 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Feature Caching for Training-free Acceleration of Molecular Geometry Generation
Oct 06, 2025Flow matching models generate high-fidelity molecular geometries but incur significant computational costs during inference, requiring hundreds of network evaluations. This inference overhead becomes the primary bottleneck when such models are employed in practice to sample large numbers of molecular candidates. This work discusses a training-free caching strategy that accelerates molecular geometry generation by predicting intermediate hidden states across solver steps. The proposed method operates directly on the SE(3)-equivariant backbone, is compatible with pretrained models, and is orthogonal to existing training-based accelerations and system-level optimizations. Experiments on the GEOM-Drugs dataset demonstrate that caching achieves a twofold reduction in wall-clock inference time at matched sample quality and a speedup of up to 3x compared to the base model with minimal sample quality degradation. Because these gains compound with other optimizations, applying caching alongside other general, lossless optimizations yield as much as a 7x speedup.
3D Labeling Tool
Jul 23, 2022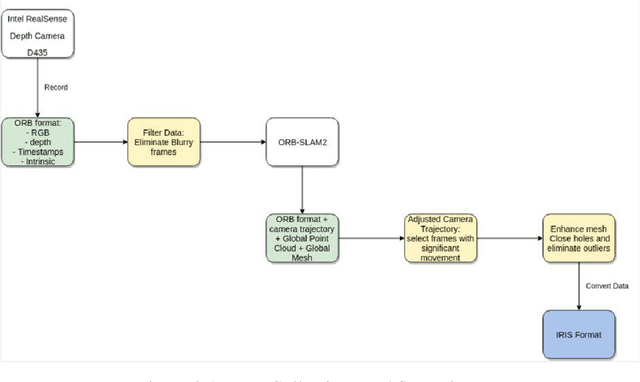



Training and testing supervised object detection models require a large collection of images with ground truth labels. Labels define object classes in the image, as well as their locations, shape, and possibly other information such as pose. The labeling process has proven extremely time consuming, even with the presence of manpower. We introduce a novel labeling tool for 2D images as well as 3D triangular meshes: 3D Labeling Tool (3DLT). This is a standalone, feature-heavy and cross-platform software that does not require installation and can run on Windows, macOS and Linux-based distributions. Instead of labeling the same object on every image separately like current tools, we use depth information to reconstruct a triangular mesh from said images and label the object only once on the aforementioned mesh. We use registration to simplify 3D labeling, outlier detection to improve 2D bounding box calculation and surface reconstruction to expand labeling possibility to large point clouds. Our tool is tested against state of the art methods and it greatly surpasses them in terms of speed while preserving accuracy and ease of use.
On the Robustness and Anomaly Detection of Sparse Neural Networks
Jul 09, 2022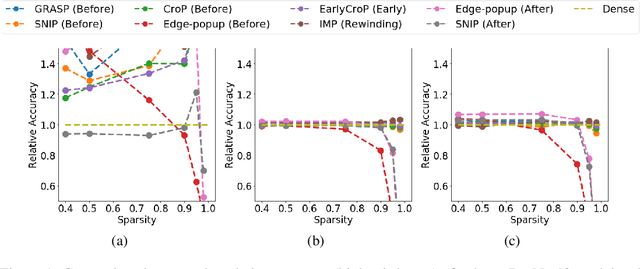

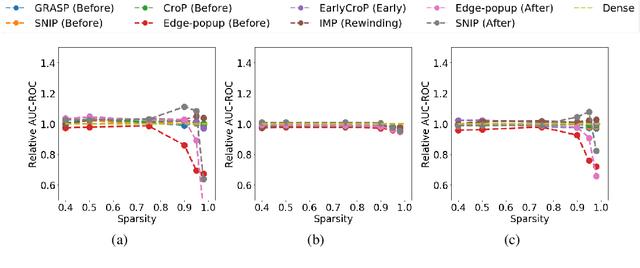

The robustness and anomaly detection capability of neural networks are crucial topics for their safe adoption in the real-world. Moreover, the over-parameterization of recent networks comes with high computational costs and raises questions about its influence on robustness and anomaly detection. In this work, we show that sparsity can make networks more robust and better anomaly detectors. To motivate this even further, we show that a pre-trained neural network contains, within its parameter space, sparse subnetworks that are better at these tasks without any further training. We also show that structured sparsity greatly helps in reducing the complexity of expensive robustness and detection methods, while maintaining or even improving their results on these tasks. Finally, we introduce a new method, SensNorm, which uses the sensitivity of weights derived from an appropriate pruning method to detect anomalous samples in the input.
Winning the Lottery Ahead of Time: Efficient Early Network Pruning
Jun 21, 2022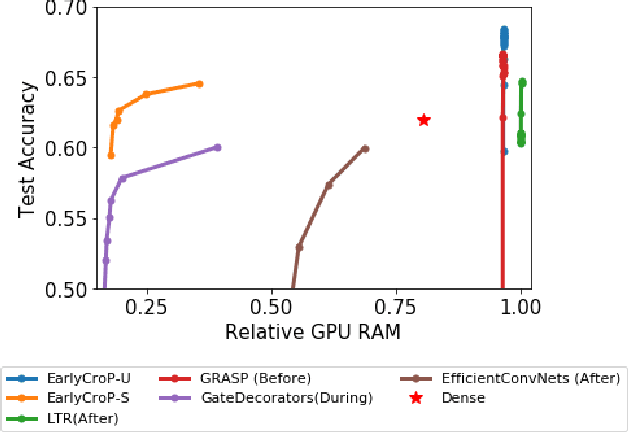
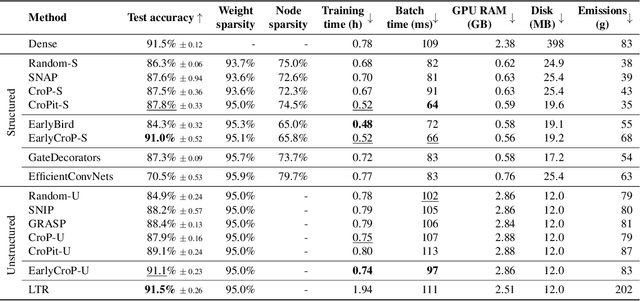
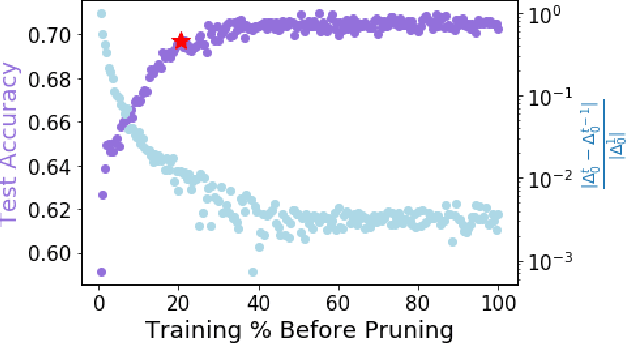
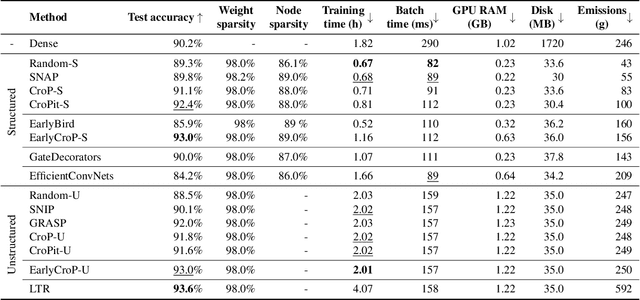
Pruning, the task of sparsifying deep neural networks, received increasing attention recently. Although state-of-the-art pruning methods extract highly sparse models, they neglect two main challenges: (1) the process of finding these sparse models is often very expensive; (2) unstructured pruning does not provide benefits in terms of GPU memory, training time, or carbon emissions. We propose Early Compression via Gradient Flow Preservation (EarlyCroP), which efficiently extracts state-of-the-art sparse models before or early in training addressing challenge (1), and can be applied in a structured manner addressing challenge (2). This enables us to train sparse networks on commodity GPUs whose dense versions would be too large, thereby saving costs and reducing hardware requirements. We empirically show that EarlyCroP outperforms a rich set of baselines for many tasks (incl. classification, regression) and domains (incl. computer vision, natural language processing, and reinforcment learning). EarlyCroP leads to accuracy comparable to dense training while outperforming pruning baselines.