 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatterGen: a generative model for inorganic materials design
Dec 06, 2023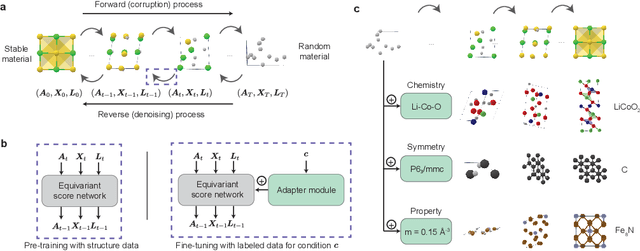
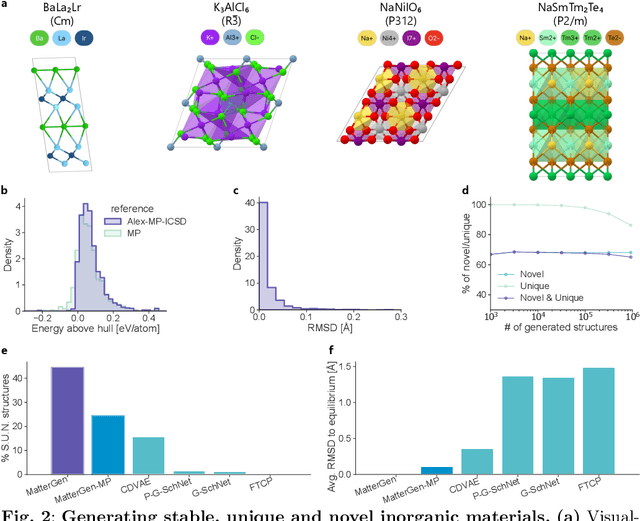
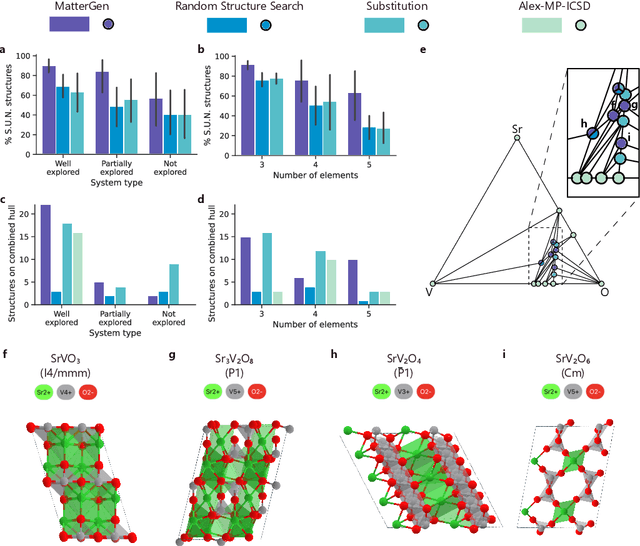
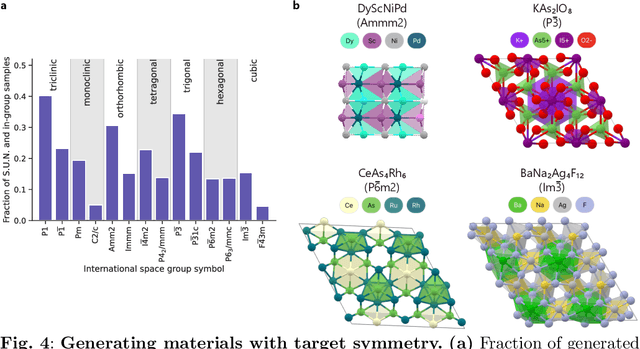
The design of functional materials with desired properties is essential in driving technological advances in areas like energy storage, catalysis, and carbon capture. Generative models provide a new paradigm for materials design by directly generating entirely novel materials given desired property constraints. Despite recent progress, current generative models have low success rate in proposing stable crystals, or can only satisfy a very limited set of property constraints. Here, we present MatterGen, a model that generates stable, diverse inorganic materials across the periodic table and can further be fine-tuned to steer the generation towards a broad range of property constraints. To enable this, we introduce a new diffusion-based generative process that produces crystalline structures by gradually refining atom types, coordinates, and the periodic lattice. We further introduce adapter modules to enable fine-tuning towards any given property constraints with a labeled dataset. Compared to prior generative models, structures produced by MatterGen are more than twice as likely to be novel and stable, and more than 15 times closer to the local energy minimum. After fine-tuning, MatterGen successfully generates stable, novel materials with desired chemistry, symmetry, as well as mechanical, electronic and magnetic properties. Finally, we demonstrate multi-property materials design capabilities by proposing structures that have both high magnetic density and a chemical composition with low supply-chain risk. We believe that the quality of generated materials and the breadth of MatterGen's capabilities represent a major advancement towards creating a universal generative model for materials design.
Adversarial Training for Graph Neural Networks
Jun 27, 2023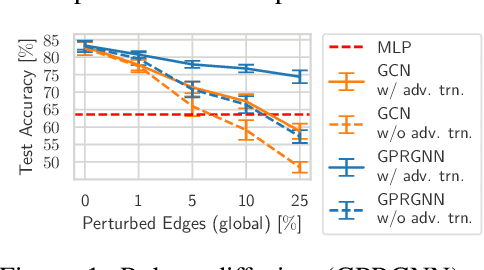
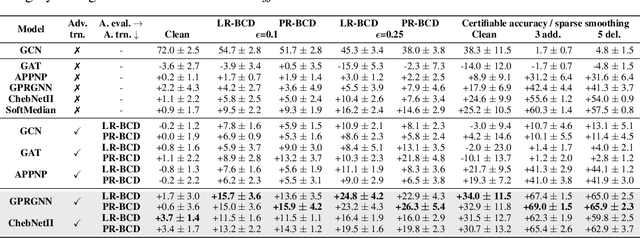
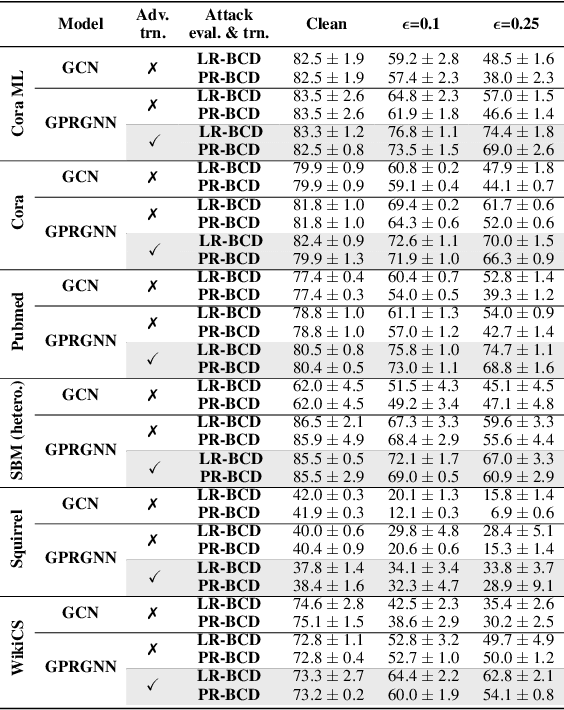
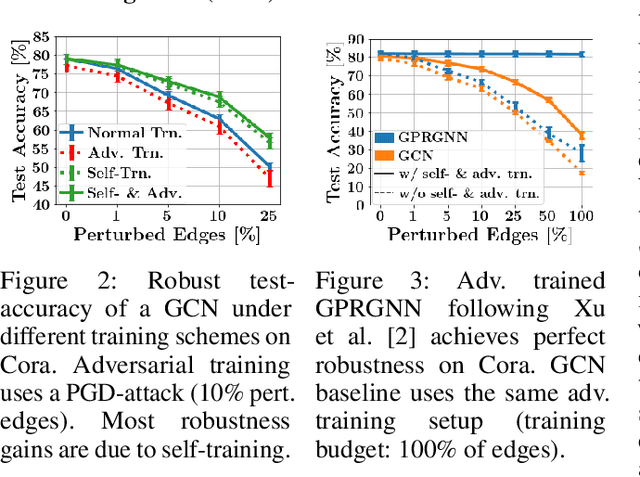
Despite its success in the image domain, adversarial training does not (yet) stand out as an effective defense for Graph Neural Networks (GNNs) against graph structure perturbations. In the pursuit of fixing adversarial training (1) we show and overcome fundamental theoretical as well as practical limitations of the adopted graph learning setting in prior work; (2) we reveal that more flexible GNNs based on learnable graph diffusion are able to adjust to adversarial perturbations, while the learned message passing scheme is naturally interpretable; (3) we introduce the first attack for structure perturbations that, while targeting multiple nodes at once, is capable of handling global (graph-level) as well as local (node-level) constraints. Including these contributions, we demonstrate that adversarial training is a state-of-the-art defense against adversarial structure perturbations.
Training Differentially Private Graph Neural Networks with Random Walk Sampling
Jan 02, 2023Deep learning models are known to put the privacy of their training data at risk, which poses challenges for their safe and ethical release to the public. Differentially private stochastic gradient descent is the de facto standard for training neural networks without leaking sensitive information about the training data. However, applying it to models for graph-structured data poses a novel challenge: unlike with i.i.d. data, sensitive information about a node in a graph cannot only leak through its gradients, but also through the gradients of all nodes within a larger neighborhood. In practice, this limits privacy-preserving deep learning on graphs to very shallow graph neural networks. We propose to solve this issue by training graph neural networks on disjoint subgraphs of a given training graph. We develop three random-walk-based methods for generating such disjoint subgraphs and perform a careful analysis of the data-generating distributions to provide strong privacy guarantees. Through extensive experiments, we show that our method greatly outperforms the state-of-the-art baseline on three large graphs, and matches or outperforms it on four smaller ones.
On the Robustness and Anomaly Detection of Sparse Neural Networks
Jul 09, 2022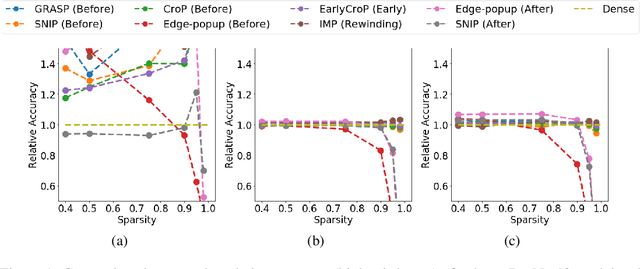


The robustness and anomaly detection capability of neural networks are crucial topics for their safe adoption in the real-world. Moreover, the over-parameterization of recent networks comes with high computational costs and raises questions about its influence on robustness and anomaly detection. In this work, we show that sparsity can make networks more robust and better anomaly detectors. To motivate this even further, we show that a pre-trained neural network contains, within its parameter space, sparse subnetworks that are better at these tasks without any further training. We also show that structured sparsity greatly helps in reducing the complexity of expensive robustness and detection methods, while maintaining or even improving their results on these tasks. Finally, we introduce a new method, SensNorm, which uses the sensitivity of weights derived from an appropriate pruning method to detect anomalous samples in the input.
Winning the Lottery Ahead of Time: Efficient Early Network Pruning
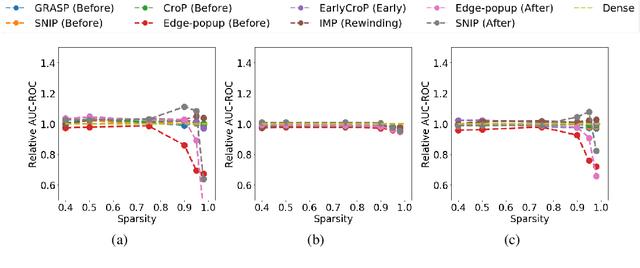
Jun 21, 2022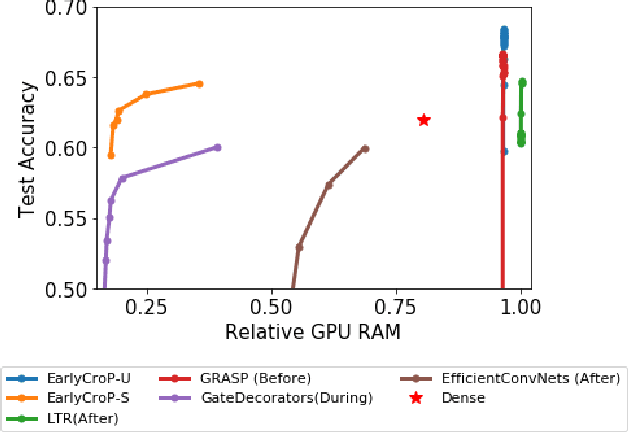
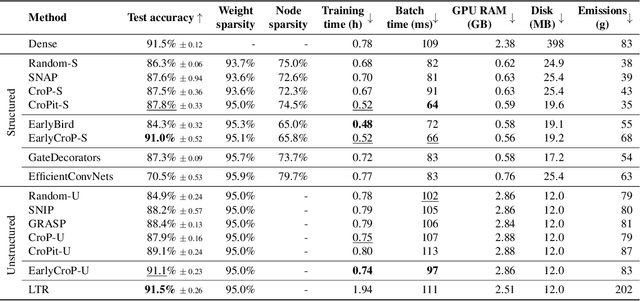
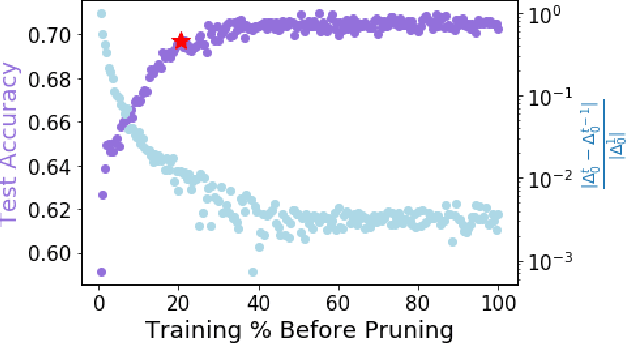
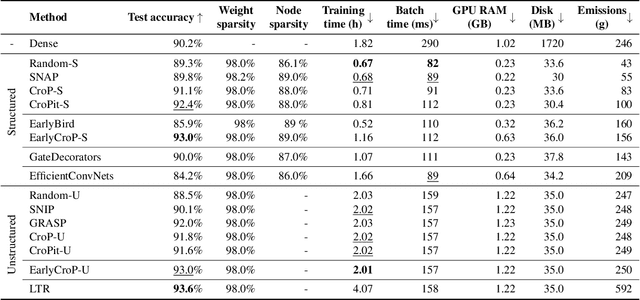
Pruning, the task of sparsifying deep neural networks, received increasing attention recently. Although state-of-the-art pruning methods extract highly sparse models, they neglect two main challenges: (1) the process of finding these sparse models is often very expensive; (2) unstructured pruning does not provide benefits in terms of GPU memory, training time, or carbon emissions. We propose Early Compression via Gradient Flow Preservation (EarlyCroP), which efficiently extracts state-of-the-art sparse models before or early in training addressing challenge (1), and can be applied in a structured manner addressing challenge (2). This enables us to train sparse networks on commodity GPUs whose dense versions would be too large, thereby saving costs and reducing hardware requirements. We empirically show that EarlyCroP outperforms a rich set of baselines for many tasks (incl. classification, regression) and domains (incl. computer vision, natural language processing, and reinforcment learning). EarlyCroP leads to accuracy comparable to dense training while outperforming pruning baselines.
Monte Carlo EM for Deep Time Series Anomaly Detection
Dec 29, 2021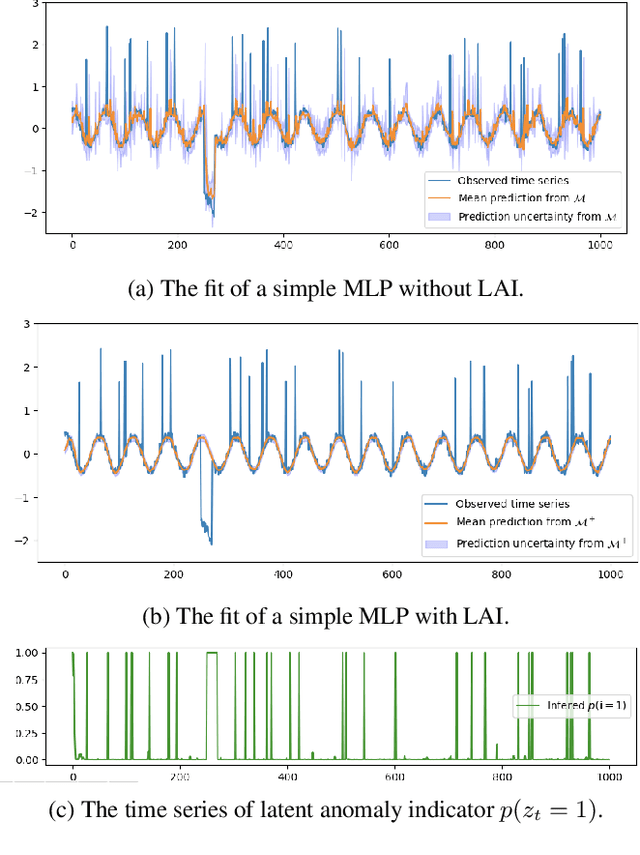


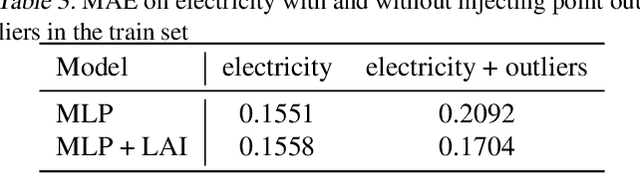
Time series data are often corrupted by outliers or other kinds of anomalies. Identifying the anomalous points can be a goal on its own (anomaly detection), or a means to improving performance of other time series tasks (e.g. forecasting). Recent deep-learning-based approaches to anomaly detection and forecasting commonly assume that the proportion of anomalies in the training data is small enough to ignore, and treat the unlabeled data as coming from the nominal data distribution. We present a simple yet effective technique for augmenting existing time series models so that they explicitly account for anomalies in the training data. By augmenting the training data with a latent anomaly indicator variable whose distribution is inferred while training the underlying model using Monte Carlo EM, our method simultaneously infers anomalous points while improving model performance on nominal data. We demonstrate the effectiveness of the approach by combining it with a simple feed-forward forecasting model. We investigate how anomalies in the train set affect the training of forecasting models, which are commonly used for time series anomaly detection, and show that our method improves the training of the model.
Robustness of Graph Neural Networks at Scale
Nov 08, 2021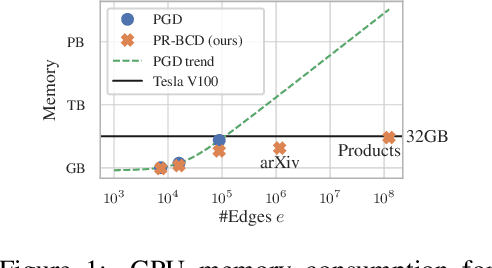
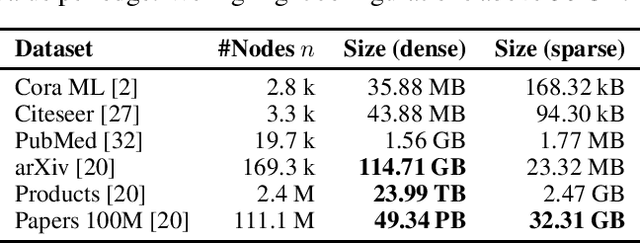

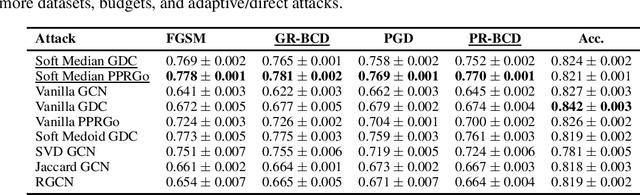
Graph Neural Networks (GNNs) are increasingly important given their popularity and the diversity of applications. Yet, existing studies of their vulnerability to adversarial attacks rely on relatively small graphs. We address this gap and study how to attack and defend GNNs at scale. We propose two sparsity-aware first-order optimization attacks that maintain an efficient representation despite optimizing over a number of parameters which is quadratic in the number of nodes. We show that common surrogate losses are not well-suited for global attacks on GNNs. Our alternatives can double the attack strength. Moreover, to improve GNNs' reliability we design a robust aggregation function, Soft Median, resulting in an effective defense at all scales. We evaluate our attacks and defense with standard GNNs on graphs more than 100 times larger compared to previous work. We even scale one order of magnitude further by extending our techniques to a scalable GNN.
Graph Posterior Network: Bayesian Predictive Uncertainty for Node Classification
Oct 26, 2021
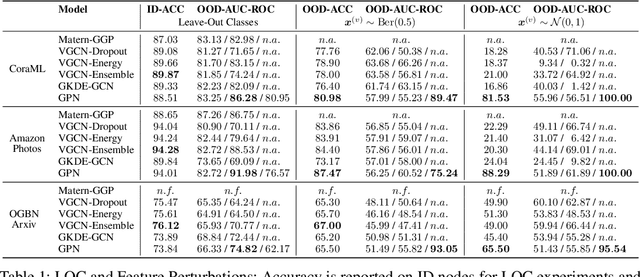
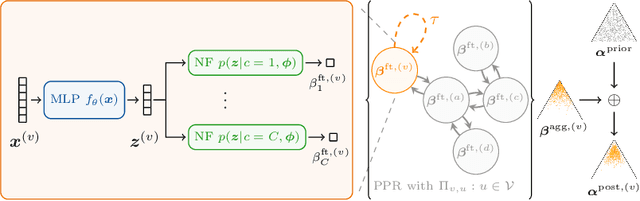

The interdependence between nodes in graphs is key to improve class predictions on nodes and utilized in approaches like Label Propagation (LP) or in Graph Neural Networks (GNN). Nonetheless, uncertainty estimation for non-independent node-level predictions is under-explored. In this work, we explore uncertainty quantification for node classification in three ways: (1) We derive three axioms explicitly characterizing the expected predictive uncertainty behavior in homophilic attributed graphs. (2) We propose a new model Graph Posterior Network (GPN) which explicitly performs Bayesian posterior updates for predictions on interdependent nodes. GPN provably obeys the proposed axioms. (3) We extensively evaluate GPN and a strong set of baselines on semi-supervised node classification including detection of anomalous features, and detection of left-out classes. GPN outperforms existing approaches for uncertainty estimation in the experiments.
A Study of Joint Graph Inference and Forecasting
Sep 10, 2021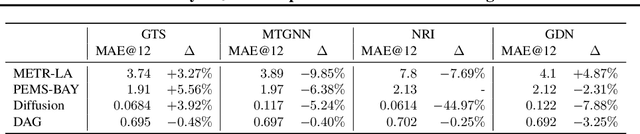
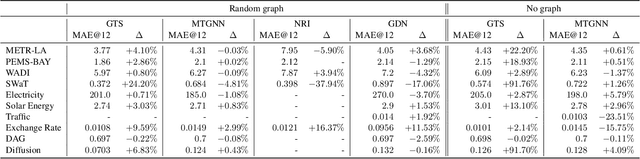
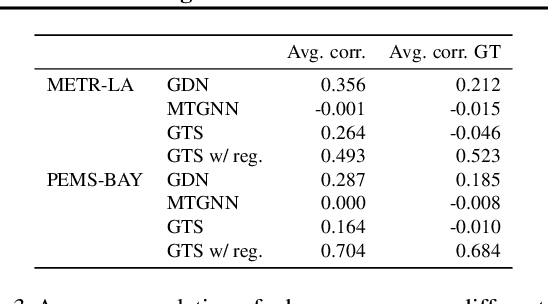
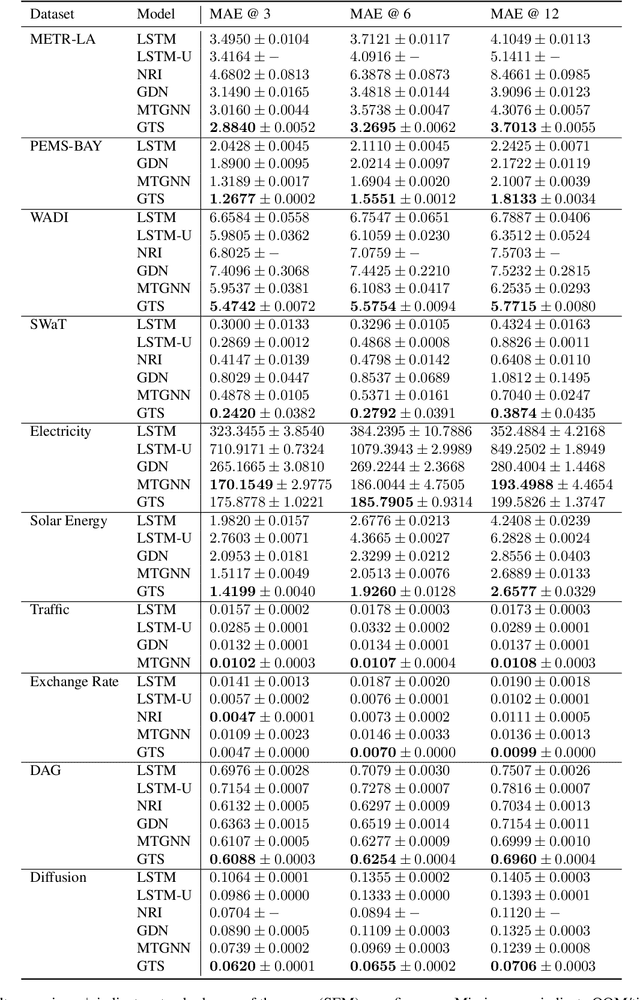
We study a recent class of models which uses graph neural networks (GNNs) to improve forecasting in multivariate time series. The core assumption behind these models is that there is a latent graph between the time series (nodes) that governs the evolution of the multivariate time series. By parameterizing a graph in a differentiable way, the models aim to improve forecasting quality. We compare four recent models of this class on the forecasting task. Further, we perform ablations to study their behavior under changing conditions, e.g., when disabling the graph-learning modules and providing the ground-truth relations instead. Based on our findings, we propose novel ways of combining the existing architectures.
On Out-of-distribution Detection with Energy-based Models
Jul 03, 2021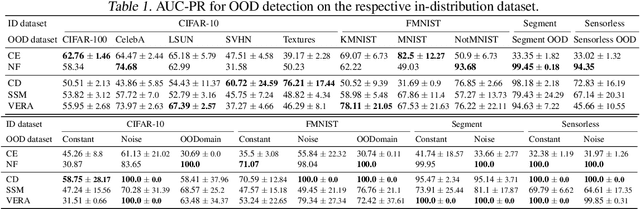
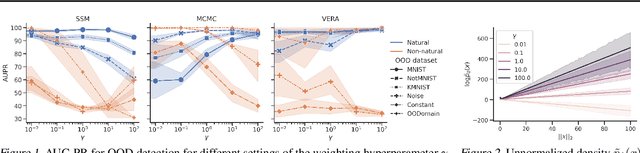
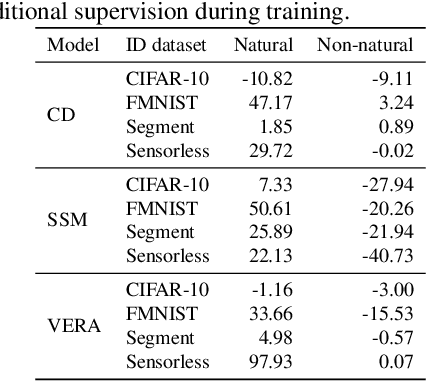
Several density estimation methods have shown to fail to detect out-of-distribution (OOD) samples by assigning higher likelihoods to anomalous data. Energy-based models (EBMs) are flexible, unnormalized density models which seem to be able to improve upon this failure mode. In this work, we provide an extensive study investigating OOD detection with EBMs trained with different approaches on tabular and image data and find that EBMs do not provide consistent advantages. We hypothesize that EBMs do not learn semantic features despite their discriminative structure similar to Normalizing Flows. To verify this hypotheses, we show that supervision and architectural restrictions improve the OOD detection of EBMs independent of the training approach.