 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASA: Cross-Attention via Self-Attention for Efficient Vision-Language Fusion
Dec 22, 2025Vision-language models (VLMs) are commonly trained by inserting image tokens from a pretrained vision encoder into the textual stream of a language model. This allows text and image information to fully attend to one another within the model, but becomes extremely costly for high-resolution images, long conversations, or streaming videos, both in memory and compute. VLMs leveraging cross-attention are an efficient alternative to token insertion but exhibit a clear performance gap, in particular on tasks involving fine-grained visual details. We find that a key to improving such models is to also enable local text-to-text interaction in the dedicated cross-attention layers. Building on this, we propose CASA, Cross-Attention via Self-Attention, a simple and efficient paradigm which substantially reduces the gap with full token insertion on common image understanding benchmarks, while enjoying the same scalability as cross-attention models when applied to long-context multimodal tasks such as streaming video captioning. For samples and code, please see our project page at https://kyutai.org/casa .
Vision-Speech Models: Teaching Speech Models to Converse about Images
Mar 19, 2025The recent successes of Vision-Language models raise the question of how to equivalently imbue a pretrained speech model with vision understanding, an important milestone towards building a multimodal speech model able to freely converse about images. Building such a conversational Vision-Speech model brings its unique challenges: (i) paired image-speech datasets are much scarcer than their image-text counterparts, (ii) ensuring real-time latency at inference is crucial thus bringing compute and memory constraints, and (iii) the model should preserve prosodic features (e.g., speaker tone) which cannot be inferred from text alone. In this work, we introduce MoshiVis, augmenting a recent dialogue speech LLM, Moshi, with visual inputs through lightweight adaptation modules. An additional dynamic gating mechanism enables the model to more easily switch between the visual inputs and unrelated conversation topics. To reduce training costs, we design a simple one-stage, parameter-efficient fine-tuning pipeline in which we leverage a mixture of image-text (i.e., "speechless") and image-speech samples. We evaluate the model on downstream visual understanding tasks with both audio and text prompts, and report qualitative samples of interactions with MoshiVis. Our inference code will be made available, as well as the image-speech data used for audio evaluation.
Knowledge distillation: A good teacher is patient and consistent
Jun 09, 2021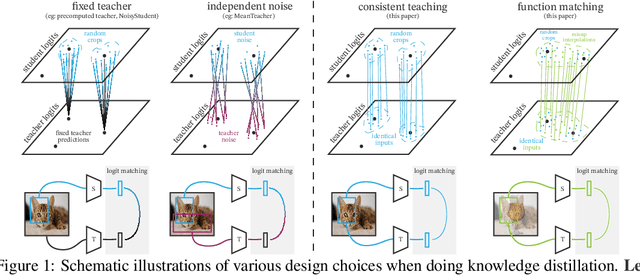
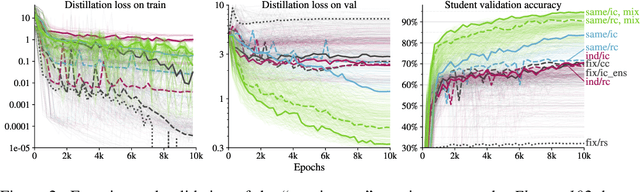

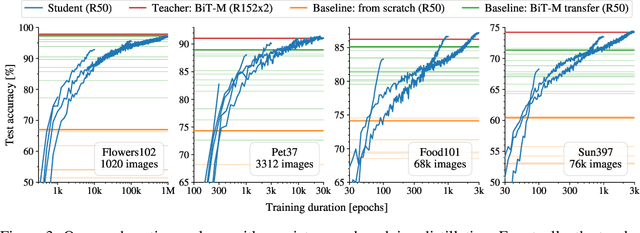
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we address this issue and significantly bridge the gap between these two types of models. Throughout our empirical investigation we do not aim to necessarily propose a new method, but strive to identify a robust and effective recipe for making state-of-the-art large scale models affordable in practice. We demonstrate that, when performed correctly, knowledge distillation can be a powerful tool for reducing the size of large models without compromising their performance. In particular, we uncover that there are certain implicit design choices, which may drastically affect the effectiveness of distillation. Our key contribution is the explicit identification of these design choices, which were not previously articulated in the literature. We back up our findings by a comprehensive empirical study, demonstrate compelling results on a wide range of vision datasets and, in particular, obtain a state-of-the-art ResNet-50 model for ImageNet, which achieves 82.8\% top-1 accuracy.
XGAN: Unsupervised Image-to-Image Translation for Many-to-Many Mappings
Jul 10, 2018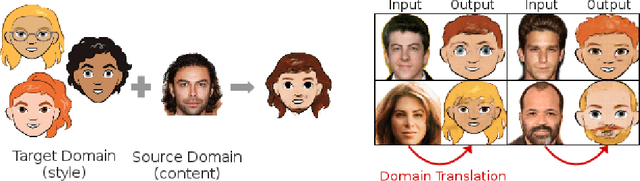

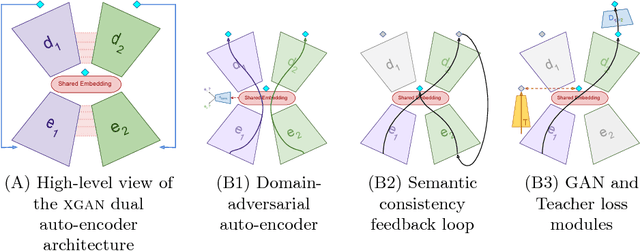

Style transfer usually refers to the task of applying color and texture information from a specific style image to a given content image while preserving the structure of the latter. Here we tackle the more generic problem of semantic style transfer: given two unpaired collections of images, we aim to learn a mapping between the corpus-level style of each collection, while preserving semantic content shared across the two domains. We introduce XGAN ("Cross-GAN"), a dual adversarial autoencoder, which captures a shared representation of the common domain semantic content in an unsupervised way, while jointly learning the domain-to-domain image translations in both directions. We exploit ideas from the domain adaptation literature and define a semantic consistency loss which encourages the model to preserve semantics in the learned embedding space. We report promising qualitative results for the task of face-to-cartoon translation. The cartoon dataset, CartoonSet, we collected for this purpose is publicly available at google.github.io/cartoonset/ as a new benchmark for semantic style transfer.