 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASA: Cross-Attention via Self-Attention for Efficient Vision-Language Fusion
Dec 22, 2025Vision-language models (VLMs) are commonly trained by inserting image tokens from a pretrained vision encoder into the textual stream of a language model. This allows text and image information to fully attend to one another within the model, but becomes extremely costly for high-resolution images, long conversations, or streaming videos, both in memory and compute. VLMs leveraging cross-attention are an efficient alternative to token insertion but exhibit a clear performance gap, in particular on tasks involving fine-grained visual details. We find that a key to improving such models is to also enable local text-to-text interaction in the dedicated cross-attention layers. Building on this, we propose CASA, Cross-Attention via Self-Attention, a simple and efficient paradigm which substantially reduces the gap with full token insertion on common image understanding benchmarks, while enjoying the same scalability as cross-attention models when applied to long-context multimodal tasks such as streaming video captioning. For samples and code, please see our project page at https://kyutai.org/casa .
Vision-Speech Models: Teaching Speech Models to Converse about Images
Mar 19, 2025The recent successes of Vision-Language models raise the question of how to equivalently imbue a pretrained speech model with vision understanding, an important milestone towards building a multimodal speech model able to freely converse about images. Building such a conversational Vision-Speech model brings its unique challenges: (i) paired image-speech datasets are much scarcer than their image-text counterparts, (ii) ensuring real-time latency at inference is crucial thus bringing compute and memory constraints, and (iii) the model should preserve prosodic features (e.g., speaker tone) which cannot be inferred from text alone. In this work, we introduce MoshiVis, augmenting a recent dialogue speech LLM, Moshi, with visual inputs through lightweight adaptation modules. An additional dynamic gating mechanism enables the model to more easily switch between the visual inputs and unrelated conversation topics. To reduce training costs, we design a simple one-stage, parameter-efficient fine-tuning pipeline in which we leverage a mixture of image-text (i.e., "speechless") and image-speech samples. We evaluate the model on downstream visual understanding tasks with both audio and text prompts, and report qualitative samples of interactions with MoshiVis. Our inference code will be made available, as well as the image-speech data used for audio evaluation.
B-cosification: Transforming Deep Neural Networks to be Inherently Interpretable
Nov 01, 2024
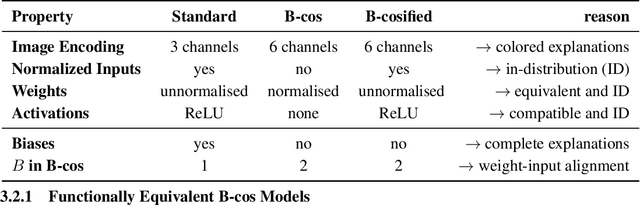


B-cos Networks have been shown to be effective for obtaining highly human interpretable explanations of model decisions by architecturally enforcing stronger alignment between inputs and weight. B-cos variants of convolutional networks (CNNs) and vision transformers (ViTs), which primarily replace linear layers with B-cos transformations, perform competitively to their respective standard variants while also yielding explanations that are faithful by design. However, it has so far been necessary to train these models from scratch, which is increasingly infeasible in the era of large, pre-trained foundation models. In this work, inspired by the architectural similarities in standard DNNs and B-cos networks, we propose 'B-cosification', a novel approach to transform existing pre-trained models to become inherently interpretable. We perform a thorough study of design choices to perform this conversion, both for convolutional neural networks and vision transformers. We find that B-cosification can yield models that are on par with B-cos models trained from scratch in terms of interpretability, while often outperforming them in terms of classification performance at a fraction of the training cost. Subsequently, we apply B-cosification to a pretrained CLIP model, and show that, even with limited data and compute cost, we obtain a B-cosified version that is highly interpretable and competitive on zero shot performance across a variety of datasets. We release our code and pre-trained model weights at https://github.com/shrebox/B-cosification.
Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Jul 19, 2024



Concept Bottleneck Models (CBMs) have recently been proposed to address the 'black-box' problem of deep neural networks, by first mapping images to a human-understandable concept space and then linearly combining concepts for classification. Such models typically require first coming up with a set of concepts relevant to the task and then aligning the representations of a feature extractor to map to these concepts. However, even with powerful foundational feature extractors like CLIP, there are no guarantees that the specified concepts are detectable. In this work, we leverage recent advances in mechanistic interpretability and propose a novel CBM approach -- called Discover-then-Name-CBM (DN-CBM) -- that inverts the typical paradigm: instead of pre-selecting concepts based on the downstream classification task, we use sparse autoencoders to first discover concepts learnt by the model, and then name them and train linear probes for classification. Our concept extraction strategy is efficient, since it is agnostic to the downstream task, and uses concepts already known to the model. We perform a comprehensive evaluation across multiple datasets and CLIP architectures and show that our method yields semantically meaningful concepts, assigns appropriate names to them that make them easy to interpret, and yields performant and interpretable CBMs. Code available at https://github.com/neuroexplicit-saar/discover-then-name.
Good Teachers Explain: Explanation-Enhanced Knowledge Distillation
Feb 05, 2024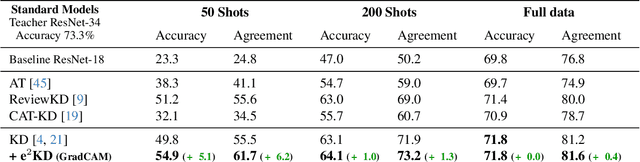
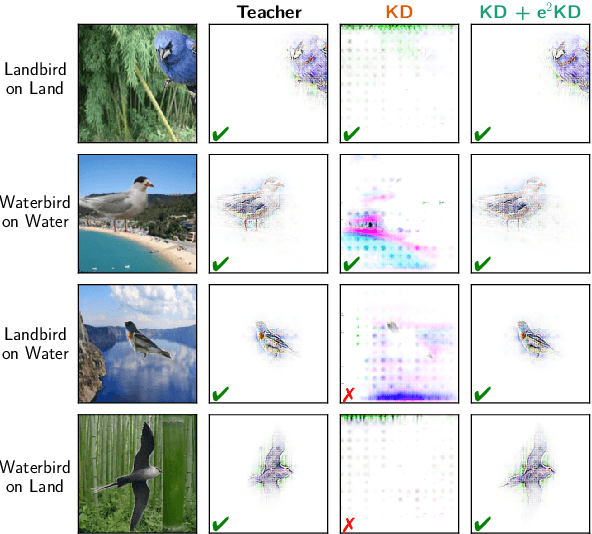
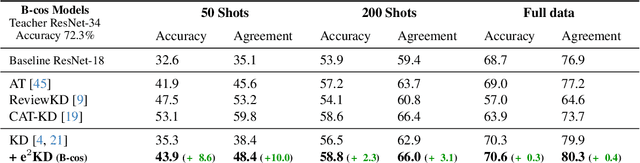

Knowledge Distillation (KD) has proven effective for compressing large teacher models into smaller student models. While it is well known that student models can achieve similar accuracies as the teachers, it has also been shown that they nonetheless often do not learn the same function. It is, however, often highly desirable that the student's and teacher's functions share similar properties such as basing the prediction on the same input features, as this ensures that students learn the 'right features' from the teachers. In this work, we explore whether this can be achieved by not only optimizing the classic KD loss but also the similarity of the explanations generated by the teacher and the student. Despite the idea being simple and intuitive, we find that our proposed 'explanation-enhanced' KD (e$^2$KD) (1) consistently provides large gains in terms of accuracy and student-teacher agreement, (2) ensures that the student learns from the teacher to be right for the right reasons and to give similar explanations, and (3) is robust with respect to the model architectures, the amount of training data, and even works with 'approximate', pre-computed explanations.
B-cos Alignment for Inherently Interpretable CNNs and Vision Transformers
Jun 19, 2023
We present a new direction for increasing the interpretability of deep neural networks (DNNs) by promoting weight-input alignment during training. For this, we propose to replace the linear transformations in DNNs by our novel B-cos transformation. As we show, a sequence (network) of such transformations induces a single linear transformation that faithfully summarises the full model computations. Moreover, the B-cos transformation is designed such that the weights align with relevant signals during optimisation. As a result, those induced linear transformations become highly interpretable and highlight task-relevant features. Importantly, the B-cos transformation is designed to be compatible with existing architectures and we show that it can easily be integrated into virtually all of the latest state of the art models for computer vision - e.g. ResNets, DenseNets, ConvNext models, as well as Vision Transformers - by combining the B-cos-based explanations with normalisation and attention layers, all whilst maintaining similar accuracy on ImageNet. Finally, we show that the resulting explanations are of high visual quality and perform well under quantitative interpretability metrics.
Temperature Schedules for Self-Supervised Contrastive Methods on Long-Tail Data
Mar 23, 2023Most approaches for self-supervised learning (SSL) are optimised on curated balanced datasets, e.g. ImageNet, despite the fact that natural data usually exhibits long-tail distributions. In this paper, we analyse the behaviour of one of the most popular variants of SSL, i.e. contrastive methods, on long-tail data. In particular, we investigate the role of the temperature parameter $\tau$ in the contrastive loss, by analysing the loss through the lens of average distance maximisation, and find that a large $\tau$ emphasises group-wise discrimination, whereas a small $\tau$ leads to a higher degree of instance discrimination. While $\tau$ has thus far been treated exclusively as a constant hyperparameter, in this work, we propose to employ a dynamic $\tau$ and show that a simple cosine schedule can yield significant improvements in the learnt representations. Such a schedule results in a constant `task switching' between an emphasis on instance discrimination and group-wise discrimination and thereby ensures that the model learns both group-wise features, as well as instance-specific details. Since frequent classes benefit from the former, while infrequent classes require the latter, we find this method to consistently improve separation between the classes in long-tail data without any additional computational cost.
Better Understanding Differences in Attribution Methods via Systematic Evaluations
Mar 21, 2023Deep neural networks are very successful on many vision tasks, but hard to interpret due to their black box nature. To overcome this, various post-hoc attribution methods have been proposed to identify image regions most influential to the models' decisions. Evaluating such methods is challenging since no ground truth attributions exist. We thus propose three novel evaluation schemes to more reliably measure the faithfulness of those methods, to make comparisons between them more fair, and to make visual inspection more systematic. To address faithfulness, we propose a novel evaluation setting (DiFull) in which we carefully control which parts of the input can influence the output in order to distinguish possible from impossible attributions. To address fairness, we note that different methods are applied at different layers, which skews any comparison, and so evaluate all methods on the same layers (ML-Att) and discuss how this impacts their performance on quantitative metrics. For more systematic visualizations, we propose a scheme (AggAtt) to qualitatively evaluate the methods on complete datasets. We use these evaluation schemes to study strengths and shortcomings of some widely used attribution methods over a wide range of models. Finally, we propose a post-processing smoothing step that significantly improves the performance of some attribution methods, and discuss its applicability.
Using Explanations to Guide Models
Mar 21, 2023



Deep neural networks are highly performant, but might base their decision on spurious or background features that co-occur with certain classes, which can hurt generalization. To mitigate this issue, the usage of 'model guidance' has gained popularity recently: for this, models are guided to be "right for the right reasons" by regularizing the models' explanations to highlight the right features. Experimental validation of these approaches has thus far however been limited to relatively simple and / or synthetic datasets. To gain a better understanding of which model-guiding approaches actually transfer to more challenging real-world datasets, in this work we conduct an in-depth evaluation across various loss functions, attribution methods, models, and 'guidance depths' on the PASCAL VOC 2007 and MS COCO 2014 datasets, and show that model guidance can sometimes even improve model performance. In this context, we further propose a novel energy loss, show its effectiveness in directing the model to focus on object features. We also show that these gains can be achieved even with a small fraction (e.g. 1%) of bounding box annotations, highlighting the cost effectiveness of this approach. Lastly, we show that this approach can also improve generalization under distribution shifts. Code will be made available.
Holistically Explainable Vision Transformers
Jan 20, 2023



Transformers increasingly dominate the machine learning landscape across many tasks and domains, which increases the importance for understanding their outputs. While their attention modules provide partial insight into their inner workings, the attention scores have been shown to be insufficient for explaining the models as a whole. To address this, we propose B-cos transformers, which inherently provide holistic explanations for their decisions. Specifically, we formulate each model component - such as the multi-layer perceptrons, attention layers, and the tokenisation module - to be dynamic linear, which allows us to faithfully summarise the entire transformer via a single linear transform. We apply our proposed design to Vision Transformers (ViTs) and show that the resulting models, dubbed Bcos-ViTs, are highly interpretable and perform competitively to baseline ViTs on ImageNet. Code will be made available soon.