 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight: Interpretable Semantic Hierarchies in Vision-Language Encoders
Jan 20, 2026Language-aligned vision foundation models perform strongly across diverse downstream tasks. Yet, their learned representations remain opaque, making interpreting their decision-making hard. Recent works decompose these representations into human-interpretable concepts, but provide poor spatial grounding and are limited to image classification tasks. In this work, we propose Insight, a language-aligned concept foundation model that provides fine-grained concepts, which are human-interpretable and spatially grounded in the input image. We leverage a hierarchical sparse autoencoder and a foundation model with strong semantic representations to automatically extract concepts at various granularities. Examining local co-occurrence dependencies of concepts allows us to define concept relationships. Through these relations we further improve concept naming and obtain richer explanations. On benchmark data, we show that Insight provides performance on classification and segmentation that is competitive with opaque foundation models while providing fine-grained, high quality concept-based explanations. Code is available at https://github.com/kawi19/Insight.
Good Teachers Explain: Explanation-Enhanced Knowledge Distillation
Feb 05, 2024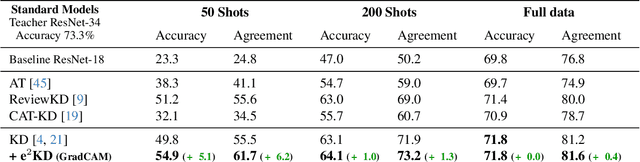
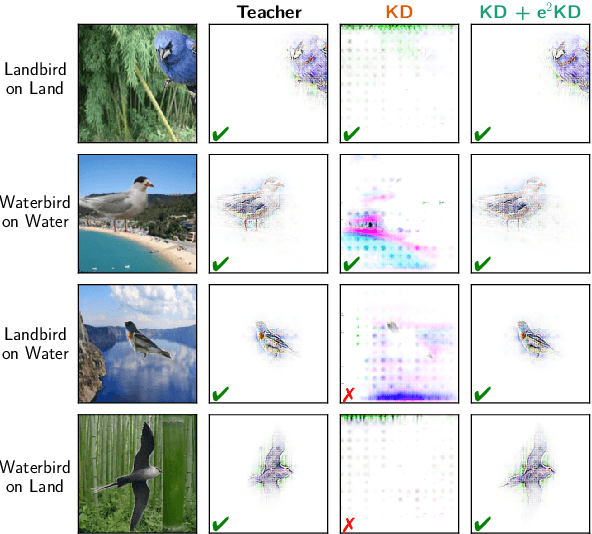
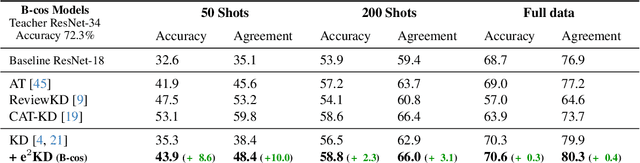

Knowledge Distillation (KD) has proven effective for compressing large teacher models into smaller student models. While it is well known that student models can achieve similar accuracies as the teachers, it has also been shown that they nonetheless often do not learn the same function. It is, however, often highly desirable that the student's and teacher's functions share similar properties such as basing the prediction on the same input features, as this ensures that students learn the 'right features' from the teachers. In this work, we explore whether this can be achieved by not only optimizing the classic KD loss but also the similarity of the explanations generated by the teacher and the student. Despite the idea being simple and intuitive, we find that our proposed 'explanation-enhanced' KD (e$^2$KD) (1) consistently provides large gains in terms of accuracy and student-teacher agreement, (2) ensures that the student learns from the teacher to be right for the right reasons and to give similar explanations, and (3) is robust with respect to the model architectures, the amount of training data, and even works with 'approximate', pre-computed explanations.
Using Explanations to Guide Models
Mar 21, 2023



Deep neural networks are highly performant, but might base their decision on spurious or background features that co-occur with certain classes, which can hurt generalization. To mitigate this issue, the usage of 'model guidance' has gained popularity recently: for this, models are guided to be "right for the right reasons" by regularizing the models' explanations to highlight the right features. Experimental validation of these approaches has thus far however been limited to relatively simple and / or synthetic datasets. To gain a better understanding of which model-guiding approaches actually transfer to more challenging real-world datasets, in this work we conduct an in-depth evaluation across various loss functions, attribution methods, models, and 'guidance depths' on the PASCAL VOC 2007 and MS COCO 2014 datasets, and show that model guidance can sometimes even improve model performance. In this context, we further propose a novel energy loss, show its effectiveness in directing the model to focus on object features. We also show that these gains can be achieved even with a small fraction (e.g. 1%) of bounding box annotations, highlighting the cost effectiveness of this approach. Lastly, we show that this approach can also improve generalization under distribution shifts. Code will be made available.