 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEVI: Text-Conditioned Editing of Visual Representations via Sparse Autoencoders for Improved Vision-Language Alignment
Jun 05, 2026Vision-language models such as CLIP are highly useful for diverse tasks due to their shared image-text embedding space. Despite this, the image and text embeddings are often poorly aligned, affecting downstream performance. Recent work has shown that this can be attributed to an information imbalance: images contain more information than their captions describe. In this work, we propose TEVI, a framework that uses captions as a signal for what to retain from image embeddings. Specifically, we use sparse autoencoders to disentangle image embeddings and train a masking module to selectively reconstruct the embedding based on a given caption. In a controlled setup with synthetic captions, we show that TEVI is effective at preserving caption-described attributes while discarding others. By applying TEVI to CLIP models trained on natural images, we further achieve improved retrieval performance across coarse-grained short-caption (MS COCO, Flickr) and fine-grained long-caption (IIW, DOCCI) benchmarks, with stronger gains on richer captions, and improved robustness on the RoCOCO benchmark.
Insight: Interpretable Semantic Hierarchies in Vision-Language Encoders
Jan 20, 2026Language-aligned vision foundation models perform strongly across diverse downstream tasks. Yet, their learned representations remain opaque, making interpreting their decision-making hard. Recent works decompose these representations into human-interpretable concepts, but provide poor spatial grounding and are limited to image classification tasks. In this work, we propose Insight, a language-aligned concept foundation model that provides fine-grained concepts, which are human-interpretable and spatially grounded in the input image. We leverage a hierarchical sparse autoencoder and a foundation model with strong semantic representations to automatically extract concepts at various granularities. Examining local co-occurrence dependencies of concepts allows us to define concept relationships. Through these relations we further improve concept naming and obtain richer explanations. On benchmark data, we show that Insight provides performance on classification and segmentation that is competitive with opaque foundation models while providing fine-grained, high quality concept-based explanations. Code is available at https://github.com/kawi19/Insight.
B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability
Feb 18, 2025Post-hoc explanation methods for black-box models often struggle with faithfulness and human interpretability due to the lack of explainability in current neural models. Meanwhile, B-cos networks have been introduced to improve model explainability through architectural and computational adaptations, but their application has so far been limited to computer vision models and their associated training pipelines. In this work, we introduce B-cos LMs, i.e., B-cos networks empowered for NLP tasks. Our approach directly transforms pre-trained language models into B-cos LMs by combining B-cos conversion and task fine-tuning, improving efficiency compared to previous B-cos methods. Our automatic and human evaluation results demonstrate that B-cos LMs produce more faithful and human interpretable explanations than post hoc methods, while maintaining task performance comparable to conventional fine-tuning. Our in-depth analysis explores how B-cos LMs differ from conventionally fine-tuned models in their learning processes and explanation patterns. Finally, we provide practical guidelines for effectively building B-cos LMs based on our findings. Our code is available at https://anonymous.4open.science/r/bcos_lm.
B-cosification: Transforming Deep Neural Networks to be Inherently Interpretable
Nov 01, 2024
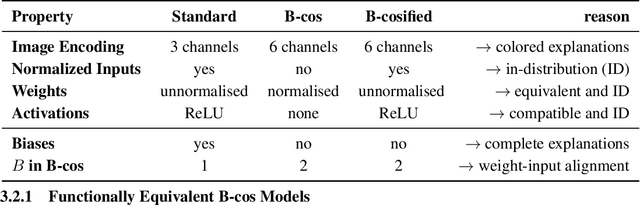


B-cos Networks have been shown to be effective for obtaining highly human interpretable explanations of model decisions by architecturally enforcing stronger alignment between inputs and weight. B-cos variants of convolutional networks (CNNs) and vision transformers (ViTs), which primarily replace linear layers with B-cos transformations, perform competitively to their respective standard variants while also yielding explanations that are faithful by design. However, it has so far been necessary to train these models from scratch, which is increasingly infeasible in the era of large, pre-trained foundation models. In this work, inspired by the architectural similarities in standard DNNs and B-cos networks, we propose 'B-cosification', a novel approach to transform existing pre-trained models to become inherently interpretable. We perform a thorough study of design choices to perform this conversion, both for convolutional neural networks and vision transformers. We find that B-cosification can yield models that are on par with B-cos models trained from scratch in terms of interpretability, while often outperforming them in terms of classification performance at a fraction of the training cost. Subsequently, we apply B-cosification to a pretrained CLIP model, and show that, even with limited data and compute cost, we obtain a B-cosified version that is highly interpretable and competitive on zero shot performance across a variety of datasets. We release our code and pre-trained model weights at https://github.com/shrebox/B-cosification.
Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Jul 19, 2024



Concept Bottleneck Models (CBMs) have recently been proposed to address the 'black-box' problem of deep neural networks, by first mapping images to a human-understandable concept space and then linearly combining concepts for classification. Such models typically require first coming up with a set of concepts relevant to the task and then aligning the representations of a feature extractor to map to these concepts. However, even with powerful foundational feature extractors like CLIP, there are no guarantees that the specified concepts are detectable. In this work, we leverage recent advances in mechanistic interpretability and propose a novel CBM approach -- called Discover-then-Name-CBM (DN-CBM) -- that inverts the typical paradigm: instead of pre-selecting concepts based on the downstream classification task, we use sparse autoencoders to first discover concepts learnt by the model, and then name them and train linear probes for classification. Our concept extraction strategy is efficient, since it is agnostic to the downstream task, and uses concepts already known to the model. We perform a comprehensive evaluation across multiple datasets and CLIP architectures and show that our method yields semantically meaningful concepts, assigns appropriate names to them that make them easy to interpret, and yields performant and interpretable CBMs. Code available at https://github.com/neuroexplicit-saar/discover-then-name.
Good Teachers Explain: Explanation-Enhanced Knowledge Distillation
Feb 05, 2024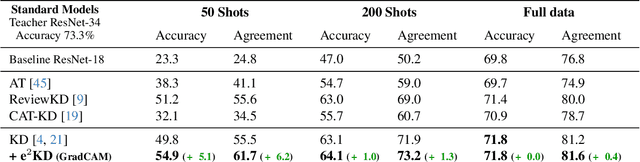
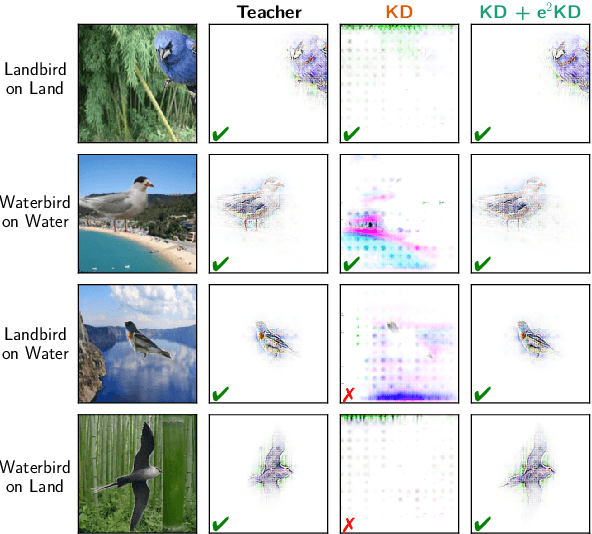
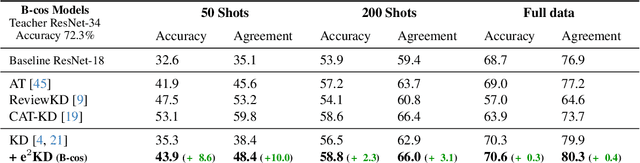

Knowledge Distillation (KD) has proven effective for compressing large teacher models into smaller student models. While it is well known that student models can achieve similar accuracies as the teachers, it has also been shown that they nonetheless often do not learn the same function. It is, however, often highly desirable that the student's and teacher's functions share similar properties such as basing the prediction on the same input features, as this ensures that students learn the 'right features' from the teachers. In this work, we explore whether this can be achieved by not only optimizing the classic KD loss but also the similarity of the explanations generated by the teacher and the student. Despite the idea being simple and intuitive, we find that our proposed 'explanation-enhanced' KD (e$^2$KD) (1) consistently provides large gains in terms of accuracy and student-teacher agreement, (2) ensures that the student learns from the teacher to be right for the right reasons and to give similar explanations, and (3) is robust with respect to the model architectures, the amount of training data, and even works with 'approximate', pre-computed explanations.
Better Understanding Differences in Attribution Methods via Systematic Evaluations
Mar 21, 2023Deep neural networks are very successful on many vision tasks, but hard to interpret due to their black box nature. To overcome this, various post-hoc attribution methods have been proposed to identify image regions most influential to the models' decisions. Evaluating such methods is challenging since no ground truth attributions exist. We thus propose three novel evaluation schemes to more reliably measure the faithfulness of those methods, to make comparisons between them more fair, and to make visual inspection more systematic. To address faithfulness, we propose a novel evaluation setting (DiFull) in which we carefully control which parts of the input can influence the output in order to distinguish possible from impossible attributions. To address fairness, we note that different methods are applied at different layers, which skews any comparison, and so evaluate all methods on the same layers (ML-Att) and discuss how this impacts their performance on quantitative metrics. For more systematic visualizations, we propose a scheme (AggAtt) to qualitatively evaluate the methods on complete datasets. We use these evaluation schemes to study strengths and shortcomings of some widely used attribution methods over a wide range of models. Finally, we propose a post-processing smoothing step that significantly improves the performance of some attribution methods, and discuss its applicability.
Using Explanations to Guide Models
Mar 21, 2023



Deep neural networks are highly performant, but might base their decision on spurious or background features that co-occur with certain classes, which can hurt generalization. To mitigate this issue, the usage of 'model guidance' has gained popularity recently: for this, models are guided to be "right for the right reasons" by regularizing the models' explanations to highlight the right features. Experimental validation of these approaches has thus far however been limited to relatively simple and / or synthetic datasets. To gain a better understanding of which model-guiding approaches actually transfer to more challenging real-world datasets, in this work we conduct an in-depth evaluation across various loss functions, attribution methods, models, and 'guidance depths' on the PASCAL VOC 2007 and MS COCO 2014 datasets, and show that model guidance can sometimes even improve model performance. In this context, we further propose a novel energy loss, show its effectiveness in directing the model to focus on object features. We also show that these gains can be achieved even with a small fraction (e.g. 1%) of bounding box annotations, highlighting the cost effectiveness of this approach. Lastly, we show that this approach can also improve generalization under distribution shifts. Code will be made available.
Towards Better Understanding Attribution Methods
May 20, 2022
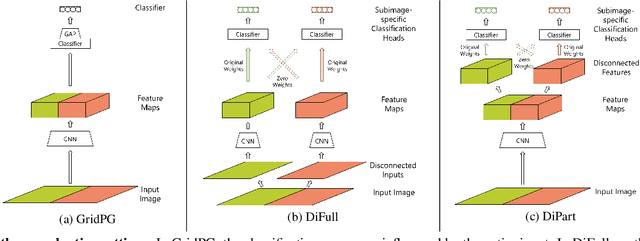

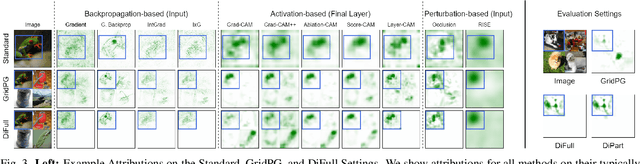
Deep neural networks are very successful on many vision tasks, but hard to interpret due to their black box nature. To overcome this, various post-hoc attribution methods have been proposed to identify image regions most influential to the models' decisions. Evaluating such methods is challenging since no ground truth attributions exist. We thus propose three novel evaluation schemes to more reliably measure the faithfulness of those methods, to make comparisons between them more fair, and to make visual inspection more systematic. To address faithfulness, we propose a novel evaluation setting (DiFull) in which we carefully control which parts of the input can influence the output in order to distinguish possible from impossible attributions. To address fairness, we note that different methods are applied at different layers, which skews any comparison, and so evaluate all methods on the same layers (ML-Att) and discuss how this impacts their performance on quantitative metrics. For more systematic visualizations, we propose a scheme (AggAtt) to qualitatively evaluate the methods on complete datasets. We use these evaluation schemes to study strengths and shortcomings of some widely used attribution methods. Finally, we propose a post-processing smoothing step that significantly improves the performance of some attribution methods, and discuss its applicability.
Adversarial Training against Location-Optimized Adversarial Patches
May 05, 2020
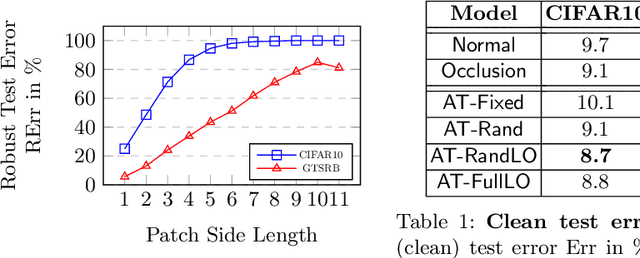

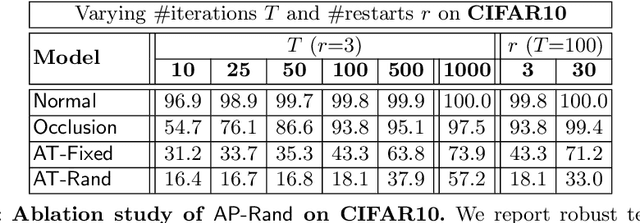
Deep neural networks have been shown to be susceptible to adversarial examples -- small, imperceptible changes constructed to cause mis-classification in otherwise highly accurate image classifiers. As a practical alternative, recent work proposed so-called adversarial patches: clearly visible, but adversarially crafted rectangular patches in images. These patches can easily be printed and applied in the physical world. While defenses against imperceptible adversarial examples have been studied extensively, robustness against adversarial patches is poorly understood. In this work, we first devise a practical approach to obtain adversarial patches while actively optimizing their location within the image. Then, we apply adversarial training on these location-optimized adversarial patches and demonstrate significantly improved robustness on CIFAR10 and GTSRB. Additionally, in contrast to adversarial training on imperceptible adversarial examples, our adversarial patch training does not reduce accuracy.