 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorn a Transformer -- Always a Transformer?
May 27, 2025Transformers have theoretical limitations in modeling certain sequence-to-sequence tasks, yet it remains largely unclear if these limitations play a role in large-scale pretrained LLMs, or whether LLMs might effectively overcome these constraints in practice due to the scale of both the models themselves and their pretraining data. We explore how these architectural constraints manifest after pretraining, by studying a family of $\textit{retrieval}$ and $\textit{copying}$ tasks inspired by Liu et al. [2024]. We use the recently proposed C-RASP framework for studying length generalization [Huang et al., 2025b] to provide guarantees for each of our settings. Empirically, we observe an $\textit{induction-versus-anti-induction}$ asymmetry, where pretrained models are better at retrieving tokens to the right (induction) rather than the left (anti-induction) of a query token. This asymmetry disappears upon targeted fine-tuning if length-generalization is guaranteed by theory. Mechanistic analysis reveals that this asymmetry is connected to the differences in the strength of induction versus anti-induction circuits within pretrained Transformers. We validate our findings through practical experiments on real-world tasks demonstrating reliability risks. Our results highlight that pretraining selectively enhances certain Transformer capabilities, but does not overcome fundamental length-generalization limits.
A Formal Framework for Understanding Length Generalization in Transformers
Oct 03, 2024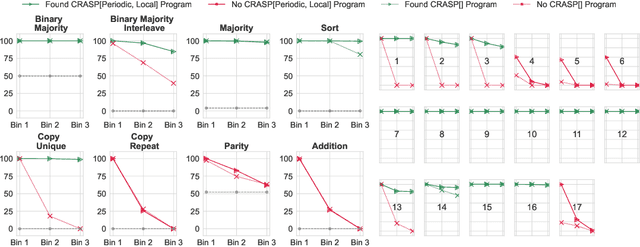

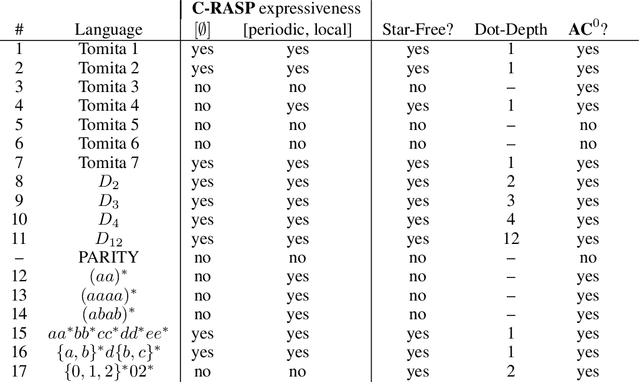
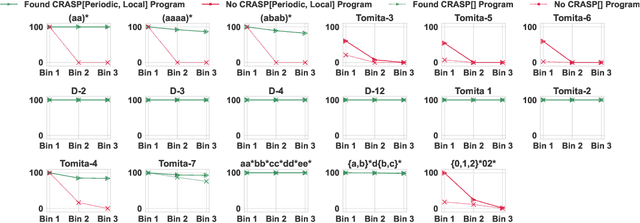
A major challenge for transformers is generalizing to sequences longer than those observed during training. While previous works have empirically shown that transformers can either succeed or fail at length generalization depending on the task, theoretical understanding of this phenomenon remains limited. In this work, we introduce a rigorous theoretical framework to analyze length generalization in causal transformers with learnable absolute positional encodings. In particular, we characterize those functions that are identifiable in the limit from sufficiently long inputs with absolute positional encodings under an idealized inference scheme using a norm-based regularizer. This enables us to prove the possibility of length generalization for a rich family of problems. We experimentally validate the theory as a predictor of success and failure of length generalization across a range of algorithmic and formal language tasks. Our theory not only explains a broad set of empirical observations but also opens the way to provably predicting length generalization capabilities in transformers.
The Expressive Capacity of State Space Models: A Formal Language Perspective
May 27, 2024Recently, recurrent models based on linear state space models (SSMs) have shown promising performance in language modeling (LM), competititve with transformers. However, there is little understanding of the in-principle abilities of such models, which could provide useful guidance to the search for better LM architectures. We present a comprehensive theoretical study of the capacity of such SSMs as it compares to that of transformers and traditional RNNs. We find that SSMs and transformers have overlapping but distinct strengths. In star-free state tracking, SSMs implement straightforward and exact solutions to problems that transformers struggle to represent exactly. They can also model bounded hierarchical structure with optimal memory even without simulating a stack. On the other hand, we identify a design choice in current SSMs that limits their expressive power. We discuss implications for SSM and LM research, and verify results empirically on a recent SSM, Mamba.