 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIBE: TRImodal Brain Encoder for whole-brain fMRI response prediction
Jul 29, 2025Historically, neuroscience has progressed by fragmenting into specialized domains, each focusing on isolated modalities, tasks, or brain regions. While fruitful, this approach hinders the development of a unified model of cognition. Here, we introduce TRIBE, the first deep neural network trained to predict brain responses to stimuli across multiple modalities, cortical areas and individuals. By combining the pretrained representations of text, audio and video foundational models and handling their time-evolving nature with a transformer, our model can precisely model the spatial and temporal fMRI responses to videos, achieving the first place in the Algonauts 2025 brain encoding competition with a significant margin over competitors. Ablations show that while unimodal models can reliably predict their corresponding cortical networks (e.g. visual or auditory networks), they are systematically outperformed by our multimodal model in high-level associative cortices. Currently applied to perception and comprehension, our approach paves the way towards building an integrative model of representations in the human brain. Our code is available at https://github.com/facebookresearch/algonauts-2025.
Brain-to-Text Decoding: A Non-invasive Approach via Typing
Feb 18, 2025Modern neuroprostheses can now restore communication in patients who have lost the ability to speak or move. However, these invasive devices entail risks inherent to neurosurgery. Here, we introduce a non-invasive method to decode the production of sentences from brain activity and demonstrate its efficacy in a cohort of 35 healthy volunteers. For this, we present Brain2Qwerty, a new deep learning architecture trained to decode sentences from either electro- (EEG) or magneto-encephalography (MEG), while participants typed briefly memorized sentences on a QWERTY keyboard. With MEG, Brain2Qwerty reaches, on average, a character-error-rate (CER) of 32% and substantially outperforms EEG (CER: 67%). For the best participants, the model achieves a CER of 19%, and can perfectly decode a variety of sentences outside of the training set. While error analyses suggest that decoding depends on motor processes, the analysis of typographical errors suggests that it also involves higher-level cognitive factors. Overall, these results narrow the gap between invasive and non-invasive methods and thus open the path for developing safe brain-computer interfaces for non-communicating patients.
Decoding individual words from non-invasive brain recordings across 723 participants
Dec 11, 2024Deep learning has recently enabled the decoding of language from the neural activity of a few participants with electrodes implanted inside their brain. However, reliably decoding words from non-invasive recordings remains an open challenge. To tackle this issue, we introduce a novel deep learning pipeline to decode individual words from non-invasive electro- (EEG) and magneto-encephalography (MEG) signals. We train and evaluate our approach on an unprecedentedly large number of participants (723) exposed to five million words either written or spoken in English, French or Dutch. Our model outperforms existing methods consistently across participants, devices, languages, and tasks, and can decode words absent from the training set. Our analyses highlight the importance of the recording device and experimental protocol: MEG and reading are easier to decode than EEG and listening, respectively, and it is preferable to collect a large amount of data per participant than to repeat stimuli across a large number of participants. Furthermore, decoding performance consistently increases with the amount of (i) data used for training and (ii) data used for averaging during testing. Finally, single-word predictions show that our model effectively relies on word semantics but also captures syntactic and surface properties such as part-of-speech, word length and even individual letters, especially in the reading condition. Overall, our findings delineate the path and remaining challenges towards building non-invasive brain decoders for natural language.
Aligning brain functions boosts the decoding of visual semantics in novel subjects
Dec 11, 2023Deep learning is leading to major advances in the realm of brain decoding from functional Magnetic Resonance Imaging (fMRI). However, the large inter-subject variability in brain characteristics has limited most studies to train models on one subject at a time. Consequently, this approach hampers the training of deep learning models, which typically requires very large datasets. Here, we propose to boost brain decoding by aligning brain responses to videos and static images across subjects. Compared to the anatomically-aligned baseline, our method improves out-of-subject decoding performance by up to 75%. Moreover, it also outperforms classical single-subject approaches when fewer than 100 minutes of data is available for the tested subject. Furthermore, we propose a new multi-subject alignment method, which obtains comparable results to that of classical single-subject approaches while improving out-of-subject generalization. Finally, we show that this method aligns neural representations in accordance with brain anatomy. Overall, this study lays the foundations for leveraging extensive neuroimaging datasets and enhancing the decoding of individuals with a limited amount of brain recordings.
Optimizing with Low Budgets: a Comparison on the Black-box Optimization Benchmarking Suite and OpenAI Gym
Oct 09, 2023The growing ubiquity of machine learning (ML) has led it to enter various areas of computer science, including black-box optimization (BBO). Recent research is particularly concerned with Bayesian optimization (BO). BO-based algorithms are popular in the ML community, as they are used for hyperparameter optimization and more generally for algorithm configuration. However, their efficiency decreases as the dimensionality of the problem and the budget of evaluations increase. Meanwhile, derivative-free optimization methods have evolved independently in the optimization community. Therefore, we urge to understand whether cross-fertilization is possible between the two communities, ML and BBO, i.e., whether algorithms that are heavily used in ML also work well in BBO and vice versa. Comparative experiments often involve rather small benchmarks and show visible problems in the experimental setup, such as poor initialization of baselines, overfitting due to problem-specific setting of hyperparameters, and low statistical significance. With this paper, we update and extend a comparative study presented by Hutter et al. in 2013. We compare BBO tools for ML with more classical heuristics, first on the well-known BBOB benchmark suite from the COCO environment and then on Direct Policy Search for OpenAI Gym, a reinforcement learning benchmark. Our results confirm that BO-based optimizers perform well on both benchmarks when budgets are limited, albeit with a higher computational cost, while they are often outperformed by algorithms from other families when the evaluation budget becomes larger. We also show that some algorithms from the BBO community perform surprisingly well on ML tasks.
Code Llama: Open Foundation Models for Code
Aug 25, 2023
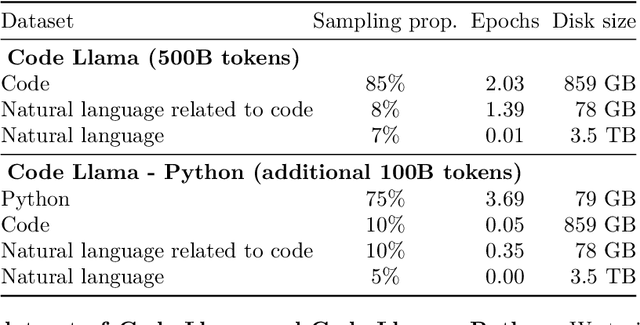
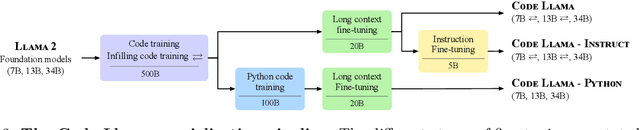
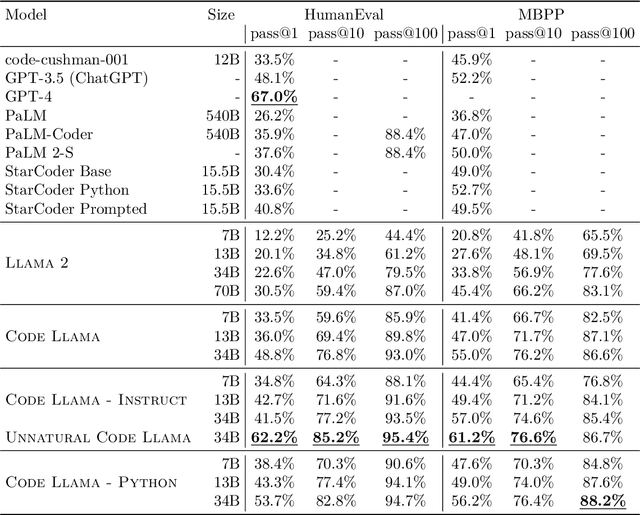
We release Code Llama, a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models, infilling capabilities, support for large input contexts, and zero-shot instruction following ability for programming tasks. We provide multiple flavors to cover a wide range of applications: foundation models (Code Llama), Python specializations (Code Llama - Python), and instruction-following models (Code Llama - Instruct) with 7B, 13B and 34B parameters each. All models are trained on sequences of 16k tokens and show improvements on inputs with up to 100k tokens. 7B and 13B Code Llama and Code Llama - Instruct variants support infilling based on surrounding content. Code Llama reaches state-of-the-art performance among open models on several code benchmarks, with scores of up to 53% and 55% on HumanEval and MBPP, respectively. Notably, Code Llama - Python 7B outperforms Llama 2 70B on HumanEval and MBPP, and all our models outperform every other publicly available model on MultiPL-E. We release Code Llama under a permissive license that allows for both research and commercial use.
Does Zero-Shot Reinforcement Learning Exist?
Sep 29, 2022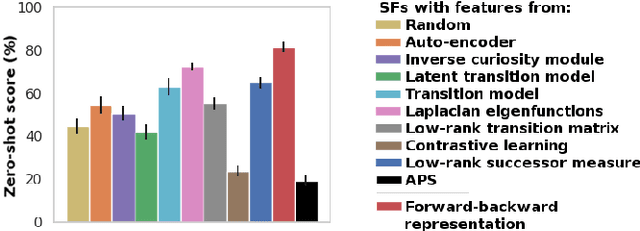

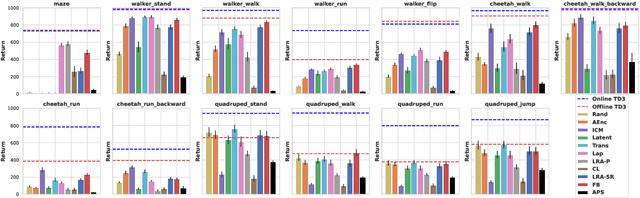
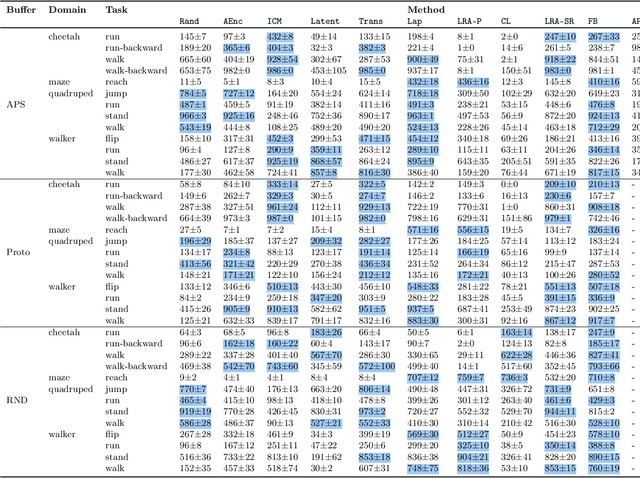
A zero-shot RL agent is an agent that can solve any RL task in a given environment, instantly with no additional planning or learning, after an initial reward-free learning phase. This marks a shift from the reward-centric RL paradigm towards "controllable" agents that can follow arbitrary instructions in an environment. Current RL agents can solve families of related tasks at best, or require planning anew for each task. Strategies for approximate zero-shot RL ave been suggested using successor features (SFs) [BBQ+ 18] or forward-backward (FB) representations [TO21], but testing has been limited. After clarifying the relationships between these schemes, we introduce improved losses and new SF models, and test the viability of zero-shot RL schemes systematically on tasks from the Unsupervised RL benchmark [LYL+21]. To disentangle universal representation learning from exploration, we work in an offline setting and repeat the tests on several existing replay buffers. SFs appear to suffer from the choice of the elementary state features. SFs with Laplacian eigenfunctions do well, while SFs based on auto-encoders, inverse curiosity, transition models, low-rank transition matrix, contrastive learning, or diversity (APS), perform unconsistently. In contrast, FB representations jointly learn the elementary and successor features from a single, principled criterion. They perform best and consistently across the board, reaching 85% of supervised RL performance with a good replay buffer, in a zero-shot manner.
Decoding speech from non-invasive brain recordings
Aug 25, 2022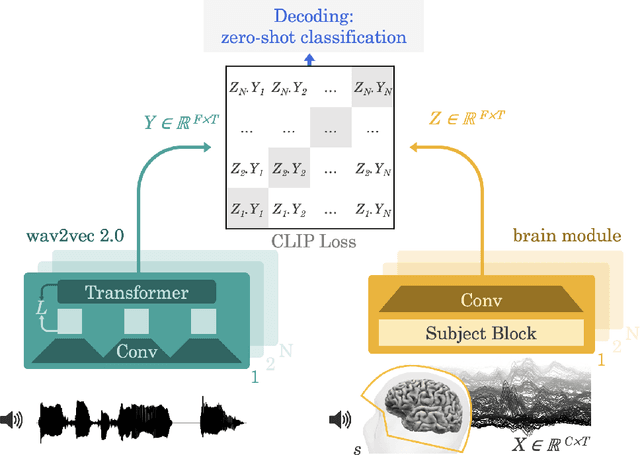

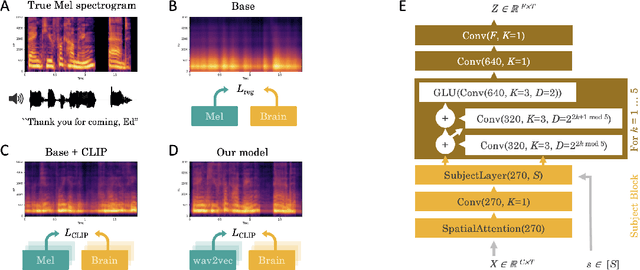

Decoding language from brain activity is a long-awaited goal in both healthcare and neuroscience. Major milestones have recently been reached thanks to intracranial devices: subject-specific pipelines trained on invasive brain responses to basic language tasks now start to efficiently decode interpretable features (e.g. letters, words, spectrograms). However, scaling this approach to natural speech and non-invasive brain recordings remains a major challenge. Here, we propose a single end-to-end architecture trained with contrastive learning across a large cohort of individuals to predict self-supervised representations of natural speech. We evaluate our model on four public datasets, encompassing 169 volunteers recorded with magneto- or electro-encephalography (M/EEG), while they listened to natural speech. The results show that our model can identify, from 3s of MEG signals, the corresponding speech segment with up to 72.5% top-10 accuracy out of 1,594 distinct segments (and 44% top-1 accuracy), and up to 19.1% out of 2,604 segments for EEG recordings -- hence allowing the decoding of phrases absent from the training set. Model comparison and ablation analyses show that these performances directly benefit from our original design choices, namely the use of (i) a contrastive objective, (ii) pretrained representations of speech and (iii) a common convolutional architecture simultaneously trained across several participants. Together, these results delineate a promising path to decode natural language processing in real time from non-invasive recordings of brain activity.
Population Based Training for Data Augmentation and Regularization in Speech Recognition
Oct 08, 2020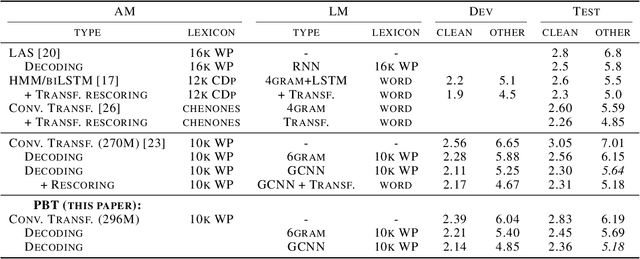
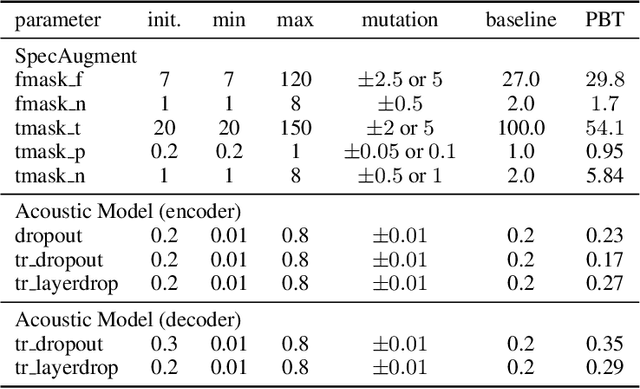
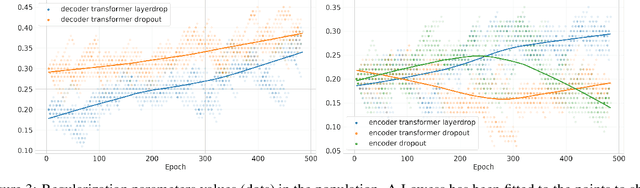
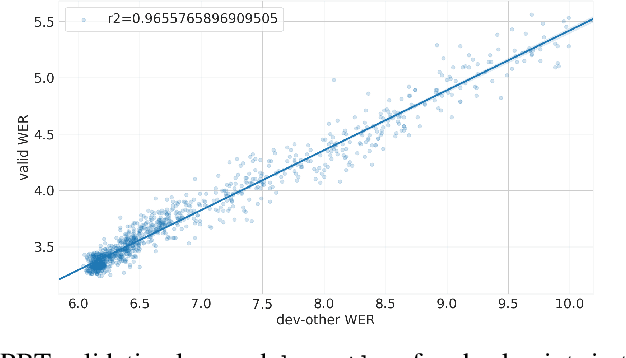
Varying data augmentation policies and regularization over the course of optimization has led to performance improvements over using fixed values. We show that population based training is a useful tool to continuously search those hyperparameters, within a fixed budget. This greatly simplifies the experimental burden and computational cost of finding such optimal schedules. We experiment in speech recognition by optimizing SpecAugment this way, as well as dropout. It compares favorably to a baseline that does not change those hyperparameters over the course of training, with an 8% relative WER improvement. We obtain 5.18% word error rate on LibriSpeech's test-other.
Inspirational Adversarial Image Generation
Jun 17, 2019

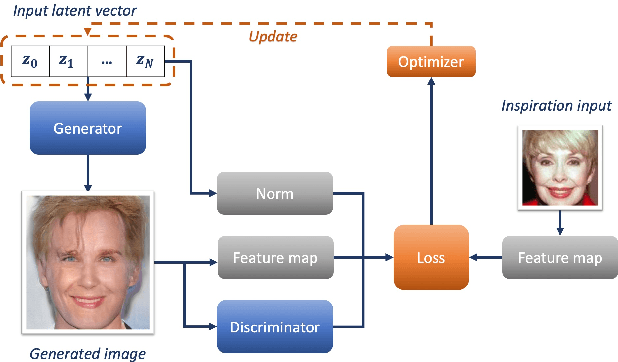
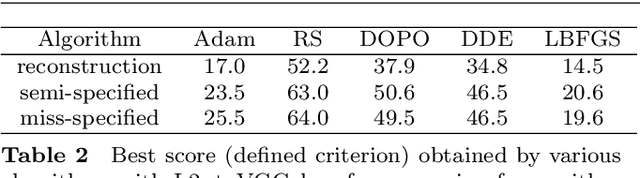
The task of image generation started to receive some attention from artists and designers to inspire them in new creations. However, exploiting the results of deep generative models such as Generative Adversarial Networks can be long and tedious given the lack of existing tools. In this work, we propose a simple strategy to inspire creators with new generations learned from a dataset of their choice, while providing some control on them. We design a simple optimization method to find the optimal latent parameters corresponding to the closest generation to any input inspirational image. Specifically, we allow the generation given an inspirational image of the user choice by performing several optimization steps to recover optimal parameters from the model's latent space. We tested several exploration methods starting with classic gradient descents to gradient-free optimizers. Many gradient-free optimizers just need comparisons (better/worse than another image), so that they can even be used without numerical criterion, without inspirational image, but with only with human preference. Thus, by iterating on one's preferences we could make robust Facial Composite or Fashion Generation algorithms. High resolution of the produced design generations are obtained using progressive growing of GANs. Our results on four datasets of faces, fashion images, and textures show that satisfactory images are effectively retrieved in most cases.