 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3PO: Optimized Large Language Model Cascades with Probabilistic Cost Constraints for Reasoning
Nov 10, 2025Large language models (LLMs) have achieved impressive results on complex reasoning tasks, but their high inference cost remains a major barrier to real-world deployment. A promising solution is to use cascaded inference, where small, cheap models handle easy queries, and only the hardest examples are escalated to more powerful models. However, existing cascade methods typically rely on supervised training with labeled data, offer no theoretical generalization guarantees, and provide limited control over test-time computational cost. We introduce C3PO (Cost Controlled Cascaded Prediction Optimization), a self-supervised framework for optimizing LLM cascades under probabilistic cost constraints. By focusing on minimizing regret with respect to the most powerful model (MPM), C3PO avoids the need for labeled data by constructing a cascade using only unlabeled model outputs. It leverages conformal prediction to bound the probability that inference cost exceeds a user-specified budget. We provide theoretical guarantees on both cost control and generalization error, and show that our optimization procedure is effective even with small calibration sets. Empirically, C3PO achieves state-of-the-art performance across a diverse set of reasoning benchmarks including GSM8K, MATH-500, BigBench-Hard and AIME, outperforming strong LLM cascading baselines in both accuracy and cost-efficiency. Our results demonstrate that principled, label-free cascade optimization can enable scalable LLM deployment.
GraphPPD: Posterior Predictive Modelling for Graph-Level Inference
Aug 23, 2025Accurate modelling and quantification of predictive uncertainty is crucial in deep learning since it allows a model to make safer decisions when the data is ambiguous and facilitates the users' understanding of the model's confidence in its predictions. Along with the tremendously increasing research focus on \emph{graph neural networks} (GNNs) in recent years, there have been numerous techniques which strive to capture the uncertainty in their predictions. However, most of these approaches are specifically designed for node or link-level tasks and cannot be directly applied to graph-level learning problems. In this paper, we propose a novel variational modelling framework for the \emph{posterior predictive distribution}~(PPD) to obtain uncertainty-aware prediction in graph-level learning tasks. Based on a graph-level embedding derived from one of the existing GNNs, our framework can learn the PPD in a data-adaptive fashion. Experimental results on several benchmark datasets exhibit the effectiveness of our approach.
Reasoning on a Budget: A Survey of Adaptive and Controllable Test-Time Compute in LLMs
Jul 02, 2025Large language models (LLMs) have rapidly progressed into general-purpose agents capable of solving a broad spectrum of tasks. However, current models remain inefficient at reasoning: they apply fixed inference-time compute regardless of task complexity, often overthinking simple problems while underthinking hard ones. This survey presents a comprehensive review of efficient test-time compute (TTC) strategies, which aim to improve the computational efficiency of LLM reasoning. We introduce a two-tiered taxonomy that distinguishes between L1-controllability, methods that operate under fixed compute budgets, and L2-adaptiveness, methods that dynamically scale inference based on input difficulty or model confidence. We benchmark leading proprietary LLMs across diverse datasets, highlighting critical trade-offs between reasoning performance and token usage. Compared to prior surveys on efficient reasoning, our review emphasizes the practical control, adaptability, and scalability of TTC methods. Finally, we discuss emerging trends such as hybrid thinking models and identify key challenges for future work towards making LLMs more computationally efficient, robust, and responsive to user constraints.
Simplifying Graph Transformers
Apr 17, 2025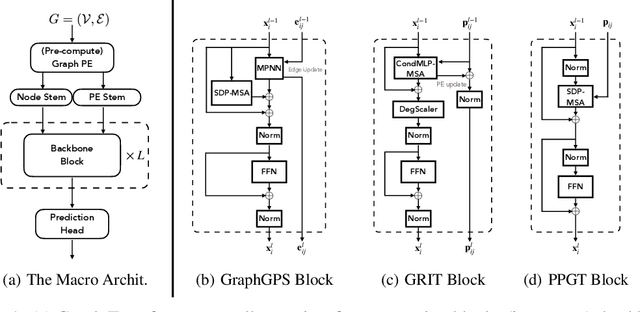
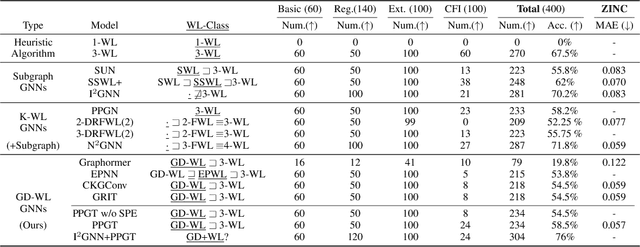
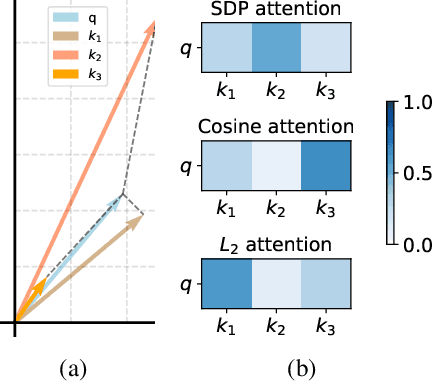
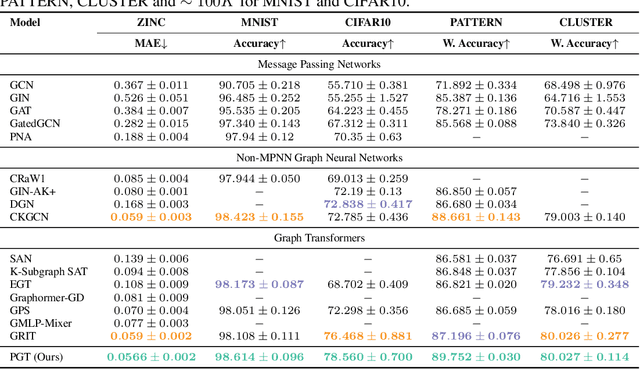
Transformers have attained outstanding performance across various modalities, employing scaled-dot-product (SDP) attention mechanisms. Researchers have attempted to migrate Transformers to graph learning, but most advanced Graph Transformers are designed with major architectural differences, either integrating message-passing or incorporating sophisticated attention mechanisms. These complexities prevent the easy adoption of Transformer training advances. We propose three simple modifications to the plain Transformer to render it applicable to graphs without introducing major architectural distortions. Specifically, we advocate for the use of (1) simplified $L_2$ attention to measure the magnitude closeness of tokens; (2) adaptive root-mean-square normalization to preserve token magnitude information; and (3) a relative positional encoding bias with a shared encoder. Significant performance gains across a variety of graph datasets justify the effectiveness of our proposed modifications. Furthermore, empirical evaluation on the expressiveness benchmark reveals noteworthy realized expressiveness in the graph isomorphism.
Hint Marginalization for Improved Reasoning in Large Language Models
Dec 17, 2024Large Language Models (LLMs) have exhibited an impressive capability to perform reasoning tasks, especially if they are encouraged to generate a sequence of intermediate steps. Reasoning performance can be improved by suitably combining multiple LLM responses, generated either in parallel in a single query, or via sequential interactions with LLMs throughout the reasoning process. Existing strategies for combination, such as self-consistency and progressive-hint-prompting, make inefficient usage of the LLM responses. We present Hint Marginalization, a novel and principled algorithmic framework to enhance the reasoning capabilities of LLMs. Our approach can be viewed as an iterative sampling strategy for forming a Monte Carlo approximation of an underlying distribution of answers, with the goal of identifying the mode the most likely answer. Empirical evaluation on several benchmark datasets for arithmetic reasoning demonstrates the superiority of the proposed approach.
CKGConv: General Graph Convolution with Continuous Kernels
Apr 21, 2024The existing definitions of graph convolution, either from spatial or spectral perspectives, are inflexible and not unified. Defining a general convolution operator in the graph domain is challenging due to the lack of canonical coordinates, the presence of irregular structures, and the properties of graph symmetries. In this work, we propose a novel graph convolution framework by parameterizing the kernels as continuous functions of pseudo-coordinates derived via graph positional encoding. We name this Continuous Kernel Graph Convolution (CKGConv). Theoretically, we demonstrate that CKGConv is flexible and expressive. CKGConv encompasses many existing graph convolutions, and exhibits the same expressiveness as graph transformers in terms of distinguishing non-isomorphic graphs. Empirically, we show that CKGConv-based Networks outperform existing graph convolutional networks and perform comparably to the best graph transformers across a variety of graph datasets.
Multi-resolution Time-Series Transformer for Long-term Forecasting
Nov 07, 2023The performance of transformers for time-series forecasting has improved significantly. Recent architectures learn complex temporal patterns by segmenting a time-series into patches and using the patches as tokens. The patch size controls the ability of transformers to learn the temporal patterns at different frequencies: shorter patches are effective for learning localized, high-frequency patterns, whereas mining long-term seasonalities and trends requires longer patches. Inspired by this observation, we propose a novel framework, Multi-resolution Time-Series Transformer (MTST), which consists of a multi-branch architecture for simultaneous modeling of diverse temporal patterns at different resolutions. In contrast to many existing time-series transformers, we employ relative positional encoding, which is better suited for extracting periodic components at different scales. Extensive experiments on several real-world datasets demonstrate the effectiveness of MTST in comparison to state-of-the-art forecasting techniques.
Node Copying: A Random Graph Model for Effective Graph Sampling
Aug 04, 2022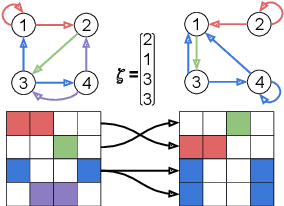
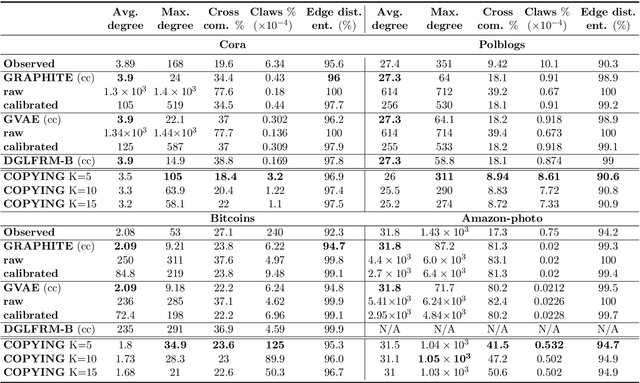
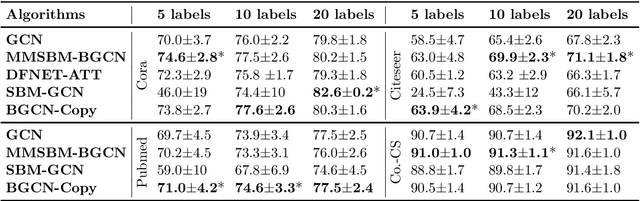
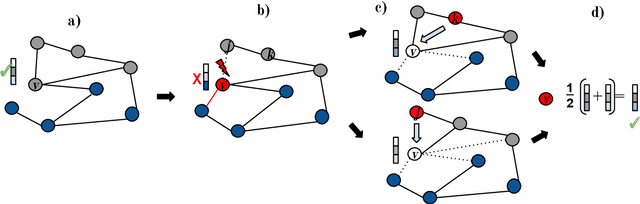
There has been an increased interest in applying machine learning techniques on relational structured-data based on an observed graph. Often, this graph is not fully representative of the true relationship amongst nodes. In these settings, building a generative model conditioned on the observed graph allows to take the graph uncertainty into account. Various existing techniques either rely on restrictive assumptions, fail to preserve topological properties within the samples or are prohibitively expensive for larger graphs. In this work, we introduce the node copying model for constructing a distribution over graphs. Sampling of a random graph is carried out by replacing each node's neighbors by those of a randomly sampled similar node. The sampled graphs preserve key characteristics of the graph structure without explicitly targeting them. Additionally, sampling from this model is extremely simple and scales linearly with the nodes. We show the usefulness of the copying model in three tasks. First, in node classification, a Bayesian formulation based on node copying achieves higher accuracy in sparse data settings. Second, we employ our proposed model to mitigate the effect of adversarial attacks on the graph topology. Last, incorporation of the model in a recommendation system setting improves recall over state-of-the-art methods.
Bag Graph: Multiple Instance Learning using Bayesian Graph Neural Networks
Feb 22, 2022
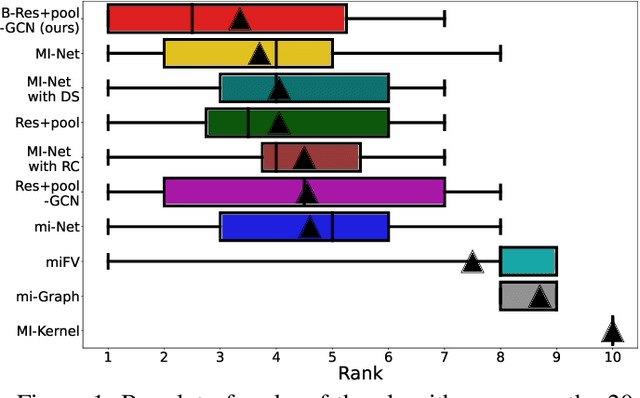
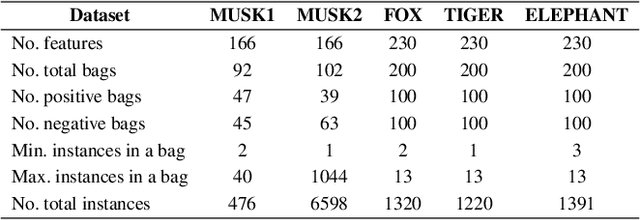
Multiple Instance Learning (MIL) is a weakly supervised learning problem where the aim is to assign labels to sets or bags of instances, as opposed to traditional supervised learning where each instance is assumed to be independent and identically distributed (IID) and is to be labeled individually. Recent work has shown promising results for neural network models in the MIL setting. Instead of focusing on each instance, these models are trained in an end-to-end fashion to learn effective bag-level representations by suitably combining permutation invariant pooling techniques with neural architectures. In this paper, we consider modelling the interactions between bags using a graph and employ Graph Neural Networks (GNNs) to facilitate end-to-end learning. Since a meaningful graph representing dependencies between bags is rarely available, we propose to use a Bayesian GNN framework that can generate a likely graph structure for scenarios where there is uncertainty in the graph or when no graph is available. Empirical results demonstrate the efficacy of the proposed technique for several MIL benchmark tasks and a distribution regression task.
RNN with Particle Flow for Probabilistic Spatio-temporal Forecasting
Jun 10, 2021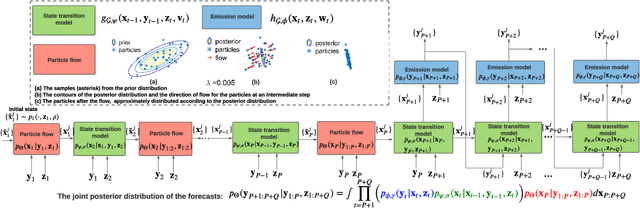
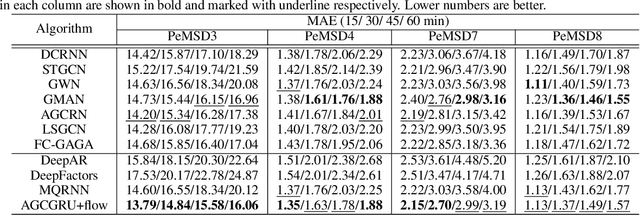
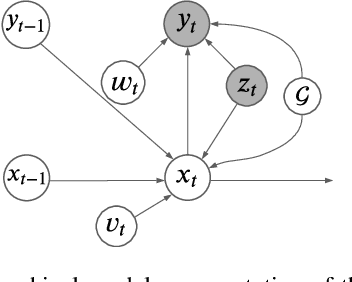
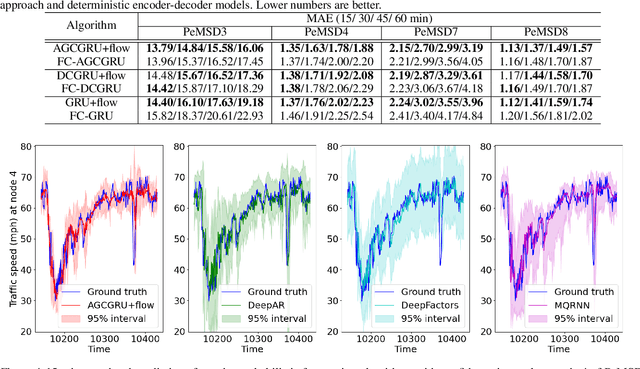
Spatio-temporal forecasting has numerous applications in analyzing wireless, traffic, and financial networks. Many classical statistical models often fall short in handling the complexity and high non-linearity present in time-series data. Recent advances in deep learning allow for better modelling of spatial and temporal dependencies. While most of these models focus on obtaining accurate point forecasts, they do not characterize the prediction uncertainty. In this work, we consider the time-series data as a random realization from a nonlinear state-space model and target Bayesian inference of the hidden states for probabilistic forecasting. We use particle flow as the tool for approximating the posterior distribution of the states, as it is shown to be highly effective in complex, high-dimensional settings. Thorough experimentation on several real world time-series datasets demonstrates that our approach provides better characterization of uncertainty while maintaining comparable accuracy to the state-of-the art point forecasting methods.