 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Fairness and Explainability: Can Input-Based Explanations Promote Fairness in Hate Speech Detection?
Sep 26, 2025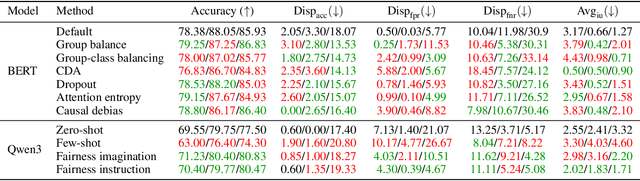
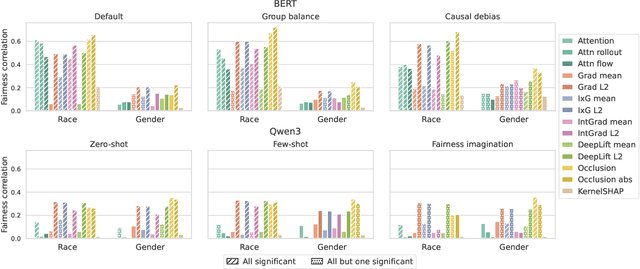
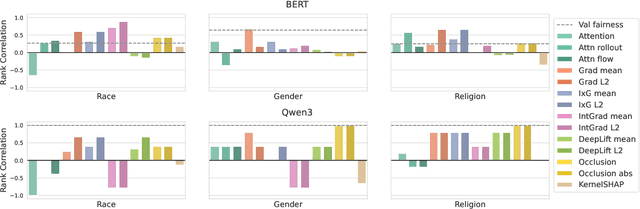

Natural language processing (NLP) models often replicate or amplify social bias from training data, raising concerns about fairness. At the same time, their black-box nature makes it difficult for users to recognize biased predictions and for developers to effectively mitigate them. While some studies suggest that input-based explanations can help detect and mitigate bias, others question their reliability in ensuring fairness. Existing research on explainability in fair NLP has been predominantly qualitative, with limited large-scale quantitative analysis. In this work, we conduct the first systematic study of the relationship between explainability and fairness in hate speech detection, focusing on both encoder- and decoder-only models. We examine three key dimensions: (1) identifying biased predictions, (2) selecting fair models, and (3) mitigating bias during model training. Our findings show that input-based explanations can effectively detect biased predictions and serve as useful supervision for reducing bias during training, but they are unreliable for selecting fair models among candidates.
Born a Transformer -- Always a Transformer?
May 27, 2025Transformers have theoretical limitations in modeling certain sequence-to-sequence tasks, yet it remains largely unclear if these limitations play a role in large-scale pretrained LLMs, or whether LLMs might effectively overcome these constraints in practice due to the scale of both the models themselves and their pretraining data. We explore how these architectural constraints manifest after pretraining, by studying a family of $\textit{retrieval}$ and $\textit{copying}$ tasks inspired by Liu et al. [2024]. We use the recently proposed C-RASP framework for studying length generalization [Huang et al., 2025b] to provide guarantees for each of our settings. Empirically, we observe an $\textit{induction-versus-anti-induction}$ asymmetry, where pretrained models are better at retrieving tokens to the right (induction) rather than the left (anti-induction) of a query token. This asymmetry disappears upon targeted fine-tuning if length-generalization is guaranteed by theory. Mechanistic analysis reveals that this asymmetry is connected to the differences in the strength of induction versus anti-induction circuits within pretrained Transformers. We validate our findings through practical experiments on real-world tasks demonstrating reliability risks. Our results highlight that pretraining selectively enhances certain Transformer capabilities, but does not overcome fundamental length-generalization limits.
B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability
Feb 18, 2025Post-hoc explanation methods for black-box models often struggle with faithfulness and human interpretability due to the lack of explainability in current neural models. Meanwhile, B-cos networks have been introduced to improve model explainability through architectural and computational adaptations, but their application has so far been limited to computer vision models and their associated training pipelines. In this work, we introduce B-cos LMs, i.e., B-cos networks empowered for NLP tasks. Our approach directly transforms pre-trained language models into B-cos LMs by combining B-cos conversion and task fine-tuning, improving efficiency compared to previous B-cos methods. Our automatic and human evaluation results demonstrate that B-cos LMs produce more faithful and human interpretable explanations than post hoc methods, while maintaining task performance comparable to conventional fine-tuning. Our in-depth analysis explores how B-cos LMs differ from conventionally fine-tuned models in their learning processes and explanation patterns. Finally, we provide practical guidelines for effectively building B-cos LMs based on our findings. Our code is available at https://anonymous.4open.science/r/bcos_lm.
Samanantar: The Largest Publicly Available Parallel Corpora Collection for 11 Indic Languages
Apr 29, 2021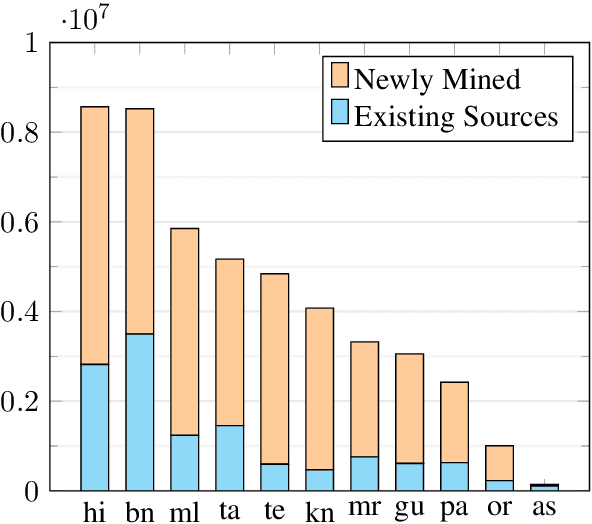
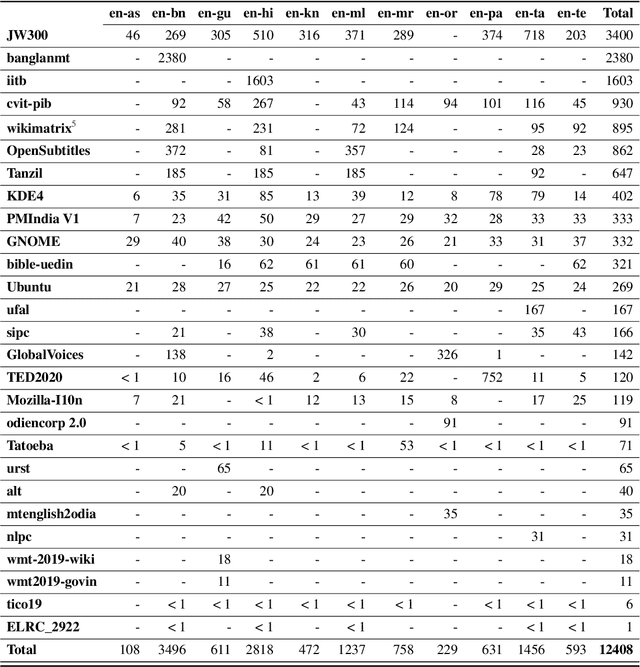
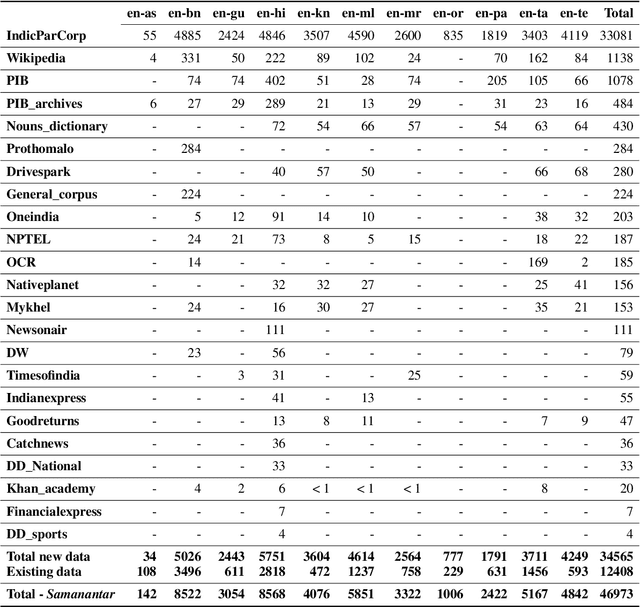
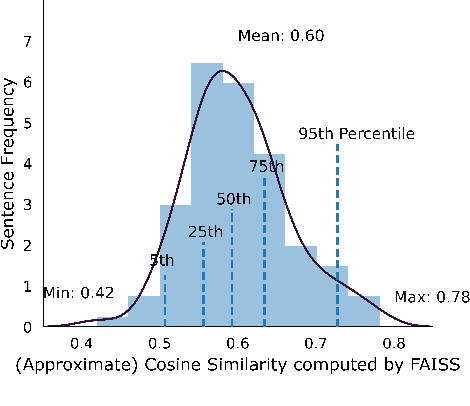
We present Samanantar, the largest publicly available parallel corpora collection for Indic languages. The collection contains a total of 46.9 million sentence pairs between English and 11 Indic languages (from two language families). In particular, we compile 12.4 million sentence pairs from existing, publicly-available parallel corpora, and we additionally mine 34.6 million sentence pairs from the web, resulting in a 2.8X increase in publicly available sentence pairs. We mine the parallel sentences from the web by combining many corpora, tools, and methods. In particular, we use (a) web-crawled monolingual corpora, (b) document OCR for extracting sentences from scanned documents (c) multilingual representation models for aligning sentences, and (d) approximate nearest neighbor search for searching in a large collection of sentences. Human evaluation of samples from the newly mined corpora validate the high quality of the parallel sentences across 11 language pairs. Further, we extracted 82.7 million sentence pairs between all 55 Indic language pairs from the English-centric parallel corpus using English as the pivot language. We trained multilingual NMT models spanning all these languages on Samanantar and compared with other baselines and previously reported results on publicly available benchmarks. Our models outperform existing models on these benchmarks, establishing the utility of Samanantar. Our data (https://indicnlp.ai4bharat.org/samanantar) and models (https://github.com/AI4Bharat/IndicTrans) will be available publicly and we hope they will help advance research in Indic NMT and multilingual NLP for Indic languages.
Unsupervised Question Answering for Fact-Checking
Oct 16, 2019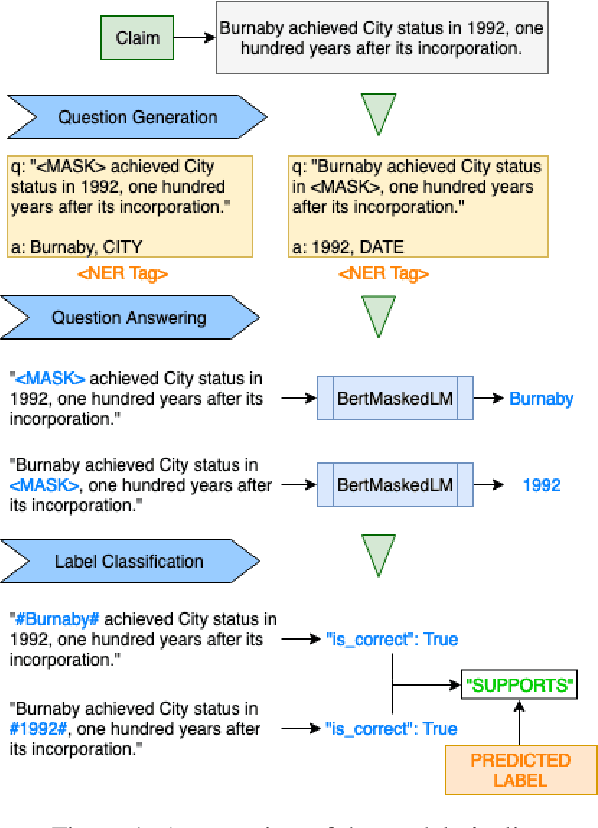
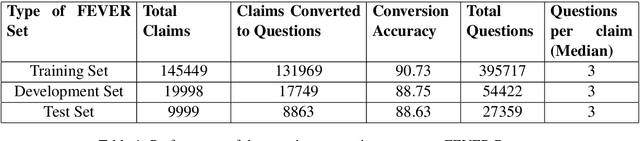
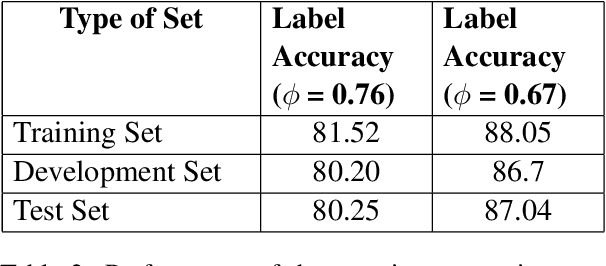
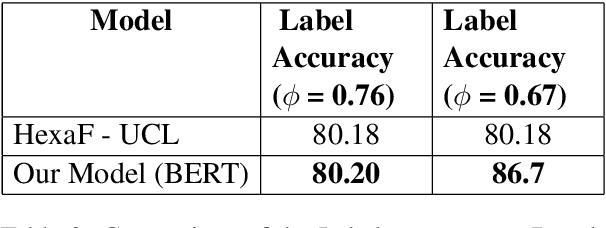
Recent Deep Learning (DL) models have succeeded in achieving human-level accuracy on various natural language tasks such as question-answering, natural language inference (NLI), and textual entailment. These tasks not only require the contextual knowledge but also the reasoning abilities to be solved efficiently. In this paper, we propose an unsupervised question-answering based approach for a similar task, fact-checking. We transform the FEVER dataset into a Cloze-task by masking named entities provided in the claims. To predict the answer token, we utilize pre-trained Bidirectional Encoder Representations from Transformers (BERT). The classifier computes label based on the correctly answered questions and a threshold. Currently, the classifier is able to classify the claims as "SUPPORTS" and "MANUAL_REVIEW". This approach achieves a label accuracy of 80.2% on the development set and 80.25% on the test set of the transformed dataset.