 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Robustness against Backdoor Attacks via the Primal-Dual Perspective on Differential Privacy
May 20, 2026Randomized smoothing is a powerful tool for certifying robustness to adversarial perturbations, including poisoning attacks via randomized training and evasion attacks via randomized inference. Extending these guarantees to backdoor attacks, where training and test data are jointly perturbed, remains challenging because training- and test-time randomized mechanisms must be analyzed within a single robustness certificate. We address this by connecting randomized smoothing to the dual view of differential privacy through privacy profiles, which provide a numerical procedure for composing heterogeneous mechanisms. The resulting framework enables tight, modular, end-to-end certification of complex, composed mechanisms while leveraging existing analyses of differentially private mechanisms. We instantiate the framework for DP-SGD and Deep Partition Aggregation with inference-time smoothing, deriving joint robustness guarantees against both training-time and inference-time attacks. Experiments on MNIST and CIFAR-10 demonstrate the effectiveness of our framework. Overall, we provide a principled and general framework for using composite mechanisms to certify robustness under complex threat models that better capture the capabilities of real-world adversaries.
Population Risk Bounds for Kolmogorov-Arnold Networks Trained by DP-SGD with Correlated Noise
May 12, 2026We establish the first population risk bounds for Kolmogorov-Arnold Networks (KANs) trained by mini-batch SGD with gradient clipping, covering non-private SGD as well as differentially private SGD (DP-SGD) with Gaussian perturbations that interpolate between independent and temporally correlated noise. This setting is substantially closer to practice than prior KAN theory along two axes: training is by mini-batch SGD, the standard recipe for modern networks, rather than full-batch gradient descent (GD); and correlated-noise mechanisms have empirically shown a more favorable privacy-utility tradeoff than independent-noise mechanisms. Our results cover the corresponding full-batch GD and independent-noise DP-GD results for KANs by Wang et al. (2026), while yielding sharper fixed-second-layer specializations. The technical core is a new analysis route for correlated-noise DP training in the non-convex regime. Temporal dependence breaks the conditional-centering structure underlying standard one-step SGD arguments, and the projection step obstructs the exact cancellation structure of correlated perturbations. We address these difficulties through an auxiliary unprojected dynamics, a shifted iterate that absorbs the current noise perturbation, and a high-probability bootstrap certifying projection inactivity. Combining this optimization analysis with a stability-based generalization argument yields the stated population risk bounds. To the best of our knowledge, this is the first optimization and population risk analysis of a correlated-noise mechanism for DP training beyond convex learning, in particular for neural networks.
Amplified Patch-Level Differential Privacy for Free via Random Cropping
Mar 25, 2026Random cropping is one of the most common data augmentation techniques in computer vision, yet the role of its inherent randomness in training differentially private machine learning models has thus far gone unexplored. We observe that when sensitive content in an image is spatially localized, such as a face or license plate, random cropping can probabilistically exclude that content from the model's input. This introduces a third source of stochasticity in differentially private training with stochastic gradient descent, in addition to gradient noise and minibatch sampling. This additional randomness amplifies differential privacy without requiring changes to model architecture or training procedure. We formalize this effect by introducing a patch-level neighboring relation for vision data and deriving tight privacy bounds for differentially private stochastic gradient descent (DP-SGD) when combined with random cropping. Our analysis quantifies the patch inclusion probability and shows how it composes with minibatch sampling to yield a lower effective sampling rate. Empirically, we validate that patch-level amplification improves the privacy-utility trade-off across multiple segmentation architectures and datasets. Our results demonstrate that aligning privacy accounting with domain structure and additional existing sources of randomness can yield stronger guarantees at no additional cost.
* Published at TMLR
Sampling-Free Privacy Accounting for Matrix Mechanisms under Random Allocation
Jan 29, 2026We study privacy amplification for differentially private model training with matrix factorization under random allocation (also known as the balls-in-bins model). Recent work by Choquette-Choo et al. (2025) proposes a sampling-based Monte Carlo approach to compute amplification parameters in this setting. However, their guarantees either only hold with some high probability or require random abstention by the mechanism. Furthermore, the required number of samples for ensuring $(ε,δ)$-DP is inversely proportional to $δ$. In contrast, we develop sampling-free bounds based on Rényi divergence and conditional composition. The former is facilitated by a dynamic programming formulation to efficiently compute the bounds. The latter complements it by offering stronger privacy guarantees for small $ε$, where Rényi divergence bounds inherently lead to an over-approximation. Our framework applies to arbitrary banded and non-banded matrices. Through numerical comparisons, we demonstrate the efficacy of our approach across a broad range of matrix mechanisms used in research and practice.
Privacy Amplification by Structured Subsampling for Deep Differentially Private Time Series Forecasting
Feb 04, 2025



Many forms of sensitive data, such as web traffic, mobility data, or hospital occupancy, are inherently sequential. The standard method for training machine learning models while ensuring privacy for units of sensitive information, such as individual hospital visits, is differentially private stochastic gradient descent (DP-SGD). However, we observe in this work that the formal guarantees of DP-SGD are incompatible with timeseries-specific tasks like forecasting, since they rely on the privacy amplification attained by training on small, unstructured batches sampled from an unstructured dataset. In contrast, batches for forecasting are generated by (1) sampling sequentially structured time series from a dataset, (2) sampling contiguous subsequences from these series, and (3) partitioning them into context and ground-truth forecast windows. We theoretically analyze the privacy amplification attained by this structured subsampling to enable the training of forecasting models with sound and tight event- and user-level privacy guarantees. Towards more private models, we additionally prove how data augmentation amplifies privacy in self-supervised training of sequence models. Our empirical evaluation demonstrates that amplification by structured subsampling enables the training of forecasting models with strong formal privacy guarantees.
Group Privacy Amplification and Unified Amplification by Subsampling for Rényi Differential Privacy
Mar 07, 2024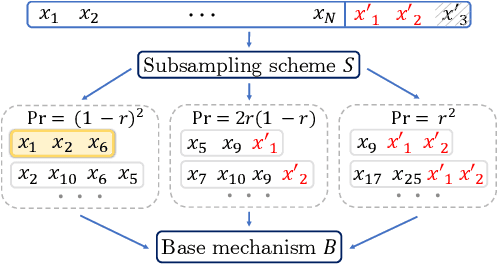

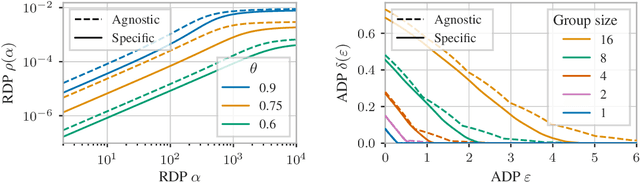
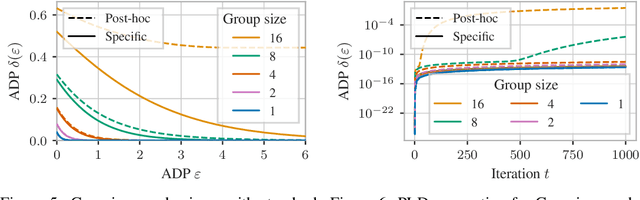
Differential privacy (DP) has various desirable properties, such as robustness to post-processing, group privacy, and amplification by subsampling, which can be derived independently of each other. Our goal is to determine whether stronger privacy guarantees can be obtained by considering multiple of these properties jointly. To this end, we focus on the combination of group privacy and amplification by subsampling. To provide guarantees that are amenable to machine learning algorithms, we conduct our analysis in the framework of R\'enyi-DP, which has more favorable composition properties than $(\epsilon,\delta)$-DP. As part of this analysis, we develop a unified framework for deriving amplification by subsampling guarantees for R\'enyi-DP, which represents the first such framework for a privacy accounting method and is of independent interest. We find that it not only lets us improve upon and generalize existing amplification results for R\'enyi-DP, but also derive provably tight group privacy amplification guarantees stronger than existing principles. These results establish the joint study of different DP properties as a promising research direction.
(Provable) Adversarial Robustness for Group Equivariant Tasks: Graphs, Point Clouds, Molecules, and More
Dec 05, 2023


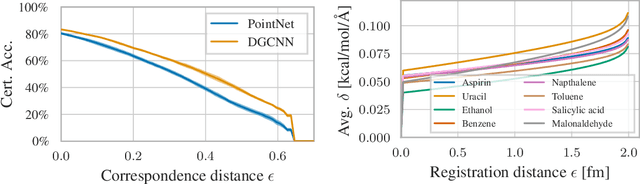
A machine learning model is traditionally considered robust if its prediction remains (almost) constant under input perturbations with small norm. However, real-world tasks like molecular property prediction or point cloud segmentation have inherent equivariances, such as rotation or permutation equivariance. In such tasks, even perturbations with large norm do not necessarily change an input's semantic content. Furthermore, there are perturbations for which a model's prediction explicitly needs to change. For the first time, we propose a sound notion of adversarial robustness that accounts for task equivariance. We then demonstrate that provable robustness can be achieved by (1) choosing a model that matches the task's equivariances (2) certifying traditional adversarial robustness. Certification methods are, however, unavailable for many models, such as those with continuous equivariances. We close this gap by developing the framework of equivariance-preserving randomized smoothing, which enables architecture-agnostic certification. We additionally derive the first architecture-specific graph edit distance certificates, i.e. sound robustness guarantees for isomorphism equivariant tasks like node classification. Overall, a sound notion of robustness is an important prerequisite for future work at the intersection of robust and geometric machine learning.
Hierarchical Randomized Smoothing
Oct 24, 2023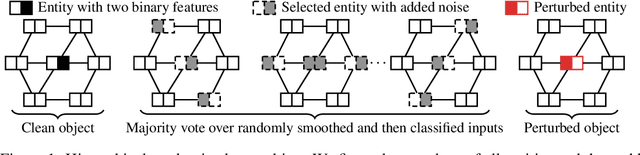
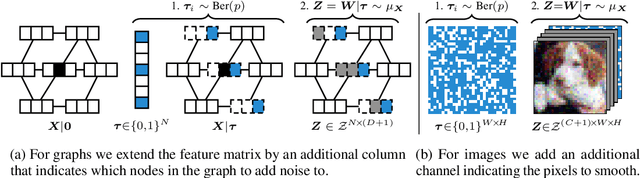
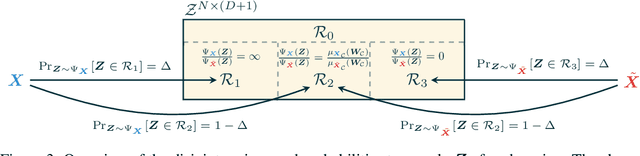
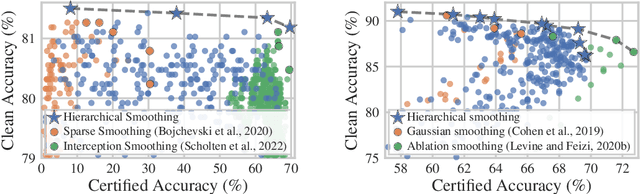
Real-world data is complex and often consists of objects that can be decomposed into multiple entities (e.g. images into pixels, graphs into interconnected nodes). Randomized smoothing is a powerful framework for making models provably robust against small changes to their inputs - by guaranteeing robustness of the majority vote when randomly adding noise before classification. Yet, certifying robustness on such complex data via randomized smoothing is challenging when adversaries do not arbitrarily perturb entire objects (e.g. images) but only a subset of their entities (e.g. pixels). As a solution, we introduce hierarchical randomized smoothing: We partially smooth objects by adding random noise only on a randomly selected subset of their entities. By adding noise in a more targeted manner than existing methods we obtain stronger robustness guarantees while maintaining high accuracy. We initialize hierarchical smoothing using different noising distributions, yielding novel robustness certificates for discrete and continuous domains. We experimentally demonstrate the importance of hierarchical smoothing in image and node classification, where it yields superior robustness-accuracy trade-offs. Overall, hierarchical smoothing is an important contribution towards models that are both - certifiably robust to perturbations and accurate.
Collective Robustness Certificates: Exploiting Interdependence in Graph Neural Networks
Feb 06, 2023



In tasks like node classification, image segmentation, and named-entity recognition we have a classifier that simultaneously outputs multiple predictions (a vector of labels) based on a single input, i.e. a single graph, image, or document respectively. Existing adversarial robustness certificates consider each prediction independently and are thus overly pessimistic for such tasks. They implicitly assume that an adversary can use different perturbed inputs to attack different predictions, ignoring the fact that we have a single shared input. We propose the first collective robustness certificate which computes the number of predictions that are simultaneously guaranteed to remain stable under perturbation, i.e. cannot be attacked. We focus on Graph Neural Networks and leverage their locality property - perturbations only affect the predictions in a close neighborhood - to fuse multiple single-node certificates into a drastically stronger collective certificate. For example, on the Citeseer dataset our collective certificate for node classification increases the average number of certifiable feature perturbations from $7$ to $351$.
Randomized Message-Interception Smoothing: Gray-box Certificates for Graph Neural Networks
Jan 05, 2023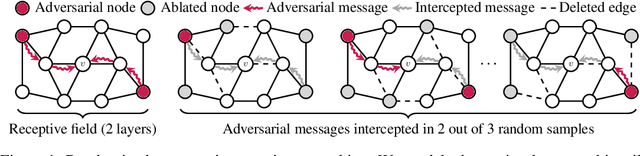
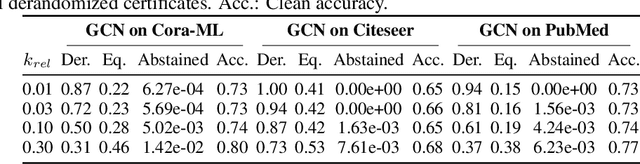
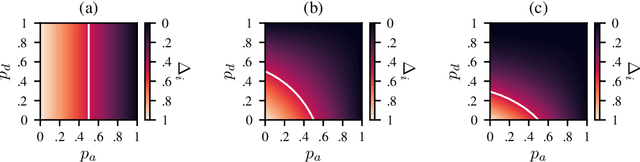
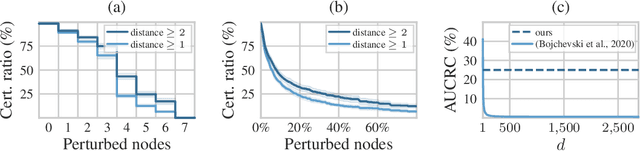
Randomized smoothing is one of the most promising frameworks for certifying the adversarial robustness of machine learning models, including Graph Neural Networks (GNNs). Yet, existing randomized smoothing certificates for GNNs are overly pessimistic since they treat the model as a black box, ignoring the underlying architecture. To remedy this, we propose novel gray-box certificates that exploit the message-passing principle of GNNs: We randomly intercept messages and carefully analyze the probability that messages from adversarially controlled nodes reach their target nodes. Compared to existing certificates, we certify robustness to much stronger adversaries that control entire nodes in the graph and can arbitrarily manipulate node features. Our certificates provide stronger guarantees for attacks at larger distances, as messages from farther-away nodes are more likely to get intercepted. We demonstrate the effectiveness of our method on various models and datasets. Since our gray-box certificates consider the underlying graph structure, we can significantly improve certifiable robustness by applying graph sparsification.