 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling the Inherent Difficulty of Noise Filtering in RAG
Jan 06, 2026Retrieval-Augmented Generation (RAG) has become a widely adopted approach to enhance Large Language Models (LLMs) by incorporating external knowledge and reducing hallucinations. However, noisy or irrelevant documents are often introduced during RAG, potentially degrading performance and even causing hallucinated outputs. While various methods have been proposed to filter out such noise, we argue that identifying irrelevant information from retrieved content is inherently difficult and limited number of transformer layers can hardly solve this. Consequently, retrievers fail to filter out irrelevant documents entirely. Therefore, LLMs must be robust against such noise, but we demonstrate that standard fine-tuning approaches are often ineffective in enabling the model to selectively utilize relevant information while ignoring irrelevant content due to the structural constraints of attention patterns. To address this, we propose a novel fine-tuning method designed to enhance the model's ability to distinguish between relevant and irrelevant information within retrieved documents. Extensive experiments across multiple benchmarks show that our approach significantly improves the robustness and performance of LLMs.
Deep Deterministic Nonlinear ICA via Total Correlation Minimization with Matrix-Based Entropy Functional
Dec 31, 2025Blind source separation, particularly through independent component analysis (ICA), is widely utilized across various signal processing domains for disentangling underlying components from observed mixed signals, owing to its fully data-driven nature that minimizes reliance on prior assumptions. However, conventional ICA methods rely on an assumption of linear mixing, limiting their ability to capture complex nonlinear relationships and to maintain robustness in noisy environments. In this work, we present deep deterministic nonlinear independent component analysis (DDICA), a novel deep neural network-based framework designed to address these limitations. DDICA leverages a matrix-based entropy function to directly optimize the independence criterion via stochastic gradient descent, bypassing the need for variational approximations or adversarial schemes. This results in a streamlined training process and improved resilience to noise. We validated the effectiveness and generalizability of DDICA across a range of applications, including simulated signal mixtures, hyperspectral image unmixing, modeling of primary visual receptive fields, and resting-state functional magnetic resonance imaging (fMRI) data analysis. Experimental results demonstrate that DDICA effectively separates independent components with high accuracy across a range of applications. These findings suggest that DDICA offers a robust and versatile solution for blind source separation in diverse signal processing tasks.
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Dec 16, 2025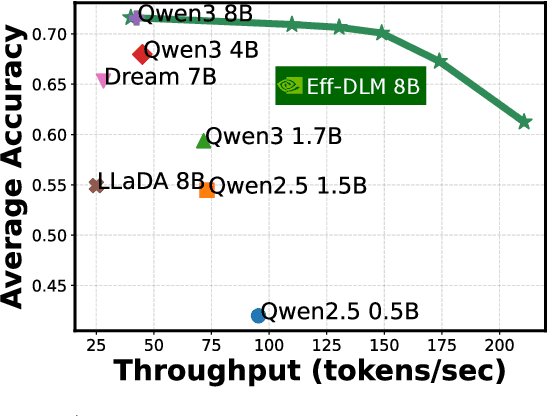
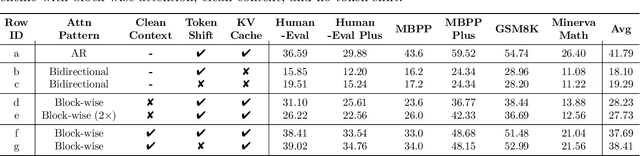
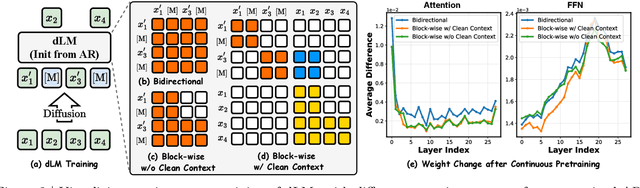
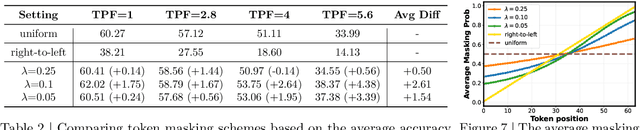
Diffusion language models (dLMs) have emerged as a promising paradigm that enables parallel, non-autoregressive generation, but their learning efficiency lags behind that of autoregressive (AR) language models when trained from scratch. To this end, we study AR-to-dLM conversion to transform pretrained AR models into efficient dLMs that excel in speed while preserving AR models' task accuracy. We achieve this by identifying limitations in the attention patterns and objectives of existing AR-to-dLM methods and then proposing principles and methodologies for more effective AR-to-dLM conversion. Specifically, we first systematically compare different attention patterns and find that maintaining pretrained AR weight distributions is critical for effective AR-to-dLM conversion. As such, we introduce a continuous pretraining scheme with a block-wise attention pattern, which remains causal across blocks while enabling bidirectional modeling within each block. We find that this approach can better preserve pretrained AR models' weight distributions than fully bidirectional modeling, in addition to its known benefit of enabling KV caching, and leads to a win-win in accuracy and efficiency. Second, to mitigate the training-test gap in mask token distributions (uniform vs. highly left-to-right), we propose a position-dependent token masking strategy that assigns higher masking probabilities to later tokens during training to better mimic test-time behavior. Leveraging this framework, we conduct extensive studies of dLMs' attention patterns, training dynamics, and other design choices, providing actionable insights into scalable AR-to-dLM conversion. These studies lead to the Efficient-DLM family, which outperforms state-of-the-art AR models and dLMs, e.g., our Efficient-DLM 8B achieves +5.4%/+2.7% higher accuracy with 4.5x/2.7x higher throughput compared to Dream 7B and Qwen3 4B, respectively.
TiDAR: Think in Diffusion, Talk in Autoregression
Nov 12, 2025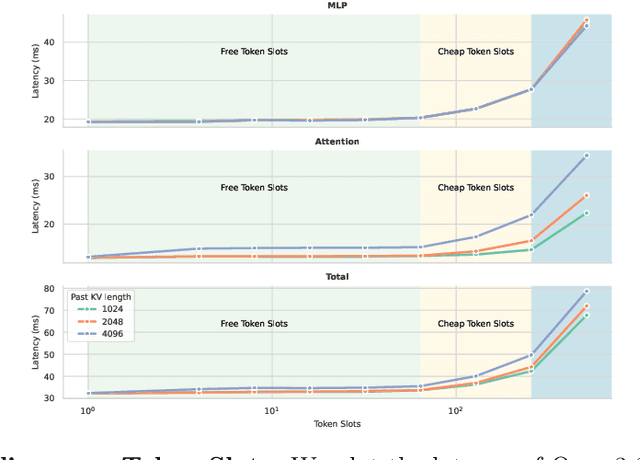

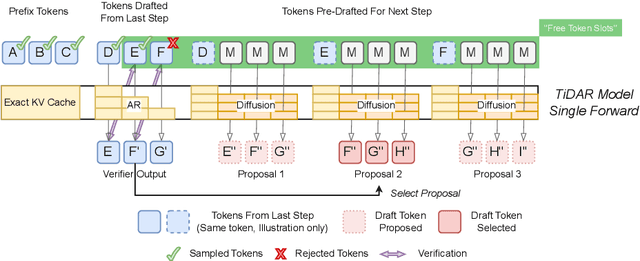
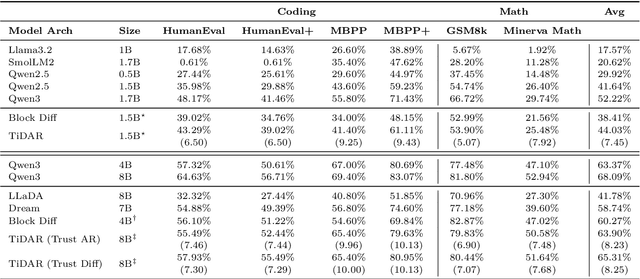
Diffusion language models hold the promise of fast parallel generation, while autoregressive (AR) models typically excel in quality due to their causal structure aligning naturally with language modeling. This raises a fundamental question: can we achieve a synergy with high throughput, higher GPU utilization, and AR level quality? Existing methods fail to effectively balance these two aspects, either prioritizing AR using a weaker model for sequential drafting (speculative decoding), leading to lower drafting efficiency, or using some form of left-to-right (AR-like) decoding logic for diffusion, which still suffers from quality degradation and forfeits its potential parallelizability. We introduce TiDAR, a sequence-level hybrid architecture that drafts tokens (Thinking) in Diffusion and samples final outputs (Talking) AutoRegressively - all within a single forward pass using specially designed structured attention masks. This design exploits the free GPU compute density, achieving a strong balance between drafting and verification capacity. Moreover, TiDAR is designed to be serving-friendly (low overhead) as a standalone model. We extensively evaluate TiDAR against AR models, speculative decoding, and diffusion variants across generative and likelihood tasks at 1.5B and 8B scales. Thanks to the parallel drafting and sampling as well as exact KV cache support, TiDAR outperforms speculative decoding in measured throughput and surpasses diffusion models like Dream and Llada in both efficiency and quality. Most notably, TiDAR is the first architecture to close the quality gap with AR models while delivering 4.71x to 5.91x more tokens per second.
Breast Cancer Detection in Thermographic Images via Diffusion-Based Augmentation and Nonlinear Feature Fusion
Sep 08, 2025Data scarcity hinders deep learning for medical imaging. We propose a framework for breast cancer classification in thermograms that addresses this using a Diffusion Probabilistic Model (DPM) for data augmentation. Our DPM-based augmentation is shown to be superior to both traditional methods and a ProGAN baseline. The framework fuses deep features from a pre-trained ResNet-50 with handcrafted nonlinear features (e.g., Fractal Dimension) derived from U-Net segmented tumors. An XGBoost classifier trained on these fused features achieves 98.0\% accuracy and 98.1\% sensitivity. Ablation studies and statistical tests confirm that both the DPM augmentation and the nonlinear feature fusion are critical, statistically significant components of this success. This work validates the synergy between advanced generative models and interpretable features for creating highly accurate medical diagnostic tools.
Learning Unified Representations from Heterogeneous Data for Robust Heart Rate Modeling
Aug 29, 2025Heart rate prediction is vital for personalized health monitoring and fitness, while it frequently faces a critical challenge when deploying in real-world: data heterogeneity. We classify it in two key dimensions: source heterogeneity from fragmented device markets with varying feature sets, and user heterogeneity reflecting distinct physiological patterns across individuals and activities. Existing methods either discard device-specific information, or fail to model user-specific differences, limiting their real-world performance. To address this, we propose a framework that learns latent representations agnostic to both heterogeneity, enabling downstream predictors to work consistently under heterogeneous data patterns. Specifically, we introduce a random feature dropout strategy to handle source heterogeneity, making the model robust to various feature sets. To manage user heterogeneity, we employ a time-aware attention module to capture long-term physiological traits and use a contrastive learning objective to build a discriminative representation space. To reflect the heterogeneous nature of real-world data, we created and publicly released a new benchmark dataset, ParroTao. Evaluations on both ParroTao and the public FitRec dataset show that our model significantly outperforms existing baselines by 17% and 15%, respectively. Furthermore, analysis of the learned representations demonstrates their strong discriminative power, and one downstream application task confirm the practical value of our model.
HAMburger: Accelerating LLM Inference via Token Smashing
May 26, 2025The growing demand for efficient Large Language Model (LLM) inference requires a holistic optimization on algorithms, systems, and hardware. However, very few works have fundamentally changed the generation pattern: each token needs one forward pass and one KV cache. This can be sub-optimal because we found that LLMs are extremely capable of self-identifying the exact dose of information that a single KV cache can store, and many tokens can be generated confidently without global context. Based on this insight, we introduce HAMburger, a Hierarchically Auto-regressive Model that redefines resource allocation in LLMs by moving beyond uniform computation and storage per token during inference. Stacking a compositional embedder and a micro-step decoder in between a base LLM, HAMburger smashes multiple tokens into a single KV and generates several tokens per step. Additionally, HAMburger functions as a speculative decoding framework where it can blindly trust self-drafted tokens. As a result, HAMburger shifts the growth of KV cache and forward FLOPs from linear to sub-linear with respect to output length, and adjusts its inference speed based on query perplexity and output structure. Extensive evaluations show that HAMburger reduces the KV cache computation by up to 2$\times$ and achieves up to 2$\times$ TPS, while maintaining quality in both short- and long-context tasks. Our method explores an extremely challenging inference regime that requires both computation- and memory-efficiency with a hardware-agnostic design.
Minimax Rate-Optimal Algorithms for High-Dimensional Stochastic Linear Bandits
May 23, 2025We study the stochastic linear bandit problem with multiple arms over $T$ rounds, where the covariate dimension $d$ may exceed $T$, but each arm-specific parameter vector is $s$-sparse. We begin by analyzing the sequential estimation problem in the single-arm setting, focusing on cumulative mean-squared error. We show that Lasso estimators are provably suboptimal in the sequential setting, exhibiting suboptimal dependence on $d$ and $T$, whereas thresholded Lasso estimators -- obtained by applying least squares to the support selected by thresholding an initial Lasso estimator -- achieve the minimax rate. Building on these insights, we consider the full linear contextual bandit problem and propose a three-stage arm selection algorithm that uses thresholded Lasso as the main estimation method. We derive an upper bound on the cumulative regret of order $s(\log s)(\log d + \log T)$, and establish a matching lower bound up to a $\log s$ factor, thereby characterizing the minimax regret rate up to a logarithmic term in $s$. Moreover, when a short initial period is excluded from the regret, the proposed algorithm achieves exact minimax optimality.
GSFF-SLAM: 3D Semantic Gaussian Splatting SLAM via Feature Field
Apr 28, 2025

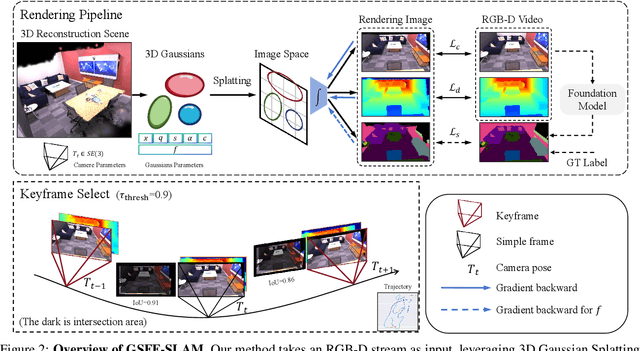
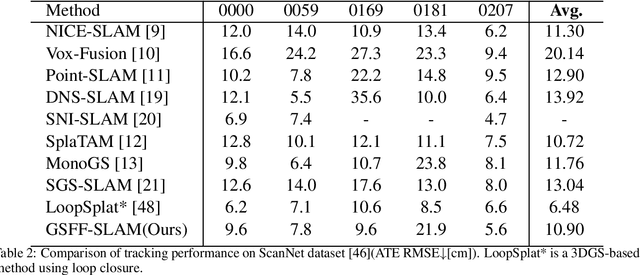
Semantic-aware 3D scene reconstruction is essential for autonomous robots to perform complex interactions. Semantic SLAM, an online approach, integrates pose tracking, geometric reconstruction, and semantic mapping into a unified framework, shows significant potential. However, existing systems, which rely on 2D ground truth priors for supervision, are often limited by the sparsity and noise of these signals in real-world environments. To address this challenge, we propose GSFF-SLAM, a novel dense semantic SLAM system based on 3D Gaussian Splatting that leverages feature fields to achieve joint rendering of appearance, geometry, and N-dimensional semantic features. By independently optimizing feature gradients, our method supports semantic reconstruction using various forms of 2D priors, particularly sparse and noisy signals. Experimental results demonstrate that our approach outperforms previous methods in both tracking accuracy and photorealistic rendering quality. When utilizing 2D ground truth priors, GSFF-SLAM achieves state-of-the-art semantic segmentation performance with 95.03\% mIoU, while achieving up to 2.9$\times$ speedup with only marginal performance degradation.
Multi-Object Sketch Animation by Scene Decomposition and Motion Planning
Mar 25, 2025Sketch animation, which brings static sketches to life by generating dynamic video sequences, has found widespread applications in GIF design, cartoon production, and daily entertainment. While current sketch animation methods perform well in single-object sketch animation, they struggle in multi-object scenarios. By analyzing their failures, we summarize two challenges of transitioning from single-object to multi-object sketch animation: object-aware motion modeling and complex motion optimization. For multi-object sketch animation, we propose MoSketch based on iterative optimization through Score Distillation Sampling (SDS), without any other data for training. We propose four modules: LLM-based scene decomposition, LLM-based motion planning, motion refinement network and compositional SDS, to tackle the two challenges in a divide-and-conquer strategy. Extensive qualitative and quantitative experiments demonstrate the superiority of our method over existing sketch animation approaches. MoSketch takes a pioneering step towards multi-object sketch animation, opening new avenues for future research and applications. The code will be released.