 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Phase LLM Reasoning: Self-Evolved Mathematical Frameworks
Jan 09, 2026In recent years, large language models (LLMs) have demonstrated significant potential in complex reasoning tasks like mathematical problem-solving. However, existing research predominantly relies on reinforcement learning (RL) frameworks while overlooking supervised fine-tuning (SFT) methods. This paper proposes a new two-stage training framework that enhances models' self-correction capabilities through self-generated long chain-of-thought (CoT) data. During the first stage, a multi-turn dialogue strategy guides the model to generate CoT data incorporating verification, backtracking, subgoal decomposition, and backward reasoning, with predefined rules filtering high-quality samples for supervised fine-tuning. The second stage employs a difficulty-aware rejection sampling mechanism to dynamically optimize data distribution, strengthening the model's ability to handle complex problems. The approach generates reasoning chains extended over 4 times longer while maintaining strong scalability, proving that SFT effectively activates models' intrinsic reasoning capabilities and provides a resource-efficient pathway for complex task optimization. Experimental results demonstrate performance improvements on mathematical benchmarks including GSM8K and MATH500, with the fine-tuned model achieving a substantial improvement on competition-level problems like AIME24. Code will be open-sourced.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025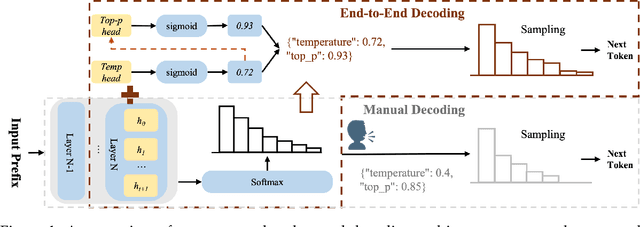
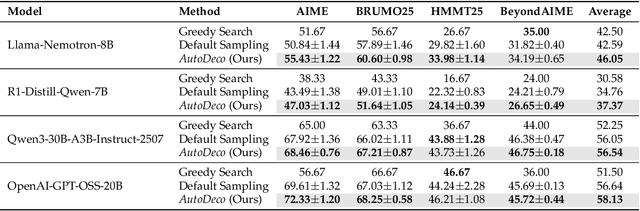
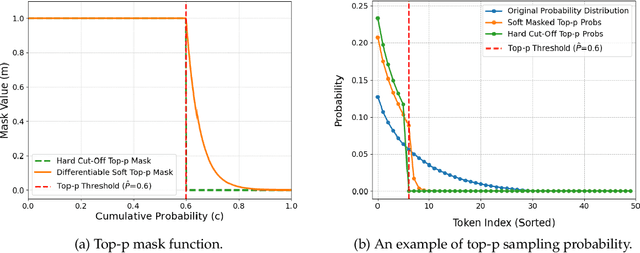
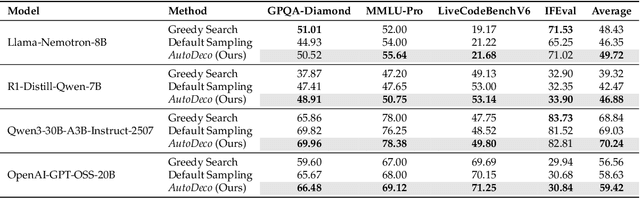
The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
UNCLE: Uncertainty Expressions in Long-Form Generation
May 22, 2025Large Language Models (LLMs) are prone to hallucination, particularly in long-form generations. A promising direction to mitigate hallucination is to teach LLMs to express uncertainty explicitly when they lack sufficient knowledge. However, existing work lacks direct and fair evaluation of LLMs' ability to express uncertainty effectively in long-form generation. To address this gap, we first introduce UNCLE, a benchmark designed to evaluate uncertainty expression in both long- and short-form question answering (QA). UNCLE spans five domains and comprises 4k long-form QA instances and over 20k short-form QA pairs. Our dataset is the first to directly bridge short- and long-form QA with paired questions and gold-standard answers. Along with the benchmark, we propose a suite of new metrics to assess the models' capabilities to selectively express uncertainty. Using UNCLE, we then demonstrate that current models fail to convey uncertainty appropriately in long-form generation. We further explore both prompt-based and training-based methods to improve models' performance, with the training-based methods yielding greater gains. Further analysis of alignment gaps between short- and long-form uncertainty expression highlights promising directions for future research using UNCLE.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Low-hallucination Synthetic Captions for Large-Scale Vision-Language Model Pre-training
Apr 17, 2025In recent years, the field of vision-language model pre-training has experienced rapid advancements, driven primarily by the continuous enhancement of textual capabilities in large language models. However, existing training paradigms for multimodal large language models heavily rely on high-quality image-text pairs. As models and data scales grow exponentially, the availability of such meticulously curated data has become increasingly scarce and saturated, thereby severely limiting further advancements in this domain. This study investigates scalable caption generation techniques for vision-language model pre-training and demonstrates that large-scale low-hallucination synthetic captions can serve dual purposes: 1) acting as a viable alternative to real-world data for pre-training paradigms and 2) achieving superior performance enhancement when integrated into vision-language models through empirical validation. This paper presents three key contributions: 1) a novel pipeline for generating high-quality, low-hallucination, and knowledge-rich synthetic captions. Our continuous DPO methodology yields remarkable results in reducing hallucinations. Specifically, the non-hallucination caption rate on a held-out test set increases from 48.2% to 77.9% for a 7B-size model. 2) Comprehensive empirical validation reveals that our synthetic captions confer superior pre-training advantages over their counterparts. Across 35 vision language tasks, the model trained with our data achieves a significant performance gain of at least 6.2% compared to alt-text pairs and other previous work. Meanwhile, it also offers considerable support in the text-to-image domain. With our dataset, the FID score is reduced by 17.1 on a real-world validation benchmark and 13.3 on the MSCOCO validation benchmark. 3) We will release Hunyuan-Recap100M, a low-hallucination and knowledge-intensive synthetic caption dataset.
Contextualize-then-Aggregate: Circuits for In-Context Learning in Gemma-2 2B
Mar 31, 2025

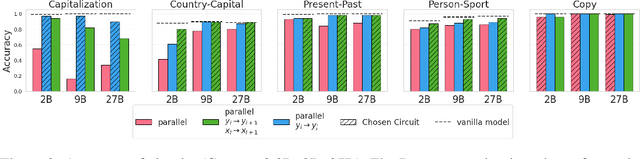

In-Context Learning (ICL) is an intriguing ability of large language models (LLMs). Despite a substantial amount of work on its behavioral aspects and how it emerges in miniature setups, it remains unclear which mechanism assembles task information from the individual examples in a fewshot prompt. We use causal interventions to identify information flow in Gemma-2 2B for five naturalistic ICL tasks. We find that the model infers task information using a two-step strategy we call contextualize-then-aggregate: In the lower layers, the model builds up representations of individual fewshot examples, which are contextualized by preceding examples through connections between fewshot input and output tokens across the sequence. In the higher layers, these representations are aggregated to identify the task and prepare prediction of the next output. The importance of the contextualization step differs between tasks, and it may become more important in the presence of ambiguous examples. Overall, by providing rigorous causal analysis, our results shed light on the mechanisms through which ICL happens in language models.
Lower Bounds for Chain-of-Thought Reasoning in Hard-Attention Transformers
Feb 04, 2025Chain-of-thought reasoning and scratchpads have emerged as critical tools for enhancing the computational capabilities of transformers. While theoretical results show that polynomial-length scratchpads can extend transformers' expressivity from $TC^0$ to $PTIME$, their required length remains poorly understood. Empirical evidence even suggests that transformers need scratchpads even for many problems in $TC^0$, such as Parity or Multiplication, challenging optimistic bounds derived from circuit complexity. In this work, we initiate the study of systematic lower bounds for the number of CoT steps across different algorithmic problems, in the hard-attention regime. We study a variety of algorithmic problems, and provide bounds that are tight up to logarithmic factors. Overall, these results contribute to emerging understanding of the power and limitations of chain-of-thought reasoning.
A Silver Bullet or a Compromise for Full Attention? A Comprehensive Study of Gist Token-based Context Compression
Dec 23, 2024



In this work, we provide a thorough investigation of gist-based context compression methods to improve long-context processing in large language models. We focus on two key questions: (1) How well can these methods replace full attention models? and (2) What potential failure patterns arise due to compression? Through extensive experiments, we show that while gist-based compression can achieve near-lossless performance on tasks like retrieval-augmented generation and long-document QA, it faces challenges in tasks like synthetic recall. Furthermore, we identify three key failure patterns: lost by the boundary, lost if surprise, and lost along the way. To mitigate these issues, we propose two effective strategies: fine-grained autoencoding, which enhances the reconstruction of original token information, and segment-wise token importance estimation, which adjusts optimization based on token dependencies. Our work provides valuable insights into the understanding of gist token-based context compression and offers practical strategies for improving compression capabilities.
Attention Entropy is a Key Factor: An Analysis of Parallel Context Encoding with Full-attention-based Pre-trained Language Models
Dec 21, 2024



Large language models have shown remarkable performance across a wide range of language tasks, owing to their exceptional capabilities in context modeling. The most commonly used method of context modeling is full self-attention, as seen in standard decoder-only Transformers. Although powerful, this method can be inefficient for long sequences and may overlook inherent input structures. To address these problems, an alternative approach is parallel context encoding, which splits the context into sub-pieces and encodes them parallelly. Because parallel patterns are not encountered during training, naively applying parallel encoding leads to performance degradation. However, the underlying reasons and potential mitigations are unclear. In this work, we provide a detailed analysis of this issue and identify that unusually high attention entropy can be a key factor. Furthermore, we adopt two straightforward methods to reduce attention entropy by incorporating attention sinks and selective mechanisms. Experiments on various tasks reveal that these methods effectively lower irregular attention entropy and narrow performance gaps. We hope this study can illuminate ways to enhance context modeling mechanisms.
LoGU: Long-form Generation with Uncertainty Expressions
Oct 18, 2024



While Large Language Models (LLMs) demonstrate impressive capabilities, they still struggle with generating factually incorrect content (i.e., hallucinations). A promising approach to mitigate this issue is enabling models to express uncertainty when unsure. Previous research on uncertainty modeling has primarily focused on short-form QA, but realworld applications often require much longer responses. In this work, we introduce the task of Long-form Generation with Uncertainty(LoGU). We identify two key challenges: Uncertainty Suppression, where models hesitate to express uncertainty, and Uncertainty Misalignment, where models convey uncertainty inaccurately. To tackle these challenges, we propose a refinement-based data collection framework and a two-stage training pipeline. Our framework adopts a divide-and-conquer strategy, refining uncertainty based on atomic claims. The collected data are then used in training through supervised fine-tuning (SFT) and direct preference optimization (DPO) to enhance uncertainty expression. Extensive experiments on three long-form instruction following datasets show that our method significantly improves accuracy, reduces hallucinations, and maintains the comprehensiveness of responses.