 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Sep 10, 2025We introduce Delayed Streams Modeling (DSM), a flexible formulation for streaming, multimodal sequence-to-sequence learning. Sequence-to-sequence generation is often cast in an offline manner, where the model consumes the complete input sequence before generating the first output timestep. Alternatively, streaming sequence-to-sequence rely on learning a policy for choosing when to advance on the input stream, or write to the output stream. DSM instead models already time-aligned streams with a decoder-only language model. By moving the alignment to a pre-processing step,and introducing appropriate delays between streams, DSM provides streaming inference of arbitrary output sequences, from any input combination, making it applicable to many sequence-to-sequence problems. In particular, given text and audio streams, automatic speech recognition (ASR) corresponds to the text stream being delayed, while the opposite gives a text-to-speech (TTS) model. We perform extensive experiments for these two major sequence-to-sequence tasks, showing that DSM provides state-of-the-art performance and latency while supporting arbitrary long sequences, being even competitive with offline baselines. Code, samples and demos are available at https://github.com/kyutai-labs/delayed-streams-modeling
Continuous Audio Language Models
Sep 09, 2025Audio Language Models (ALM) have emerged as the dominant paradigm for speech and music generation by representing audio as sequences of discrete tokens. Yet, unlike text tokens, which are invertible, audio tokens are extracted from lossy codecs with a limited bitrate. As a consequence, increasing audio quality requires generating more tokens, which imposes a trade-off between fidelity and computational cost. We address this issue by studying Continuous Audio Language Models (CALM). These models instantiate a large Transformer backbone that produces a contextual embedding at every timestep. This sequential information then conditions an MLP that generates the next continuous frame of an audio VAE through consistency modeling. By avoiding lossy compression, CALM achieves higher quality at lower computational cost than their discrete counterpart. Experiments on speech and music demonstrate improved efficiency and fidelity over state-of-the-art discrete audio language models, facilitating lightweight, high-quality audio generation. Samples are available at hf.co/spaces/kyutai/calm-samples
Aligning Spoken Dialogue Models from User Interactions
Jun 26, 2025We propose a novel preference alignment framework for improving spoken dialogue models on real-time conversations from user interactions. Current preference learning methods primarily focus on text-based language models, and are not directly suited to the complexities of real-time speech interactions, with richer dynamics (e.g. interruption, interjection) and no explicit segmentation between speaker turns.We create a large-scale dataset of more than 150,000 preference pairs from raw multi-turn speech conversations, annotated with AI feedback, to cover preferences over both linguistic content and temporal context variations. We leverage offline alignment methods to finetune a full-duplex autoregressive speech-to-speech model. Extensive experiments demonstrate that feedback on generic conversations can be consistently effective in improving spoken dialogue models to produce more factual, safer and more contextually aligned interactions. We deploy the finetuned model and conduct holistic human evaluations to assess the impact beyond single-turn conversations. Our findings shed light on the importance of a well-calibrated balance among various dynamics, crucial for natural real-time speech dialogue systems.
Vision-Speech Models: Teaching Speech Models to Converse about Images
Mar 19, 2025The recent successes of Vision-Language models raise the question of how to equivalently imbue a pretrained speech model with vision understanding, an important milestone towards building a multimodal speech model able to freely converse about images. Building such a conversational Vision-Speech model brings its unique challenges: (i) paired image-speech datasets are much scarcer than their image-text counterparts, (ii) ensuring real-time latency at inference is crucial thus bringing compute and memory constraints, and (iii) the model should preserve prosodic features (e.g., speaker tone) which cannot be inferred from text alone. In this work, we introduce MoshiVis, augmenting a recent dialogue speech LLM, Moshi, with visual inputs through lightweight adaptation modules. An additional dynamic gating mechanism enables the model to more easily switch between the visual inputs and unrelated conversation topics. To reduce training costs, we design a simple one-stage, parameter-efficient fine-tuning pipeline in which we leverage a mixture of image-text (i.e., "speechless") and image-speech samples. We evaluate the model on downstream visual understanding tasks with both audio and text prompts, and report qualitative samples of interactions with MoshiVis. Our inference code will be made available, as well as the image-speech data used for audio evaluation.
High-Fidelity Simultaneous Speech-To-Speech Translation
Feb 05, 2025



We introduce Hibiki, a decoder-only model for simultaneous speech translation. Hibiki leverages a multistream language model to synchronously process source and target speech, and jointly produces text and audio tokens to perform speech-to-text and speech-to-speech translation. We furthermore address the fundamental challenge of simultaneous interpretation, which unlike its consecutive counterpart, where one waits for the end of the source utterance to start translating, adapts its flow to accumulate just enough context to produce a correct translation in real-time, chunk by chunk. To do so, we introduce a weakly-supervised method that leverages the perplexity of an off-the-shelf text translation system to identify optimal delays on a per-word basis and create aligned synthetic data. After supervised training, Hibiki performs adaptive, simultaneous speech translation with vanilla temperature sampling. On a French-English simultaneous speech translation task, Hibiki demonstrates state-of-the-art performance in translation quality, speaker fidelity and naturalness. Moreover, the simplicity of its inference process makes it compatible with batched translation and even real-time on-device deployment. We provide examples as well as models and inference code.
Audio Conditioning for Music Generation via Discrete Bottleneck Features
Jul 17, 2024While most music generation models use textual or parametric conditioning (e.g. tempo, harmony, musical genre), we propose to condition a language model based music generation system with audio input. Our exploration involves two distinct strategies. The first strategy, termed textual inversion, leverages a pre-trained text-to-music model to map audio input to corresponding "pseudowords" in the textual embedding space. For the second model we train a music language model from scratch jointly with a text conditioner and a quantized audio feature extractor. At inference time, we can mix textual and audio conditioning and balance them thanks to a novel double classifier free guidance method. We conduct automatic and human studies that validates our approach. We will release the code and we provide music samples on https://musicgenstyle.github.io in order to show the quality of our model.
Proactive Detection of Voice Cloning with Localized Watermarking
Jan 30, 2024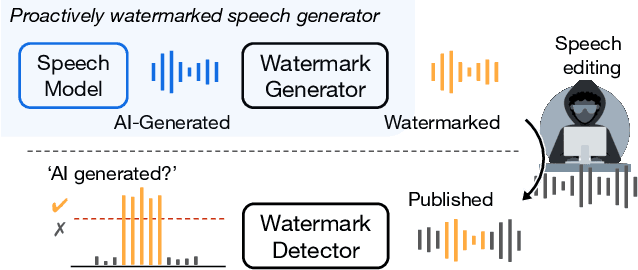
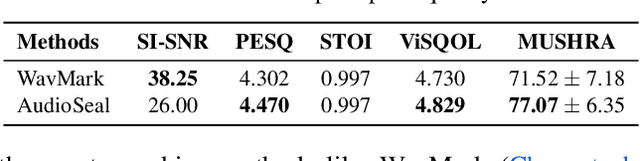
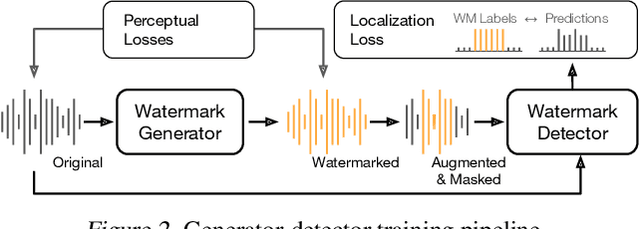
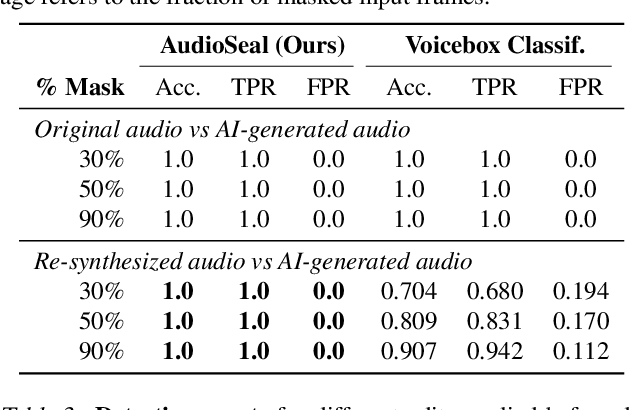
In the rapidly evolving field of speech generative models, there is a pressing need to ensure audio authenticity against the risks of voice cloning. We present AudioSeal, the first audio watermarking technique designed specifically for localized detection of AI-generated speech. AudioSeal employs a generator/detector architecture trained jointly with a localization loss to enable localized watermark detection up to the sample level, and a novel perceptual loss inspired by auditory masking, that enables AudioSeal to achieve better imperceptibility. AudioSeal achieves state-of-the-art performance in terms of robustness to real life audio manipulations and imperceptibility based on automatic and human evaluation metrics. Additionally, AudioSeal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed - achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications.
Masked Audio Generation using a Single Non-Autoregressive Transformer
Jan 09, 2024We introduce MAGNeT, a masked generative sequence modeling method that operates directly over several streams of audio tokens. Unlike prior work, MAGNeT is comprised of a single-stage, non-autoregressive transformer. During training, we predict spans of masked tokens obtained from a masking scheduler, while during inference we gradually construct the output sequence using several decoding steps. To further enhance the quality of the generated audio, we introduce a novel rescoring method in which, we leverage an external pre-trained model to rescore and rank predictions from MAGNeT, which will be then used for later decoding steps. Lastly, we explore a hybrid version of MAGNeT, in which we fuse between autoregressive and non-autoregressive models to generate the first few seconds in an autoregressive manner while the rest of the sequence is being decoded in parallel. We demonstrate the efficiency of MAGNeT for the task of text-to-music and text-to-audio generation and conduct an extensive empirical evaluation, considering both objective metrics and human studies. The proposed approach is comparable to the evaluated baselines, while being significantly faster (x7 faster than the autoregressive baseline). Through ablation studies and analysis, we shed light on the importance of each of the components comprising MAGNeT, together with pointing to the trade-offs between autoregressive and non-autoregressive modeling, considering latency, throughput, and generation quality. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT.
Code Llama: Open Foundation Models for Code
Aug 25, 2023
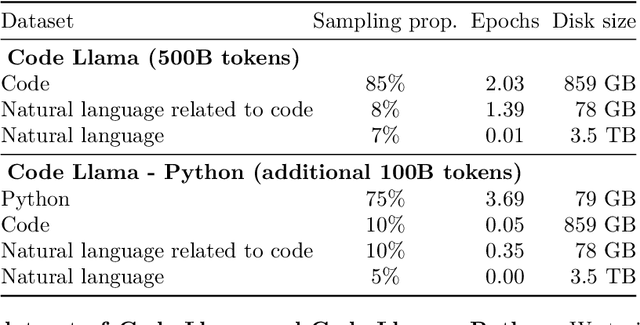
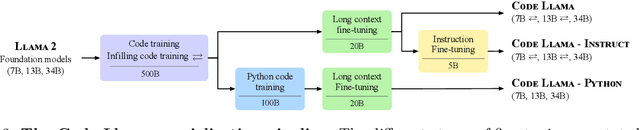
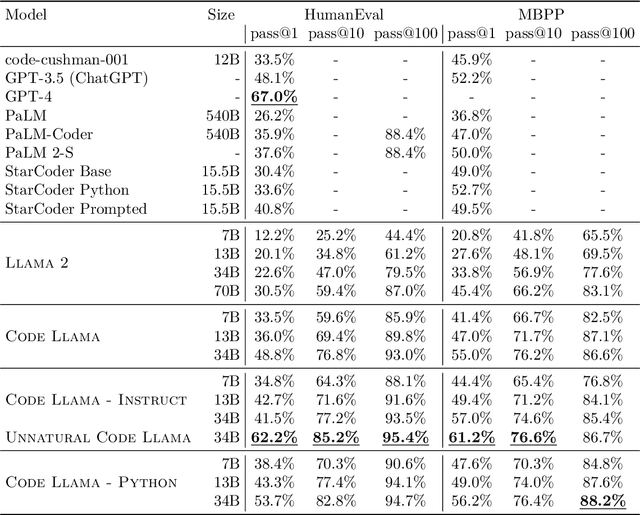
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023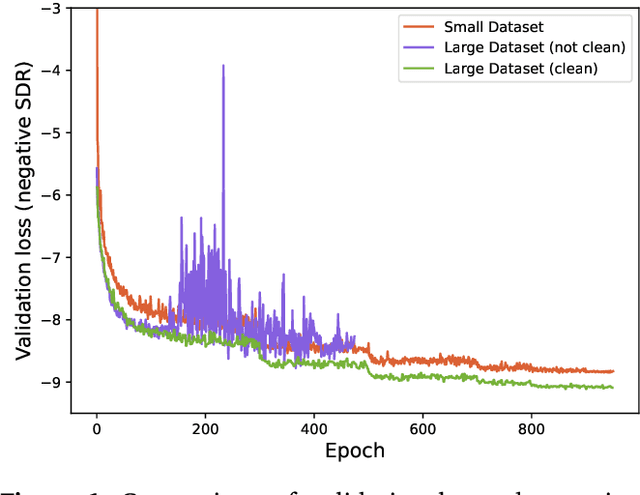
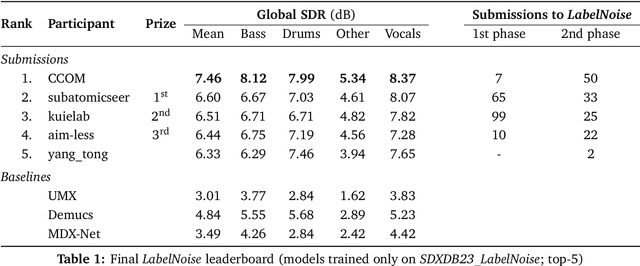

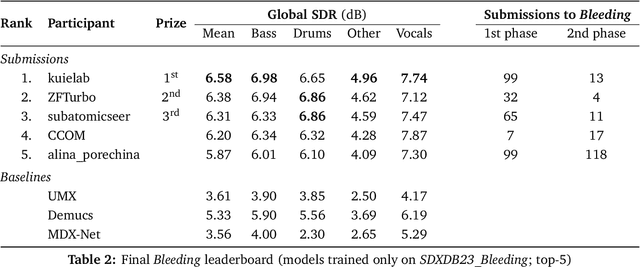
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.