 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3PO: Optimized Large Language Model Cascades with Probabilistic Cost Constraints for Reasoning
Nov 10, 2025Large language models (LLMs) have achieved impressive results on complex reasoning tasks, but their high inference cost remains a major barrier to real-world deployment. A promising solution is to use cascaded inference, where small, cheap models handle easy queries, and only the hardest examples are escalated to more powerful models. However, existing cascade methods typically rely on supervised training with labeled data, offer no theoretical generalization guarantees, and provide limited control over test-time computational cost. We introduce C3PO (Cost Controlled Cascaded Prediction Optimization), a self-supervised framework for optimizing LLM cascades under probabilistic cost constraints. By focusing on minimizing regret with respect to the most powerful model (MPM), C3PO avoids the need for labeled data by constructing a cascade using only unlabeled model outputs. It leverages conformal prediction to bound the probability that inference cost exceeds a user-specified budget. We provide theoretical guarantees on both cost control and generalization error, and show that our optimization procedure is effective even with small calibration sets. Empirically, C3PO achieves state-of-the-art performance across a diverse set of reasoning benchmarks including GSM8K, MATH-500, BigBench-Hard and AIME, outperforming strong LLM cascading baselines in both accuracy and cost-efficiency. Our results demonstrate that principled, label-free cascade optimization can enable scalable LLM deployment.
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
SKOLR: Structured Koopman Operator Linear RNN for Time-Series Forecasting
Jun 17, 2025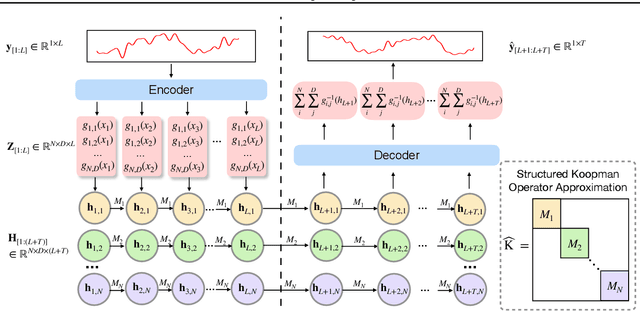



Koopman operator theory provides a framework for nonlinear dynamical system analysis and time-series forecasting by mapping dynamics to a space of real-valued measurement functions, enabling a linear operator representation. Despite the advantage of linearity, the operator is generally infinite-dimensional. Therefore, the objective is to learn measurement functions that yield a tractable finite-dimensional Koopman operator approximation. In this work, we establish a connection between Koopman operator approximation and linear Recurrent Neural Networks (RNNs), which have recently demonstrated remarkable success in sequence modeling. We show that by considering an extended state consisting of lagged observations, we can establish an equivalence between a structured Koopman operator and linear RNN updates. Building on this connection, we present SKOLR, which integrates a learnable spectral decomposition of the input signal with a multilayer perceptron (MLP) as the measurement functions and implements a structured Koopman operator via a highly parallel linear RNN stack. Numerical experiments on various forecasting benchmarks and dynamical systems show that this streamlined, Koopman-theory-based design delivers exceptional performance.
Dynamic layer selection in decoder-only transformers
Oct 26, 2024The vast size of Large Language Models (LLMs) has prompted a search to optimize inference. One effective approach is dynamic inference, which adapts the architecture to the sample-at-hand to reduce the overall computational cost. We empirically examine two common dynamic inference methods for natural language generation (NLG): layer skipping and early exiting. We find that a pre-trained decoder-only model is significantly more robust to layer removal via layer skipping, as opposed to early exit. We demonstrate the difficulty of using hidden state information to adapt computation on a per-token basis for layer skipping. Finally, we show that dynamic computation allocation on a per-sequence basis holds promise for significant efficiency gains by constructing an oracle controller. Remarkably, we find that there exists an allocation which achieves equal performance to the full model using only 23.3% of its layers on average.
ECGN: A Cluster-Aware Approach to Graph Neural Networks for Imbalanced Classification
Oct 15, 2024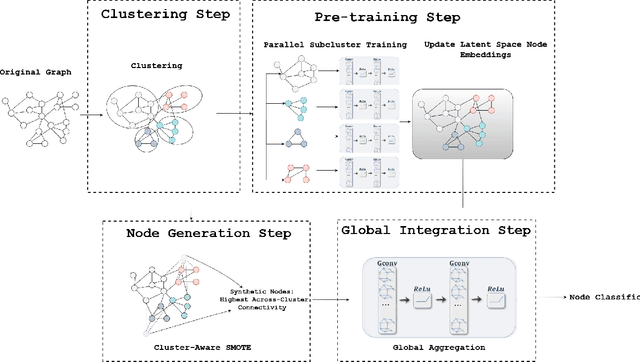



Classifying nodes in a graph is a common problem. The ideal classifier must adapt to any imbalances in the class distribution. It must also use information in the clustering structure of real-world graphs. Existing Graph Neural Networks (GNNs) have not addressed both problems together. We propose the Enhanced Cluster-aware Graph Network (ECGN), a novel method that addresses these issues by integrating cluster-specific training with synthetic node generation. Unlike traditional GNNs that apply the same node update process for all nodes, ECGN learns different aggregations for different clusters. We also use the clusters to generate new minority-class nodes in a way that helps clarify the inter-class decision boundary. By combining cluster-aware embeddings with a global integration step, ECGN enhances the quality of the resulting node embeddings. Our method works with any underlying GNN and any cluster generation technique. Experimental results show that ECGN consistently outperforms its closest competitors by up to 11% on some widely studied benchmark datasets.
MODL: Multilearner Online Deep Learning
May 28, 2024



Online deep learning solves the problem of learning from streams of data, reconciling two opposing objectives: learn fast and learn deep. Existing work focuses almost exclusively on exploring pure deep learning solutions, which are much better suited to handle the "deep" than the "fast" part of the online learning equation. In our work, we propose a different paradigm, based on a hybrid multilearner approach. First, we develop a fast online logistic regression learner. This learner does not rely on backpropagation. Instead, it uses closed form recursive updates of model parameters, handling the fast learning part of the online learning problem. We then analyze the existing online deep learning theory and show that the widespread ODL approach, currently operating at complexity $O(L^2)$ in terms of the number of layers $L$, can be equivalently implemented in $O(L)$ complexity. This further leads us to the cascaded multilearner design, in which multiple shallow and deep learners are co-trained to solve the online learning problem in a cooperative, synergistic fashion. We show that this approach achieves state-of-the-art results on common online learning datasets, while also being able to handle missing features gracefully. Our code is publicly available at https://github.com/AntonValk/MODL.
Personalized Negative Reservoir for Incremental Learning in Recommender Systems
Mar 06, 2024



Recommender systems have become an integral part of online platforms. Every day the volume of training data is expanding and the number of user interactions is constantly increasing. The exploration of larger and more expressive models has become a necessary pursuit to improve user experience. However, this progression carries with it an increased computational burden. In commercial settings, once a recommendation system model has been trained and deployed it typically needs to be updated frequently as new client data arrive. Cumulatively, the mounting volume of data is guaranteed to eventually make full batch retraining of the model from scratch computationally infeasible. Naively fine-tuning solely on the new data runs into the well-documented problem of catastrophic forgetting. Despite the fact that negative sampling is a crucial part of training with implicit feedback, no specialized technique exists that is tailored to the incremental learning framework. In this work, we take the first step to propose, a personalized negative reservoir strategy which is used to obtain negative samples for the standard triplet loss. This technique balances alleviation of forgetting with plasticity by encouraging the model to remember stable user preferences and selectively forget when user interests change. We derive the mathematical formulation of a negative sampler to populate and update the reservoir. We integrate our design in three SOTA and commonly used incremental recommendation models. We show that these concrete realizations of our negative reservoir framework achieve state-of-the-art results in standard benchmarks, on multiple standard top-k evaluation metrics.
Structure Aware Incremental Learning with Personalized Imitation Weights for Recommender Systems
May 02, 2023



Recommender systems now consume large-scale data and play a significant role in improving user experience. Graph Neural Networks (GNNs) have emerged as one of the most effective recommender system models because they model the rich relational information. The ever-growing volume of data can make training GNNs prohibitively expensive. To address this, previous attempts propose to train the GNN models incrementally as new data blocks arrive. Feature and structure knowledge distillation techniques have been explored to allow the GNN model to train in a fast incremental fashion while alleviating the catastrophic forgetting problem. However, preserving the same amount of the historical information for all users is sub-optimal since it fails to take into account the dynamics of each user's change of preferences. For the users whose interests shift substantially, retaining too much of the old knowledge can overly constrain the model, preventing it from quickly adapting to the users' novel interests. In contrast, for users who have static preferences, model performance can benefit greatly from preserving as much of the user's long-term preferences as possible. In this work, we propose a novel training strategy that adaptively learns personalized imitation weights for each user to balance the contribution from the recent data and the amount of knowledge to be distilled from previous time periods. We demonstrate the effectiveness of learning imitation weights via a comparison on five diverse datasets for three state-of-art structure distillation based recommender systems. The performance shows consistent improvement over competitive incremental learning techninques.
Contrastive Learning for Time Series on Dynamic Graphs
Sep 21, 2022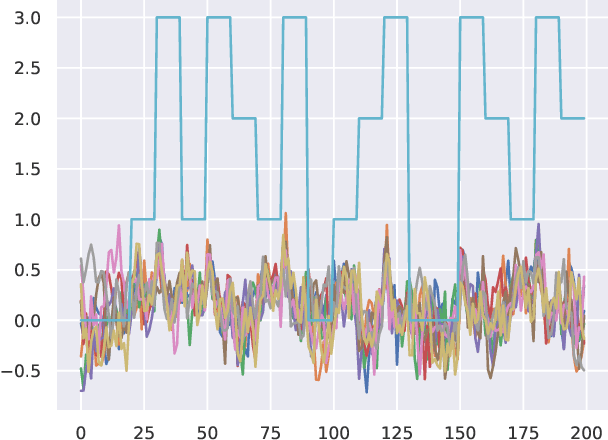
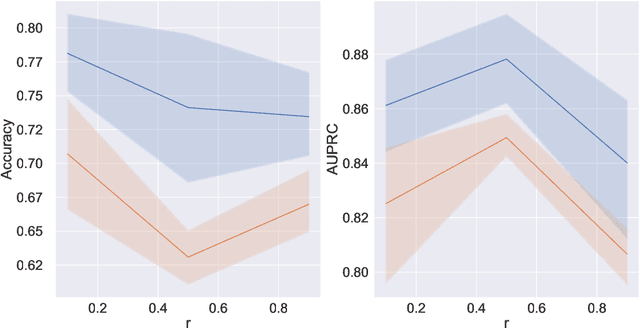
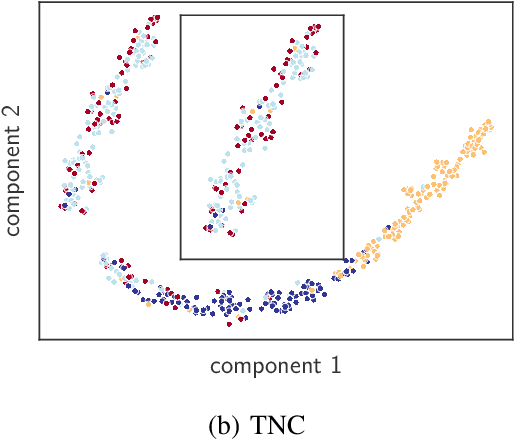

There have been several recent efforts towards developing representations for multivariate time-series in an unsupervised learning framework. Such representations can prove beneficial in tasks such as activity recognition, health monitoring, and anomaly detection. In this paper, we consider a setting where we observe time-series at each node in a dynamic graph. We propose a framework called GraphTNC for unsupervised learning of joint representations of the graph and the time-series. Our approach employs a contrastive learning strategy. Based on an assumption that the time-series and graph evolution dynamics are piecewise smooth, we identify local windows of time where the signals exhibit approximate stationarity. We then train an encoding that allows the distribution of signals within a neighborhood to be distinguished from the distribution of non-neighboring signals. We first demonstrate the performance of our proposed framework using synthetic data, and subsequently we show that it can prove beneficial for the classification task with real-world datasets.
Bag Graph: Multiple Instance Learning using Bayesian Graph Neural Networks
Feb 22, 2022
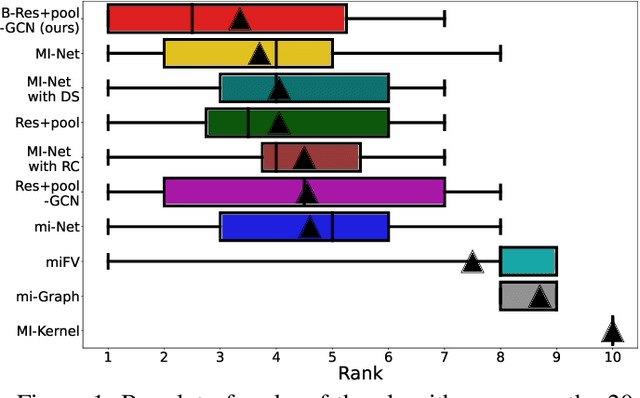
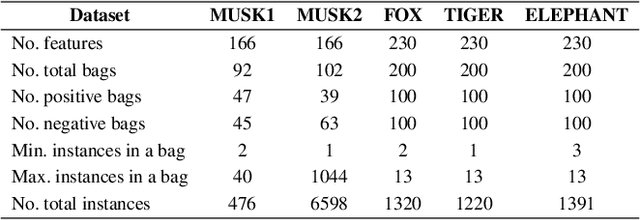
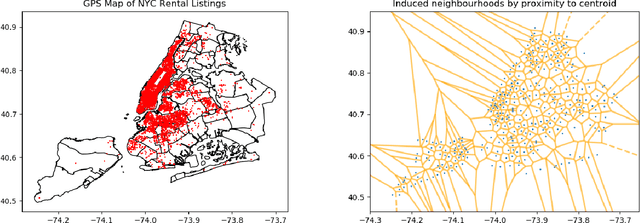
Multiple Instance Learning (MIL) is a weakly supervised learning problem where the aim is to assign labels to sets or bags of instances, as opposed to traditional supervised learning where each instance is assumed to be independent and identically distributed (IID) and is to be labeled individually. Recent work has shown promising results for neural network models in the MIL setting. Instead of focusing on each instance, these models are trained in an end-to-end fashion to learn effective bag-level representations by suitably combining permutation invariant pooling techniques with neural architectures. In this paper, we consider modelling the interactions between bags using a graph and employ Graph Neural Networks (GNNs) to facilitate end-to-end learning. Since a meaningful graph representing dependencies between bags is rarely available, we propose to use a Bayesian GNN framework that can generate a likely graph structure for scenarios where there is uncertainty in the graph or when no graph is available. Empirical results demonstrate the efficacy of the proposed technique for several MIL benchmark tasks and a distribution regression task.