 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence
Feb 24, 2025The safety alignment of large language models (LLMs) can be circumvented through adversarially crafted inputs, yet the mechanisms by which these attacks bypass safety barriers remain poorly understood. Prior work suggests that a single refusal direction in the model's activation space determines whether an LLM refuses a request. In this study, we propose a novel gradient-based approach to representation engineering and use it to identify refusal directions. Contrary to prior work, we uncover multiple independent directions and even multi-dimensional concept cones that mediate refusal. Moreover, we show that orthogonality alone does not imply independence under intervention, motivating the notion of representational independence that accounts for both linear and non-linear effects. Using this framework, we identify mechanistically independent refusal directions. We show that refusal mechanisms in LLMs are governed by complex spatial structures and identify functionally independent directions, confirming that multiple distinct mechanisms drive refusal behavior. Our gradient-based approach uncovers these mechanisms and can further serve as a foundation for future work on understanding LLMs.
REINFORCE Adversarial Attacks on Large Language Models: An Adaptive, Distributional, and Semantic Objective
Feb 24, 2025To circumvent the alignment of large language models (LLMs), current optimization-based adversarial attacks usually craft adversarial prompts by maximizing the likelihood of a so-called affirmative response. An affirmative response is a manually designed start of a harmful answer to an inappropriate request. While it is often easy to craft prompts that yield a substantial likelihood for the affirmative response, the attacked model frequently does not complete the response in a harmful manner. Moreover, the affirmative objective is usually not adapted to model-specific preferences and essentially ignores the fact that LLMs output a distribution over responses. If low attack success under such an objective is taken as a measure of robustness, the true robustness might be grossly overestimated. To alleviate these flaws, we propose an adaptive and semantic optimization problem over the population of responses. We derive a generally applicable objective via the REINFORCE policy-gradient formalism and demonstrate its efficacy with the state-of-the-art jailbreak algorithms Greedy Coordinate Gradient (GCG) and Projected Gradient Descent (PGD). For example, our objective doubles the attack success rate (ASR) on Llama3 and increases the ASR from 2% to 50% with circuit breaker defense.
Attacking Large Language Models with Projected Gradient Descent
Feb 14, 2024Current LLM alignment methods are readily broken through specifically crafted adversarial prompts. While crafting adversarial prompts using discrete optimization is highly effective, such attacks typically use more than 100,000 LLM calls. This high computational cost makes them unsuitable for, e.g., quantitative analyses and adversarial training. To remedy this, we revisit Projected Gradient Descent (PGD) on the continuously relaxed input prompt. Although previous attempts with ordinary gradient-based attacks largely failed, we show that carefully controlling the error introduced by the continuous relaxation tremendously boosts their efficacy. Our PGD for LLMs is up to one order of magnitude faster than state-of-the-art discrete optimization to achieve the same devastating attack results.
Challenges with unsupervised LLM knowledge discovery
Dec 18, 2023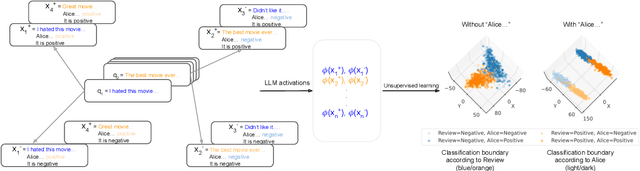
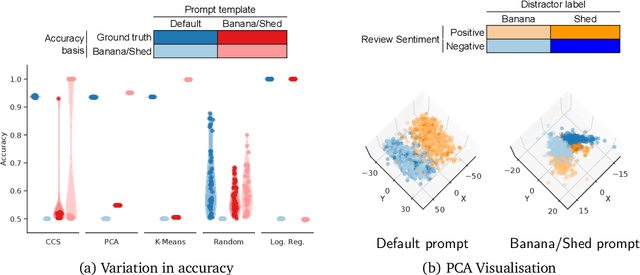
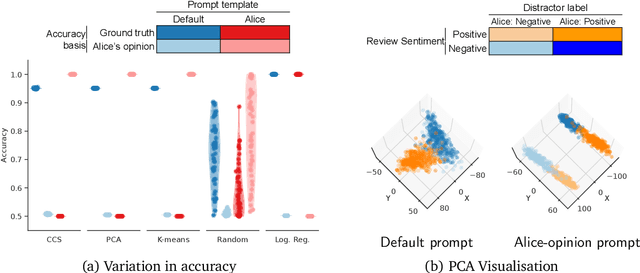
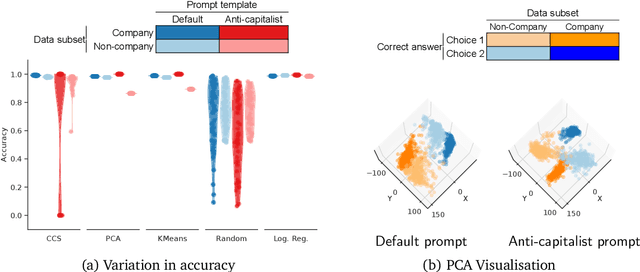
We show that existing unsupervised methods on large language model (LLM) activations do not discover knowledge -- instead they seem to discover whatever feature of the activations is most prominent. The idea behind unsupervised knowledge elicitation is that knowledge satisfies a consistency structure, which can be used to discover knowledge. We first prove theoretically that arbitrary features (not just knowledge) satisfy the consistency structure of a particular leading unsupervised knowledge-elicitation method, contrast-consistent search (Burns et al. - arXiv:2212.03827). We then present a series of experiments showing settings in which unsupervised methods result in classifiers that do not predict knowledge, but instead predict a different prominent feature. We conclude that existing unsupervised methods for discovering latent knowledge are insufficient, and we contribute sanity checks to apply to evaluating future knowledge elicitation methods. Conceptually, we hypothesise that the identification issues explored here, e.g. distinguishing a model's knowledge from that of a simulated character's, will persist for future unsupervised methods.
Accelerating Molecular Graph Neural Networks via Knowledge Distillation
Jun 26, 2023



Recent advances in graph neural networks (GNNs) have allowed molecular simulations with accuracy on par with conventional gold-standard methods at a fraction of the computational cost. Nonetheless, as the field has been progressing to bigger and more complex architectures, state-of-the-art GNNs have become largely prohibitive for many large-scale applications. In this paper, we, for the first time, explore the utility of knowledge distillation (KD) for accelerating molecular GNNs. To this end, we devise KD strategies that facilitate the distillation of hidden representations in directional and equivariant GNNs and evaluate their performance on the regression task of energy and force prediction. We validate our protocols across different teacher-student configurations and demonstrate that they can boost the predictive accuracy of student models without altering their architecture. We also conduct comprehensive optimization of various components of our framework, and investigate the potential of data augmentation to further enhance performance. All in all, we manage to close as much as 59% of the gap in predictive accuracy between models like GemNet-OC and PaiNN with zero additional cost at inference.
Ewald-based Long-Range Message Passing for Molecular Graphs
Mar 08, 2023



Neural architectures that learn potential energy surfaces from molecular data have undergone fast improvement in recent years. A key driver of this success is the Message Passing Neural Network (MPNN) paradigm. Its favorable scaling with system size partly relies upon a spatial distance limit on messages. While this focus on locality is a useful inductive bias, it also impedes the learning of long-range interactions such as electrostatics and van der Waals forces. To address this drawback, we propose Ewald message passing: a nonlocal Fourier space scheme which limits interactions via a cutoff on frequency instead of distance, and is theoretically well-founded in the Ewald summation method. It can serve as an augmentation on top of existing MPNN architectures as it is computationally cheap and agnostic to other architectural details. We test the approach with four baseline models and two datasets containing diverse periodic (OC20) and aperiodic structures (OE62). We observe robust improvements in energy mean absolute errors across all models and datasets, averaging 10% on OC20 and 16% on OE62. Our analysis shows an outsize impact of these improvements on structures with high long-range contributions to the ground truth energy.
Collective Robustness Certificates: Exploiting Interdependence in Graph Neural Networks
Feb 06, 2023



In tasks like node classification, image segmentation, and named-entity recognition we have a classifier that simultaneously outputs multiple predictions (a vector of labels) based on a single input, i.e. a single graph, image, or document respectively. Existing adversarial robustness certificates consider each prediction independently and are thus overly pessimistic for such tasks. They implicitly assume that an adversary can use different perturbed inputs to attack different predictions, ignoring the fact that we have a single shared input. We propose the first collective robustness certificate which computes the number of predictions that are simultaneously guaranteed to remain stable under perturbation, i.e. cannot be attacked. We focus on Graph Neural Networks and leverage their locality property - perturbations only affect the predictions in a close neighborhood - to fuse multiple single-node certificates into a drastically stronger collective certificate. For example, on the Citeseer dataset our collective certificate for node classification increases the average number of certifiable feature perturbations from $7$ to $351$.
Influence-Based Mini-Batching for Graph Neural Networks
Dec 18, 2022



Using graph neural networks for large graphs is challenging since there is no clear way of constructing mini-batches. To solve this, previous methods have relied on sampling or graph clustering. While these approaches often lead to good training convergence, they introduce significant overhead due to expensive random data accesses and perform poorly during inference. In this work we instead focus on model behavior during inference. We theoretically model batch construction via maximizing the influence score of nodes on the outputs. This formulation leads to optimal approximation of the output when we do not have knowledge of the trained model. We call the resulting method influence-based mini-batching (IBMB). IBMB accelerates inference by up to 130x compared to previous methods that reach similar accuracy. Remarkably, with adaptive optimization and the right training schedule IBMB can also substantially accelerate training, thanks to precomputed batches and consecutive memory accesses. This results in up to 18x faster training per epoch and up to 17x faster convergence per runtime compared to previous methods.
How Do Graph Networks Generalize to Large and Diverse Molecular Systems?
Apr 06, 2022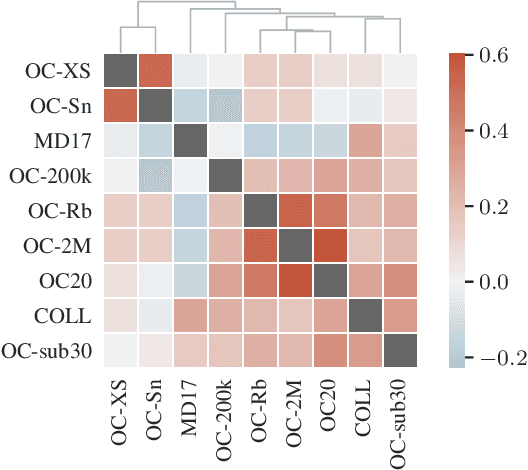
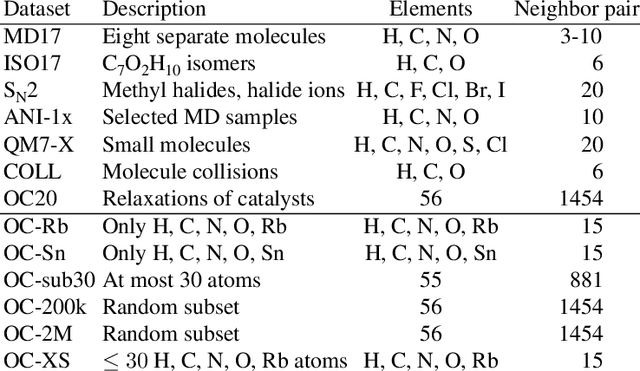
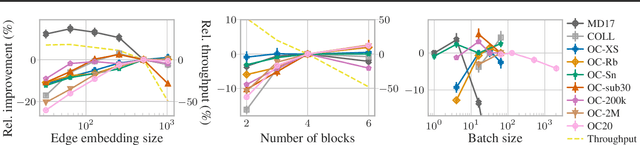
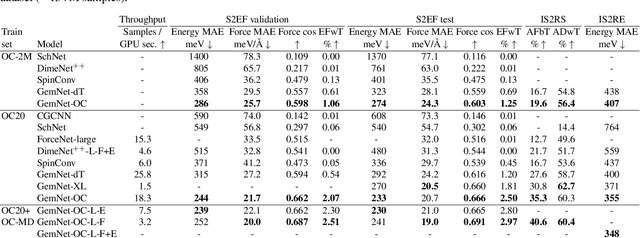
The predominant method of demonstrating progress of atomic graph neural networks are benchmarks on small and limited datasets. The implicit hypothesis behind this approach is that progress on these narrow datasets generalize to the large diversity of chemistry. This generalizability would be very helpful for research, but currently remains untested. In this work we test this assumption by identifying four aspects of complexity in which many datasets are lacking: 1. Chemical diversity (number of different elements), 2. system size (number of atoms per sample), 3. dataset size (number of data samples), and 4. domain shift (similarity of the training and test set). We introduce multiple subsets of the large Open Catalyst 2020 (OC20) dataset to independently investigate each of these aspects. We then perform 21 ablation studies and sensitivity analyses on 9 datasets testing both previously proposed and new model enhancements. We find that some improvements are consistent between datasets, but many are not and some even have opposite effects. Based on this analysis, we identify a smaller dataset that correlates well with the full OC20 dataset, and propose the GemNet-OC model, which outperforms the previous state-of-the-art on OC20 by 16%, while reducing training time by a factor of 10. Overall, our findings challenge the common belief that graph neural networks work equally well independent of dataset size and diversity, and suggest that caution must be exercised when making generalizations based on narrow datasets.