Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite-Box Attacks on Hate-speech BERT Classifiers in German with Explicit and Implicit Character Level Defense
Paper and Code



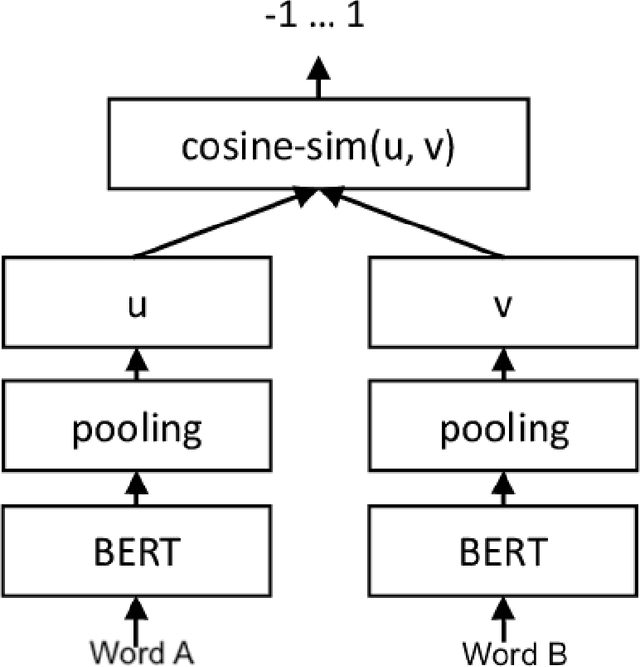
In this work, we evaluate the adversarial robustness of BERT models trained on German Hate Speech datasets. We also complement our evaluation with two novel white-box character and word level attacks thereby contributing to the range of attacks available. Furthermore, we also perform a comparison of two novel character-level defense strategies and evaluate their robustness with one another.
View paper on