 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Feature Caching for Training-free Acceleration of Molecular Geometry Generation
Oct 06, 2025Flow matching models generate high-fidelity molecular geometries but incur significant computational costs during inference, requiring hundreds of network evaluations. This inference overhead becomes the primary bottleneck when such models are employed in practice to sample large numbers of molecular candidates. This work discusses a training-free caching strategy that accelerates molecular geometry generation by predicting intermediate hidden states across solver steps. The proposed method operates directly on the SE(3)-equivariant backbone, is compatible with pretrained models, and is orthogonal to existing training-based accelerations and system-level optimizations. Experiments on the GEOM-Drugs dataset demonstrate that caching achieves a twofold reduction in wall-clock inference time at matched sample quality and a speedup of up to 3x compared to the base model with minimal sample quality degradation. Because these gains compound with other optimizations, applying caching alongside other general, lossless optimizations yield as much as a 7x speedup.
Predicting Probabilities of Error to Combine Quantization and Early Exiting: QuEE
Jun 20, 2024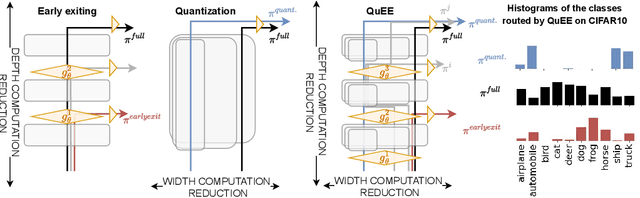
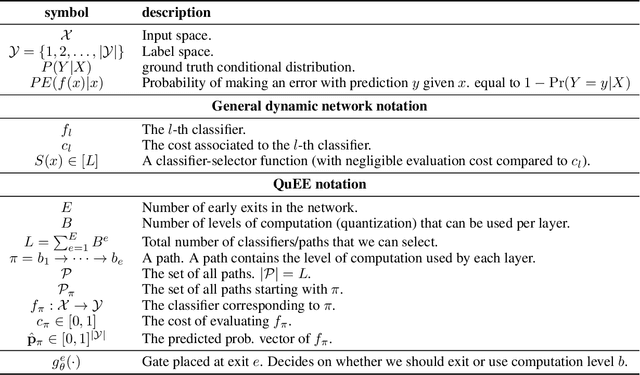
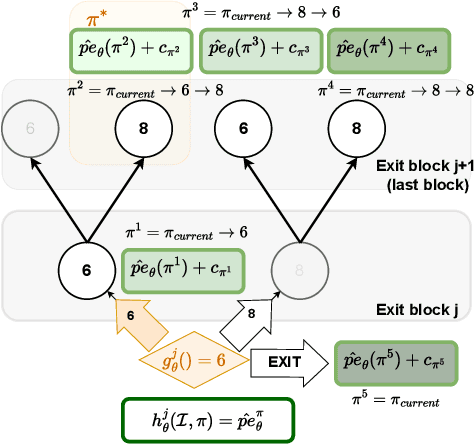

Machine learning models can solve complex tasks but often require significant computational resources during inference. This has led to the development of various post-training computation reduction methods that tackle this issue in different ways, such as quantization which reduces the precision of weights and arithmetic operations, and dynamic networks which adapt computation to the sample at hand. In this work, we propose a more general dynamic network that can combine both quantization and early exit dynamic network: QuEE. Our algorithm can be seen as a form of soft early exiting or input-dependent compression. Rather than a binary decision between exiting or continuing, we introduce the possibility of continuing with reduced computation. This complicates the traditionally considered early exiting problem, which we solve through a principled formulation. The crucial factor of our approach is accurate prediction of the potential accuracy improvement achievable through further computation. We demonstrate the effectiveness of our method through empirical evaluation, as well as exploring the conditions for its success on 4 classification datasets.
Uncertainty for Active Learning on Graphs
May 02, 2024Uncertainty Sampling is an Active Learning strategy that aims to improve the data efficiency of machine learning models by iteratively acquiring labels of data points with the highest uncertainty. While it has proven effective for independent data its applicability to graphs remains under-explored. We propose the first extensive study of Uncertainty Sampling for node classification: (1) We benchmark Uncertainty Sampling beyond predictive uncertainty and highlight a significant performance gap to other Active Learning strategies. (2) We develop ground-truth Bayesian uncertainty estimates in terms of the data generating process and prove their effectiveness in guiding Uncertainty Sampling toward optimal queries. We confirm our results on synthetic data and design an approximate approach that consistently outperforms other uncertainty estimators on real datasets. (3) Based on this analysis, we relate pitfalls in modeling uncertainty to existing methods. Our analysis enables and informs the development of principled uncertainty estimation on graphs.
Adversarial Training for Graph Neural Networks
Jun 27, 2023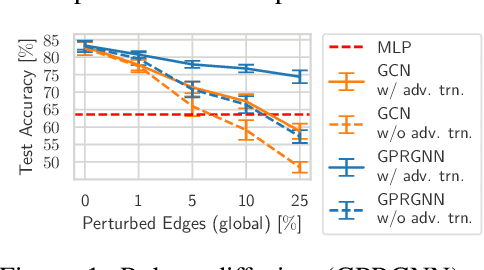
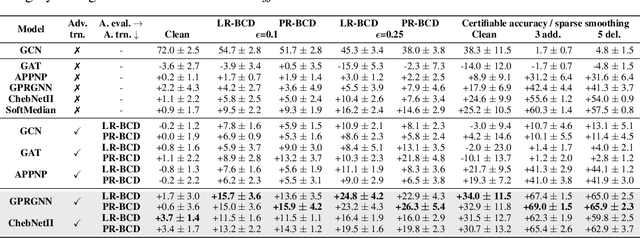
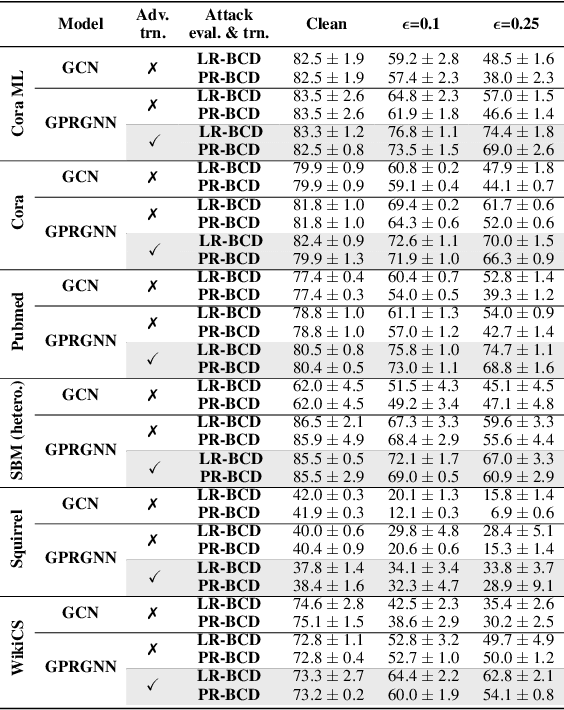
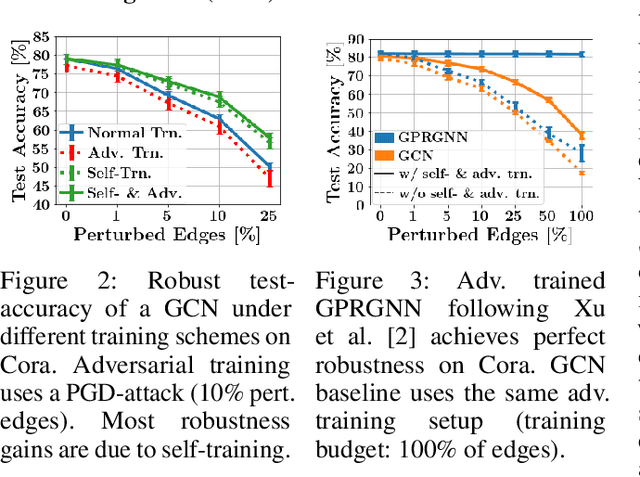
Despite its success in the image domain, adversarial training does not (yet) stand out as an effective defense for Graph Neural Networks (GNNs) against graph structure perturbations. In the pursuit of fixing adversarial training (1) we show and overcome fundamental theoretical as well as practical limitations of the adopted graph learning setting in prior work; (2) we reveal that more flexible GNNs based on learnable graph diffusion are able to adjust to adversarial perturbations, while the learned message passing scheme is naturally interpretable; (3) we introduce the first attack for structure perturbations that, while targeting multiple nodes at once, is capable of handling global (graph-level) as well as local (node-level) constraints. Including these contributions, we demonstrate that adversarial training is a state-of-the-art defense against adversarial structure perturbations.
Uncertainty Estimation for Molecules: Desiderata and Methods
Jun 20, 2023
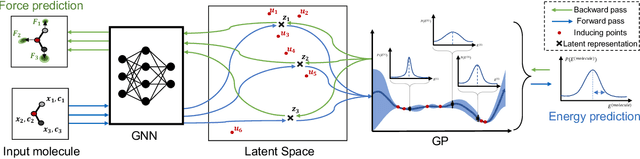
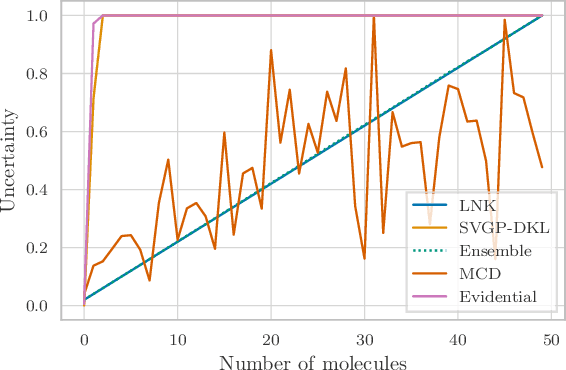
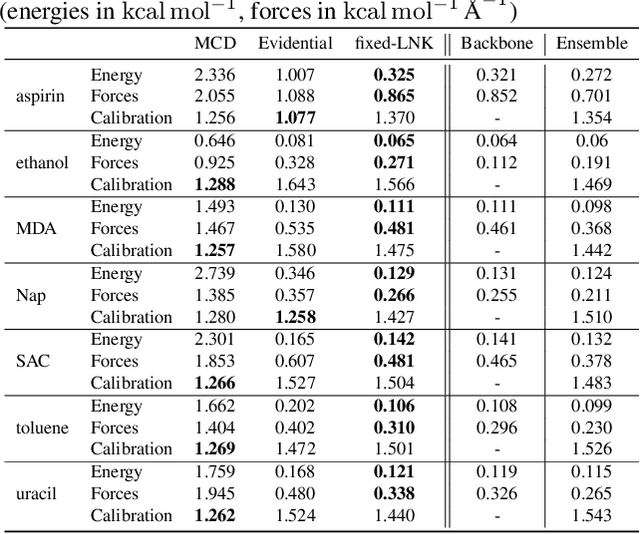
Graph Neural Networks (GNNs) are promising surrogates for quantum mechanical calculations as they establish unprecedented low errors on collections of molecular dynamics (MD) trajectories. Thanks to their fast inference times they promise to accelerate computational chemistry applications. Unfortunately, despite low in-distribution (ID) errors, such GNNs might be horribly wrong for out-of-distribution (OOD) samples. Uncertainty estimation (UE) may aid in such situations by communicating the model's certainty about its prediction. Here, we take a closer look at the problem and identify six key desiderata for UE in molecular force fields, three 'physics-informed' and three 'application-focused' ones. To overview the field, we survey existing methods from the field of UE and analyze how they fit to the set desiderata. By our analysis, we conclude that none of the previous works satisfies all criteria. To fill this gap, we propose Localized Neural Kernel (LNK) a Gaussian Process (GP)-based extension to existing GNNs satisfying the desiderata. In our extensive experimental evaluation, we test four different UE with three different backbones and two datasets. In out-of-equilibrium detection, we find LNK yielding up to 2.5 and 2.1 times lower errors in terms of AUC-ROC score than dropout or evidential regression-based methods while maintaining high predictive performance.
Edge Directionality Improves Learning on Heterophilic Graphs
May 17, 2023



Graph Neural Networks (GNNs) have become the de-facto standard tool for modeling relational data. However, while many real-world graphs are directed, the majority of today's GNN models discard this information altogether by simply making the graph undirected. The reasons for this are historical: 1) many early variants of spectral GNNs explicitly required undirected graphs, and 2) the first benchmarks on homophilic graphs did not find significant gain from using direction. In this paper, we show that in heterophilic settings, treating the graph as directed increases the effective homophily of the graph, suggesting a potential gain from the correct use of directionality information. To this end, we introduce Directed Graph Neural Network (Dir-GNN), a novel general framework for deep learning on directed graphs. Dir-GNN can be used to extend any Message Passing Neural Network (MPNN) to account for edge directionality information by performing separate aggregations of the incoming and outgoing edges. We prove that Dir-GNN matches the expressivity of the Directed Weisfeiler-Lehman test, exceeding that of conventional MPNNs. In extensive experiments, we validate that while our framework leaves performance unchanged on homophilic datasets, it leads to large gains over base models such as GCN, GAT and GraphSage on heterophilic benchmarks, outperforming much more complex methods and achieving new state-of-the-art results.
Accuracy is not the only Metric that matters: Estimating the Energy Consumption of Deep Learning Models
Apr 03, 2023



Modern machine learning models have started to consume incredible amounts of energy, thus incurring large carbon footprints (Strubell et al., 2019). To address this issue, we have created an energy estimation pipeline1, which allows practitioners to estimate the energy needs of their models in advance, without actually running or training them. We accomplished this, by collecting high-quality energy data and building a first baseline model, capable of predicting the energy consumption of DL models by accumulating their estimated layer-wise energies.
Training, Architecture, and Prior for Deterministic Uncertainty Methods
Mar 10, 2023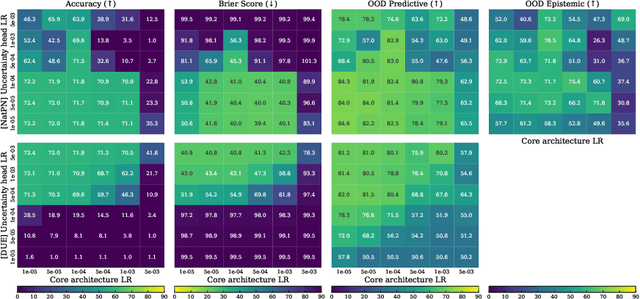
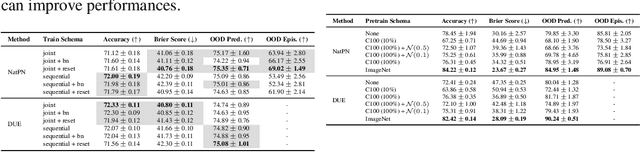


Accurate and efficient uncertainty estimation is crucial to build reliable Machine Learning (ML) models capable to provide calibrated uncertainty estimates, generalize and detect Out-Of-Distribution (OOD) datasets. To this end, Deterministic Uncertainty Methods (DUMs) is a promising model family capable to perform uncertainty estimation in a single forward pass. This work investigates important design choices in DUMs: (1) we show that training schemes decoupling the core architecture and the uncertainty head schemes can significantly improve uncertainty performances. (2) we demonstrate that the core architecture expressiveness is crucial for uncertainty performance and that additional architecture constraints to avoid feature collapse can deteriorate the trade-off between OOD generalization and detection. (3) Contrary to other Bayesian models, we show that the prior defined by DUMs do not have a strong effect on the final performances.
On the Robustness and Anomaly Detection of Sparse Neural Networks
Jul 09, 2022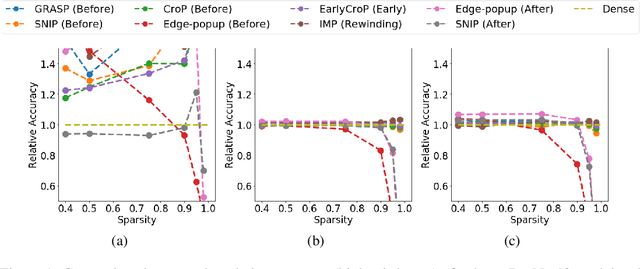

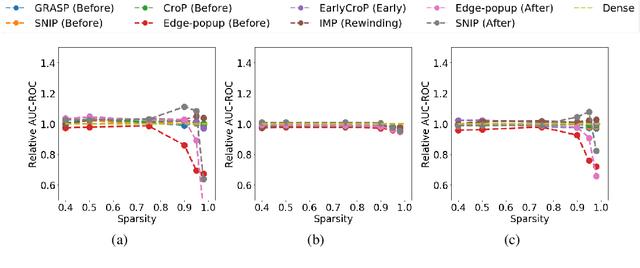

The robustness and anomaly detection capability of neural networks are crucial topics for their safe adoption in the real-world. Moreover, the over-parameterization of recent networks comes with high computational costs and raises questions about its influence on robustness and anomaly detection. In this work, we show that sparsity can make networks more robust and better anomaly detectors. To motivate this even further, we show that a pre-trained neural network contains, within its parameter space, sparse subnetworks that are better at these tasks without any further training. We also show that structured sparsity greatly helps in reducing the complexity of expensive robustness and detection methods, while maintaining or even improving their results on these tasks. Finally, we introduce a new method, SensNorm, which uses the sensitivity of weights derived from an appropriate pruning method to detect anomalous samples in the input.
Winning the Lottery Ahead of Time: Efficient Early Network Pruning
Jun 21, 2022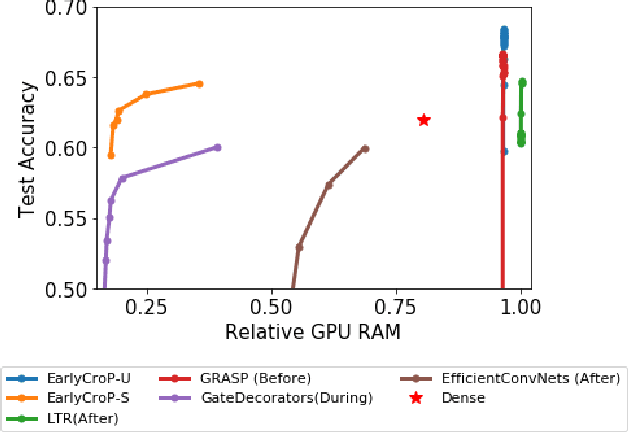
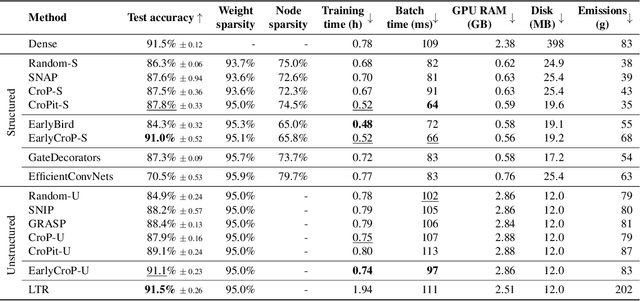
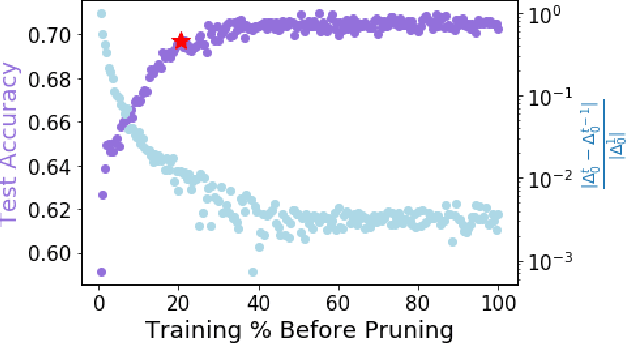
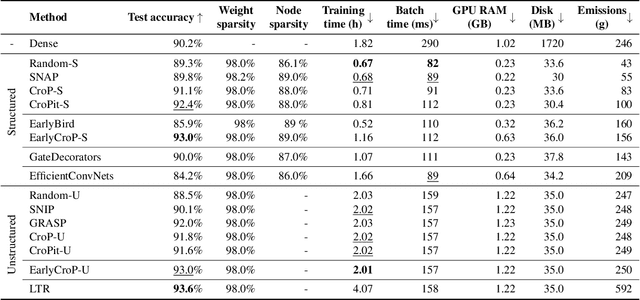
Pruning, the task of sparsifying deep neural networks, received increasing attention recently. Although state-of-the-art pruning methods extract highly sparse models, they neglect two main challenges: (1) the process of finding these sparse models is often very expensive; (2) unstructured pruning does not provide benefits in terms of GPU memory, training time, or carbon emissions. We propose Early Compression via Gradient Flow Preservation (EarlyCroP), which efficiently extracts state-of-the-art sparse models before or early in training addressing challenge (1), and can be applied in a structured manner addressing challenge (2). This enables us to train sparse networks on commodity GPUs whose dense versions would be too large, thereby saving costs and reducing hardware requirements. We empirically show that EarlyCroP outperforms a rich set of baselines for many tasks (incl. classification, regression) and domains (incl. computer vision, natural language processing, and reinforcment learning). EarlyCroP leads to accuracy comparable to dense training while outperforming pruning baselines.