 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic layer selection in decoder-only transformers
Oct 26, 2024The vast size of Large Language Models (LLMs) has prompted a search to optimize inference. One effective approach is dynamic inference, which adapts the architecture to the sample-at-hand to reduce the overall computational cost. We empirically examine two common dynamic inference methods for natural language generation (NLG): layer skipping and early exiting. We find that a pre-trained decoder-only model is significantly more robust to layer removal via layer skipping, as opposed to early exit. We demonstrate the difficulty of using hidden state information to adapt computation on a per-token basis for layer skipping. Finally, we show that dynamic computation allocation on a per-sequence basis holds promise for significant efficiency gains by constructing an oracle controller. Remarkably, we find that there exists an allocation which achieves equal performance to the full model using only 23.3% of its layers on average.
Predicting Probabilities of Error to Combine Quantization and Early Exiting: QuEE
Jun 20, 2024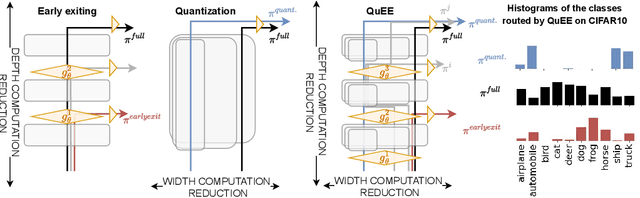
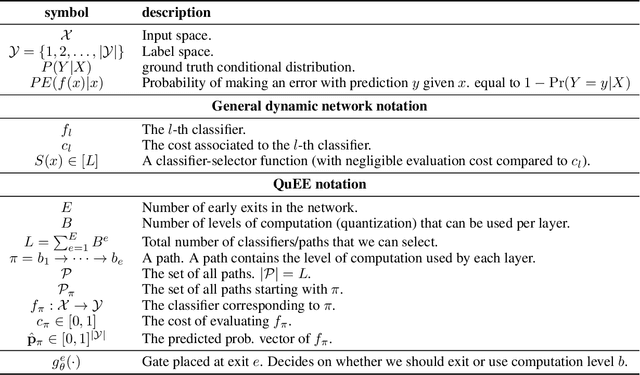
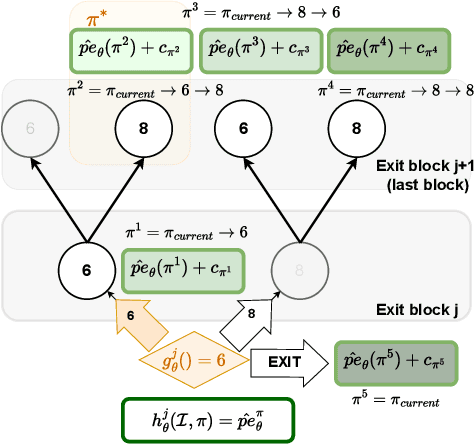

Machine learning models can solve complex tasks but often require significant computational resources during inference. This has led to the development of various post-training computation reduction methods that tackle this issue in different ways, such as quantization which reduces the precision of weights and arithmetic operations, and dynamic networks which adapt computation to the sample at hand. In this work, we propose a more general dynamic network that can combine both quantization and early exit dynamic network: QuEE. Our algorithm can be seen as a form of soft early exiting or input-dependent compression. Rather than a binary decision between exiting or continuing, we introduce the possibility of continuing with reduced computation. This complicates the traditionally considered early exiting problem, which we solve through a principled formulation. The crucial factor of our approach is accurate prediction of the potential accuracy improvement achievable through further computation. We demonstrate the effectiveness of our method through empirical evaluation, as well as exploring the conditions for its success on 4 classification datasets.
Interacting Diffusion Processes for Event Sequence Forecasting
Oct 26, 2023
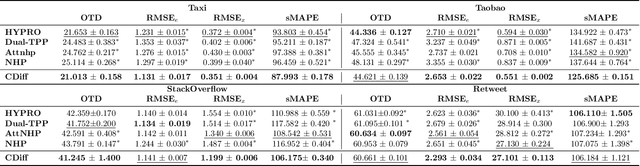


Neural Temporal Point Processes (TPPs) have emerged as the primary framework for predicting sequences of events that occur at irregular time intervals, but their sequential nature can hamper performance for long-horizon forecasts. To address this, we introduce a novel approach that incorporates a diffusion generative model. The model facilitates sequence-to-sequence prediction, allowing multi-step predictions based on historical event sequences. In contrast to previous approaches, our model directly learns the joint probability distribution of types and inter-arrival times for multiple events. This allows us to fully leverage the high dimensional modeling capability of modern generative models. Our model is composed of two diffusion processes, one for the time intervals and one for the event types. These processes interact through their respective denoising functions, which can take as input intermediate representations from both processes, allowing the model to learn complex interactions. We demonstrate that our proposal outperforms state-of-the-art baselines for long-horizon forecasting of TPP.
Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN
Oct 13, 2023Large pretrained models, coupled with fine-tuning, are slowly becoming established as the dominant architecture in machine learning. Even though these models offer impressive performance, their practical application is often limited by the prohibitive amount of resources required for every inference. Early-exiting dynamic neural networks (EDNN) circumvent this issue by allowing a model to make some of its predictions from intermediate layers (i.e., early-exit). Training an EDNN architecture is challenging as it consists of two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations. As a result, most existing approaches rely on thresholding confidence metrics for the gating mechanism and strive to improve the underlying backbone network and the inference modules. Although successful, this approach has two fundamental shortcomings: 1) the GMs and the IMs are decoupled during training, leading to a train-test mismatch; and 2) the thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to readily extract uncertainty information. We propose a novel architecture that connects these two modules. This leads to significant performance improvements on classification datasets and enables better uncertainty characterization capabilities.
Diffusing Gaussian Mixtures for Generating Categorical Data
Mar 08, 2023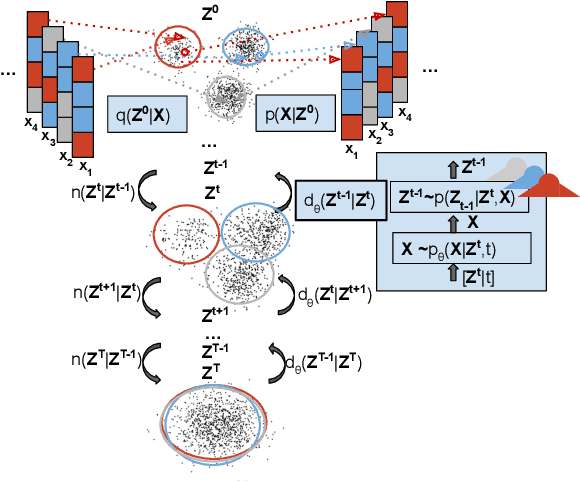



Learning a categorical distribution comes with its own set of challenges. A successful approach taken by state-of-the-art works is to cast the problem in a continuous domain to take advantage of the impressive performance of the generative models for continuous data. Amongst them are the recently emerging diffusion probabilistic models, which have the observed advantage of generating high-quality samples. Recent advances for categorical generative models have focused on log likelihood improvements. In this work, we propose a generative model for categorical data based on diffusion models with a focus on high-quality sample generation, and propose sampled-based evaluation methods. The efficacy of our method stems from performing diffusion in the continuous domain while having its parameterization informed by the structure of the categorical nature of the target distribution. Our method of evaluation highlights the capabilities and limitations of different generative models for generating categorical data, and includes experiments on synthetic and real-world protein datasets.
Evaluation of Categorical Generative Models -- Bridging the Gap Between Real and Synthetic Data
Oct 28, 2022



The machine learning community has mainly relied on real data to benchmark algorithms as it provides compelling evidence of model applicability. Evaluation on synthetic datasets can be a powerful tool to provide a better understanding of a model's strengths, weaknesses, and overall capabilities. Gaining these insights can be particularly important for generative modeling as the target quantity is completely unknown. Multiple issues related to the evaluation of generative models have been reported in the literature. We argue those problems can be avoided by an evaluation based on ground truth. General criticisms of synthetic experiments are that they are too simplified and not representative of practical scenarios. As such, our experimental setting is tailored to a realistic generative task. We focus on categorical data and introduce an appropriately scalable evaluation method. Our method involves tasking a generative model to learn a distribution in a high-dimensional setting. We then successively bin the large space to obtain smaller probability spaces where meaningful statistical tests can be applied. We consider increasingly large probability spaces, which correspond to increasingly difficult modeling tasks and compare the generative models based on the highest task difficulty they can reach before being detected as being too far from the ground truth. We validate our evaluation procedure with synthetic experiments on both synthetic generative models and current state-of-the-art categorical generative models.
Contrastive Learning for Time Series on Dynamic Graphs
Sep 21, 2022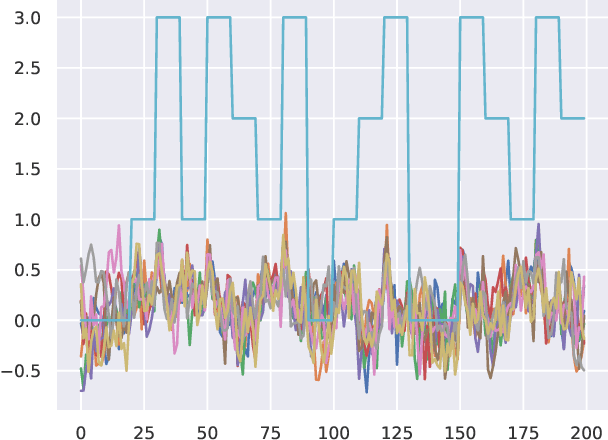
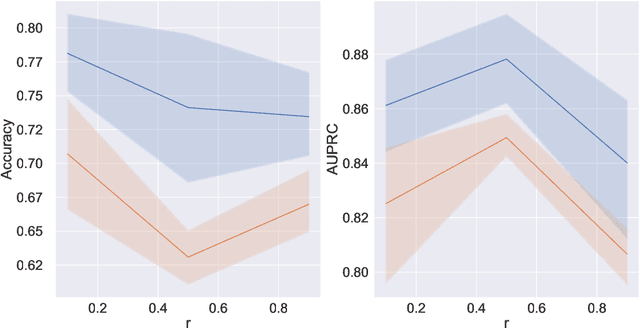
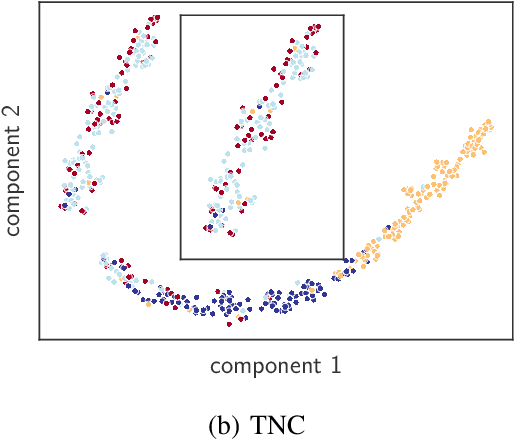

There have been several recent efforts towards developing representations for multivariate time-series in an unsupervised learning framework. Such representations can prove beneficial in tasks such as activity recognition, health monitoring, and anomaly detection. In this paper, we consider a setting where we observe time-series at each node in a dynamic graph. We propose a framework called GraphTNC for unsupervised learning of joint representations of the graph and the time-series. Our approach employs a contrastive learning strategy. Based on an assumption that the time-series and graph evolution dynamics are piecewise smooth, we identify local windows of time where the signals exhibit approximate stationarity. We then train an encoding that allows the distribution of signals within a neighborhood to be distinguished from the distribution of non-neighboring signals. We first demonstrate the performance of our proposed framework using synthetic data, and subsequently we show that it can prove beneficial for the classification task with real-world datasets.
Node Copying: A Random Graph Model for Effective Graph Sampling
Aug 04, 2022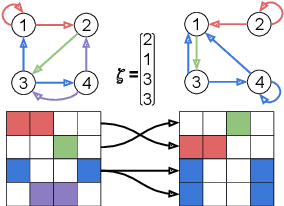
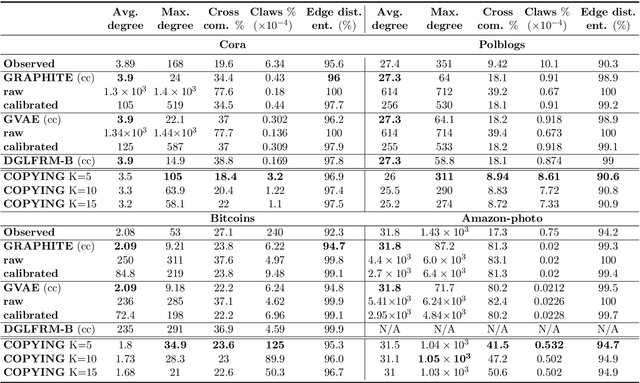
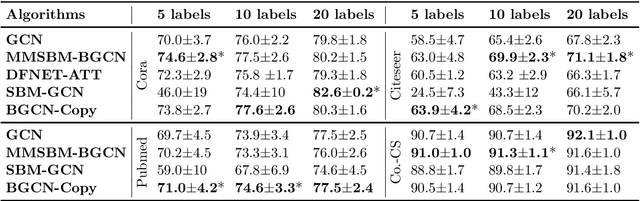
There has been an increased interest in applying machine learning techniques on relational structured-data based on an observed graph. Often, this graph is not fully representative of the true relationship amongst nodes. In these settings, building a generative model conditioned on the observed graph allows to take the graph uncertainty into account. Various existing techniques either rely on restrictive assumptions, fail to preserve topological properties within the samples or are prohibitively expensive for larger graphs. In this work, we introduce the node copying model for constructing a distribution over graphs. Sampling of a random graph is carried out by replacing each node's neighbors by those of a randomly sampled similar node. The sampled graphs preserve key characteristics of the graph structure without explicitly targeting them. Additionally, sampling from this model is extremely simple and scales linearly with the nodes. We show the usefulness of the copying model in three tasks. First, in node classification, a Bayesian formulation based on node copying achieves higher accuracy in sparse data settings. Second, we employ our proposed model to mitigate the effect of adversarial attacks on the graph topology. Last, incorporation of the model in a recommendation system setting improves recall over state-of-the-art methods.
Bag Graph: Multiple Instance Learning using Bayesian Graph Neural Networks
Feb 22, 2022
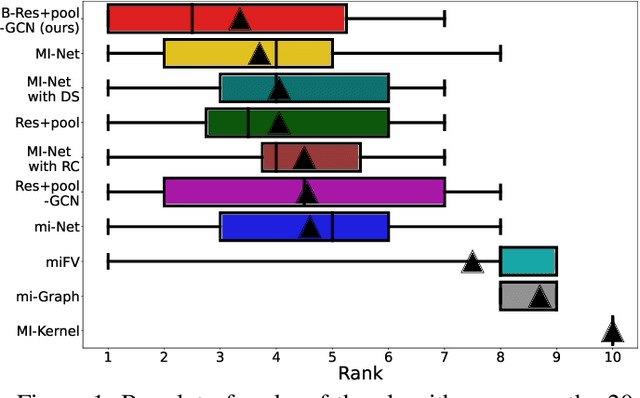
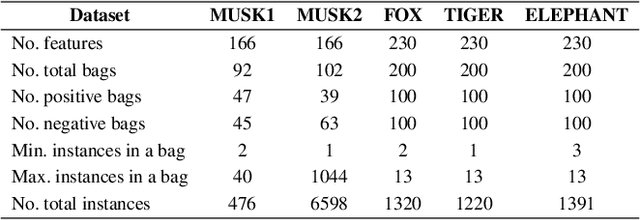
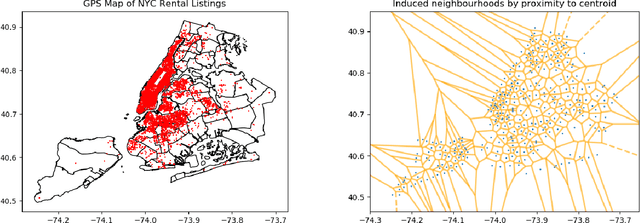
Multiple Instance Learning (MIL) is a weakly supervised learning problem where the aim is to assign labels to sets or bags of instances, as opposed to traditional supervised learning where each instance is assumed to be independent and identically distributed (IID) and is to be labeled individually. Recent work has shown promising results for neural network models in the MIL setting. Instead of focusing on each instance, these models are trained in an end-to-end fashion to learn effective bag-level representations by suitably combining permutation invariant pooling techniques with neural architectures. In this paper, we consider modelling the interactions between bags using a graph and employ Graph Neural Networks (GNNs) to facilitate end-to-end learning. Since a meaningful graph representing dependencies between bags is rarely available, we propose to use a Bayesian GNN framework that can generate a likely graph structure for scenarios where there is uncertainty in the graph or when no graph is available. Empirical results demonstrate the efficacy of the proposed technique for several MIL benchmark tasks and a distribution regression task.
Node Copying for Protection Against Graph Neural Network Topology Attacks
Jul 09, 2020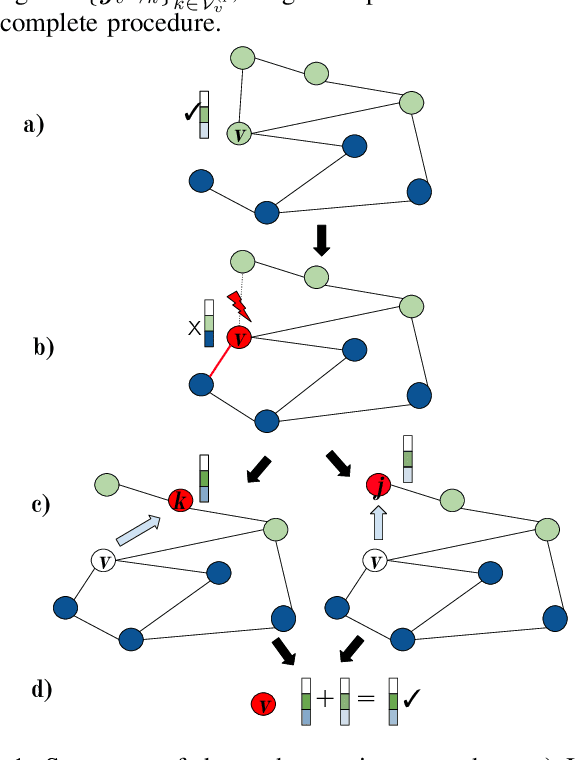
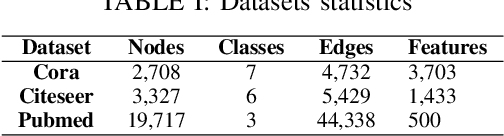

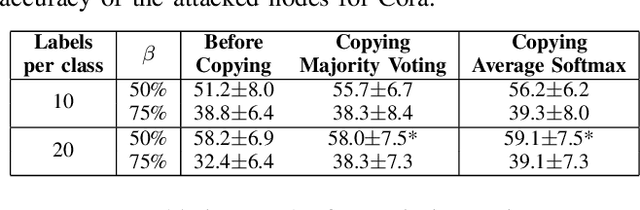
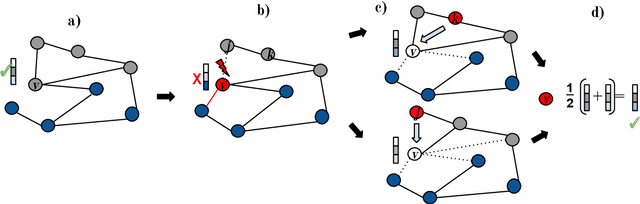
Adversarial attacks can affect the performance of existing deep learning models. With the increased interest in graph based machine learning techniques, there have been investigations which suggest that these models are also vulnerable to attacks. In particular, corruptions of the graph topology can degrade the performance of graph based learning algorithms severely. This is due to the fact that the prediction capability of these algorithms relies mostly on the similarity structure imposed by the graph connectivity. Therefore, detecting the location of the corruption and correcting the induced errors becomes crucial. There has been some recent work which tackles the detection problem, however these methods do not address the effect of the attack on the downstream learning task. In this work, we propose an algorithm that uses node copying to mitigate the degradation in classification that is caused by adversarial attacks. The proposed methodology is applied only after the model for the downstream task is trained and the added computation cost scales well for large graphs. Experimental results show the effectiveness of our approach for several real world datasets.