 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorn a Transformer -- Always a Transformer?
May 27, 2025Transformers have theoretical limitations in modeling certain sequence-to-sequence tasks, yet it remains largely unclear if these limitations play a role in large-scale pretrained LLMs, or whether LLMs might effectively overcome these constraints in practice due to the scale of both the models themselves and their pretraining data. We explore how these architectural constraints manifest after pretraining, by studying a family of $\textit{retrieval}$ and $\textit{copying}$ tasks inspired by Liu et al. [2024]. We use the recently proposed C-RASP framework for studying length generalization [Huang et al., 2025b] to provide guarantees for each of our settings. Empirically, we observe an $\textit{induction-versus-anti-induction}$ asymmetry, where pretrained models are better at retrieving tokens to the right (induction) rather than the left (anti-induction) of a query token. This asymmetry disappears upon targeted fine-tuning if length-generalization is guaranteed by theory. Mechanistic analysis reveals that this asymmetry is connected to the differences in the strength of induction versus anti-induction circuits within pretrained Transformers. We validate our findings through practical experiments on real-world tasks demonstrating reliability risks. Our results highlight that pretraining selectively enhances certain Transformer capabilities, but does not overcome fundamental length-generalization limits.
Contextualize-then-Aggregate: Circuits for In-Context Learning in Gemma-2 2B
Mar 31, 2025

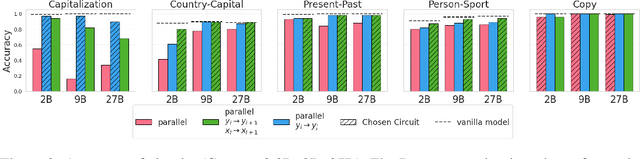

In-Context Learning (ICL) is an intriguing ability of large language models (LLMs). Despite a substantial amount of work on its behavioral aspects and how it emerges in miniature setups, it remains unclear which mechanism assembles task information from the individual examples in a fewshot prompt. We use causal interventions to identify information flow in Gemma-2 2B for five naturalistic ICL tasks. We find that the model infers task information using a two-step strategy we call contextualize-then-aggregate: In the lower layers, the model builds up representations of individual fewshot examples, which are contextualized by preceding examples through connections between fewshot input and output tokens across the sequence. In the higher layers, these representations are aggregated to identify the task and prepare prediction of the next output. The importance of the contextualization step differs between tasks, and it may become more important in the presence of ambiguous examples. Overall, by providing rigorous causal analysis, our results shed light on the mechanisms through which ICL happens in language models.
Recent Advancements and Challenges of Turkic Central Asian Language Processing
Jul 06, 2024Research in the NLP sphere of the Turkic counterparts of Central Asian languages, namely Kazakh, Uzbek, Kyrgyz, and Turkmen, comes with the typical challenges of low-resource languages, like data scarcity and a general lack of linguistic resources. However, in the recent years research has greatly advanced via collection of language-specific datasets and development of downstream task technologies. Aiming to summarize this research up until May 2024, this paper also seeks to identify potential areas of future work. To achieve this, the paper gives a broad, high-level overview of the linguistic properties of the languages, the current coverage and performance of already developed technology, application of transfer learning techniques from higher-resource languages, and availability of labeled and unlabeled data for each language. Providing a summary of the current state of affairs, we hope that further research will be facilitated with the considerations we provide in the current paper.
The Expressive Capacity of State Space Models: A Formal Language Perspective
May 27, 2024Recently, recurrent models based on linear state space models (SSMs) have shown promising performance in language modeling (LM), competititve with transformers. However, there is little understanding of the in-principle abilities of such models, which could provide useful guidance to the search for better LM architectures. We present a comprehensive theoretical study of the capacity of such SSMs as it compares to that of transformers and traditional RNNs. We find that SSMs and transformers have overlapping but distinct strengths. In star-free state tracking, SSMs implement straightforward and exact solutions to problems that transformers struggle to represent exactly. They can also model bounded hierarchical structure with optimal memory even without simulating a stack. On the other hand, we identify a design choice in current SSMs that limits their expressive power. We discuss implications for SSM and LM research, and verify results empirically on a recent SSM, Mamba.