinations, posing significant challenges for real-world applications. Confidence calibration, which estimates the underlying uncertainty of model predictions, is essential to enhance the LLMs' trustworthiness. Existing research on LLM calibration has primarily focused on short-form tasks, providing a single confidence score at the response level (macro calibration). However, this approach is insufficient for long-form generations, where responses often contain more complex statements and may include both accurate and inaccurate information. Therefore, we introduce atomic calibration, a novel approach that evaluates factuality calibration at a fine-grained level by breaking down long responses into atomic claims. We classify confidence elicitation methods into discriminative and generative types and demonstrate that their combination can enhance calibration. Our extensive experiments on various LLMs and datasets show that atomic calibration is well-suited for long-form generation and can also improve macro calibration results. Additionally, atomic calibration reveals insightful patterns in LLM confidence throughout the generation process.