 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-cos Alignment for Inherently Interpretable CNNs and Vision Transformers
Jun 19, 2023
We present a new direction for increasing the interpretability of deep neural networks (DNNs) by promoting weight-input alignment during training. For this, we propose to replace the linear transformations in DNNs by our novel B-cos transformation. As we show, a sequence (network) of such transformations induces a single linear transformation that faithfully summarises the full model computations. Moreover, the B-cos transformation is designed such that the weights align with relevant signals during optimisation. As a result, those induced linear transformations become highly interpretable and highlight task-relevant features. Importantly, the B-cos transformation is designed to be compatible with existing architectures and we show that it can easily be integrated into virtually all of the latest state of the art models for computer vision - e.g. ResNets, DenseNets, ConvNext models, as well as Vision Transformers - by combining the B-cos-based explanations with normalisation and attention layers, all whilst maintaining similar accuracy on ImageNet. Finally, we show that the resulting explanations are of high visual quality and perform well under quantitative interpretability metrics.
White-Box Attacks on Hate-speech BERT Classifiers in German with Explicit and Implicit Character Level Defense
Feb 14, 2022


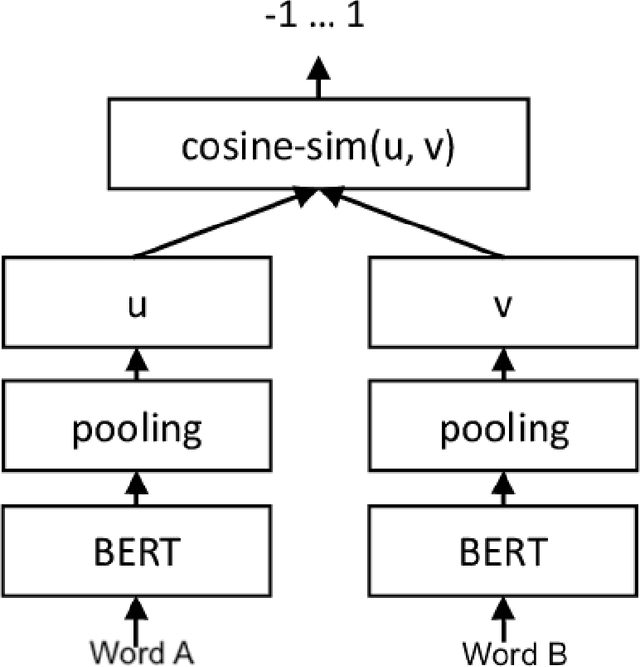
In this work, we evaluate the adversarial robustness of BERT models trained on German Hate Speech datasets. We also complement our evaluation with two novel white-box character and word level attacks thereby contributing to the range of attacks available. Furthermore, we also perform a comparison of two novel character-level defense strategies and evaluate their robustness with one another.