 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECGN: A Cluster-Aware Approach to Graph Neural Networks for Imbalanced Classification
Oct 15, 2024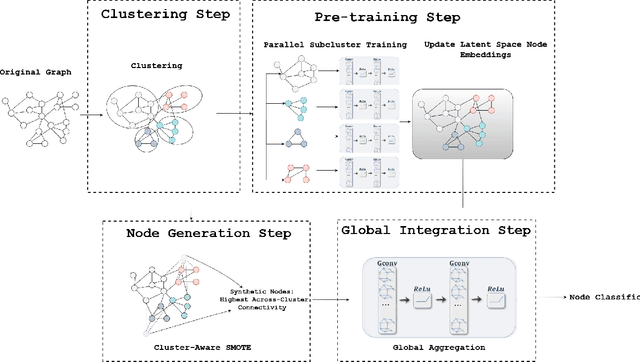



Classifying nodes in a graph is a common problem. The ideal classifier must adapt to any imbalances in the class distribution. It must also use information in the clustering structure of real-world graphs. Existing Graph Neural Networks (GNNs) have not addressed both problems together. We propose the Enhanced Cluster-aware Graph Network (ECGN), a novel method that addresses these issues by integrating cluster-specific training with synthetic node generation. Unlike traditional GNNs that apply the same node update process for all nodes, ECGN learns different aggregations for different clusters. We also use the clusters to generate new minority-class nodes in a way that helps clarify the inter-class decision boundary. By combining cluster-aware embeddings with a global integration step, ECGN enhances the quality of the resulting node embeddings. Our method works with any underlying GNN and any cluster generation technique. Experimental results show that ECGN consistently outperforms its closest competitors by up to 11% on some widely studied benchmark datasets.
Unmasking Efficiency: Learning Salient Sparse Models in Non-IID Federated Learning
May 15, 2024



In this work, we propose Salient Sparse Federated Learning (SSFL), a streamlined approach for sparse federated learning with efficient communication. SSFL identifies a sparse subnetwork prior to training, leveraging parameter saliency scores computed separately on local client data in non-IID scenarios, and then aggregated, to determine a global mask. Only the sparse model weights are communicated each round between the clients and the server. We validate SSFL's effectiveness using standard non-IID benchmarks, noting marked improvements in the sparsity--accuracy trade-offs. Finally, we deploy our method in a real-world federated learning framework and report improvement in communication time.
Brain Networks and Intelligence: A Graph Neural Network Based Approach to Resting State fMRI Data
Nov 06, 2023Resting-state functional magnetic resonance imaging (rsfMRI) is a powerful tool for investigating the relationship between brain function and cognitive processes as it allows for the functional organization of the brain to be captured without relying on a specific task or stimuli. In this paper, we present a novel modeling architecture called BrainRGIN for predicting intelligence (fluid, crystallized, and total intelligence) using graph neural networks on rsfMRI derived static functional network connectivity matrices. Extending from the existing graph convolution networks, our approach incorporates a clustering-based embedding and graph isomorphism network in the graph convolutional layer to reflect the nature of the brain sub-network organization and efficient network expression, in combination with TopK pooling and attention-based readout functions. We evaluated our proposed architecture on a large dataset, specifically the Adolescent Brain Cognitive Development Dataset, and demonstrated its effectiveness in predicting individual differences in intelligence. Our model achieved lower mean squared errors and higher correlation scores than existing relevant graph architectures and other traditional machine learning models for all of the intelligence prediction tasks. The middle frontal gyrus exhibited a significant contribution to both fluid and crystallized intelligence, suggesting their pivotal role in these cognitive processes. Total composite scores identified a diverse set of brain regions to be relevant which underscores the complex nature of total intelligence.
SalientGrads: Sparse Models for Communication Efficient and Data Aware Distributed Federated Training
Apr 15, 2023Federated learning (FL) enables the training of a model leveraging decentralized data in client sites while preserving privacy by not collecting data. However, one of the significant challenges of FL is limited computation and low communication bandwidth in resource limited edge client nodes. To address this, several solutions have been proposed in recent times including transmitting sparse models and learning dynamic masks iteratively, among others. However, many of these methods rely on transmitting the model weights throughout the entire training process as they are based on ad-hoc or random pruning criteria. In this work, we propose Salient Grads, which simplifies the process of sparse training by choosing a data aware subnetwork before training, based on the model-parameter's saliency scores, which is calculated from the local client data. Moreover only highly sparse gradients are transmitted between the server and client models during the training process unlike most methods that rely on sharing the entire dense model in each round. We also demonstrate the efficacy of our method in a real world federated learning application and report improvement in wall-clock communication time.