 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
Jan 08, 2026We introduce enhanced Constitutional Classifiers that deliver production-grade jailbreak robustness with dramatically reduced computational costs and refusal rates compared to previous-generation defenses. Our system combines several key insights. First, we develop exchange classifiers that evaluate model responses in their full conversational context, which addresses vulnerabilities in last-generation systems that examine outputs in isolation. Second, we implement a two-stage classifier cascade where lightweight classifiers screen all traffic and escalate only suspicious exchanges to more expensive classifiers. Third, we train efficient linear probe classifiers and ensemble them with external classifiers to simultaneously improve robustness and reduce computational costs. Together, these techniques yield a production-grade system achieving a 40x computational cost reduction compared to our baseline exchange classifier, while maintaining a 0.05% refusal rate on production traffic. Through extensive red-teaming comprising over 1,700 hours, we demonstrate strong protection against universal jailbreaks -- no attack on this system successfully elicited responses to all eight target queries comparable in detail to an undefended model. Our work establishes Constitutional Classifiers as practical and efficient safeguards for large language models.
Human-AI Complementarity: A Goal for Amplified Oversight
Oct 30, 2025Human feedback is critical for aligning AI systems to human values. As AI capabilities improve and AI is used to tackle more challenging tasks, verifying quality and safety becomes increasingly challenging. This paper explores how we can leverage AI to improve the quality of human oversight. We focus on an important safety problem that is already challenging for humans: fact-verification of AI outputs. We find that combining AI ratings and human ratings based on AI rater confidence is better than relying on either alone. Giving humans an AI fact-verification assistant further improves their accuracy, but the type of assistance matters. Displaying AI explanation, confidence, and labels leads to over-reliance, but just showing search results and evidence fosters more appropriate trust. These results have implications for Amplified Oversight -- the challenge of combining humans and AI to supervise AI systems even as they surpass human expert performance.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Challenges with unsupervised LLM knowledge discovery
Dec 18, 2023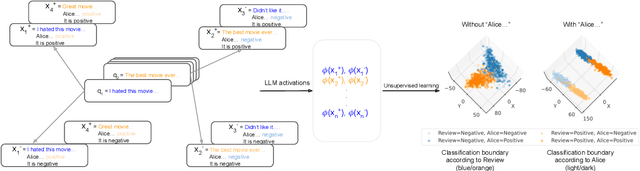
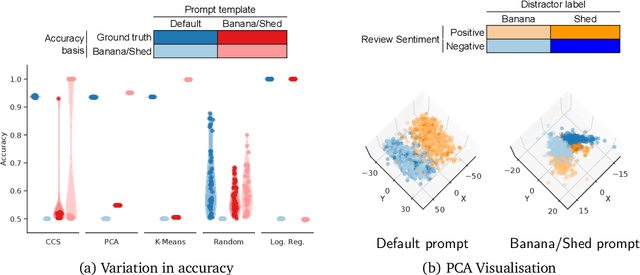
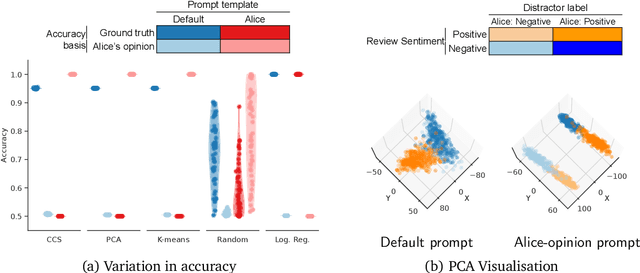
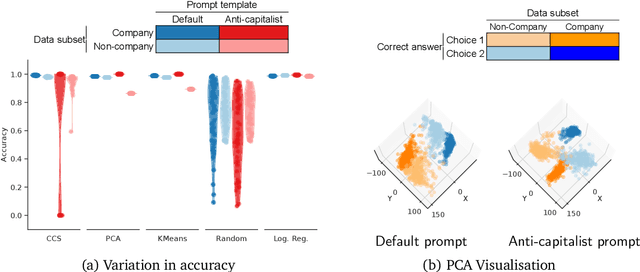
We show that existing unsupervised methods on large language model (LLM) activations do not discover knowledge -- instead they seem to discover whatever feature of the activations is most prominent. The idea behind unsupervised knowledge elicitation is that knowledge satisfies a consistency structure, which can be used to discover knowledge. We first prove theoretically that arbitrary features (not just knowledge) satisfy the consistency structure of a particular leading unsupervised knowledge-elicitation method, contrast-consistent search (Burns et al. - arXiv:2212.03827). We then present a series of experiments showing settings in which unsupervised methods result in classifiers that do not predict knowledge, but instead predict a different prominent feature. We conclude that existing unsupervised methods for discovering latent knowledge are insufficient, and we contribute sanity checks to apply to evaluating future knowledge elicitation methods. Conceptually, we hypothesise that the identification issues explored here, e.g. distinguishing a model's knowledge from that of a simulated character's, will persist for future unsupervised methods.
The Hydra Effect: Emergent Self-repair in Language Model Computations
Jul 28, 2023We investigate the internal structure of language model computations using causal analysis and demonstrate two motifs: (1) a form of adaptive computation where ablations of one attention layer of a language model cause another layer to compensate (which we term the Hydra effect) and (2) a counterbalancing function of late MLP layers that act to downregulate the maximum-likelihood token. Our ablation studies demonstrate that language model layers are typically relatively loosely coupled (ablations to one layer only affect a small number of downstream layers). Surprisingly, these effects occur even in language models trained without any form of dropout. We analyse these effects in the context of factual recall and consider their implications for circuit-level attribution in language models.
Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla
Jul 24, 2023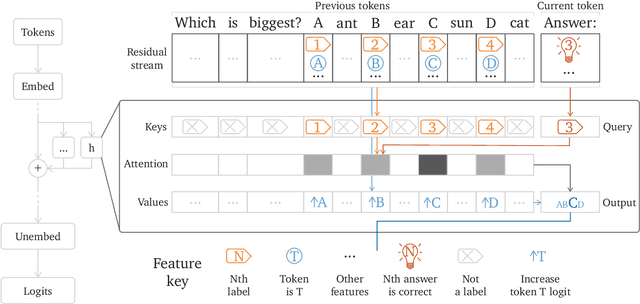
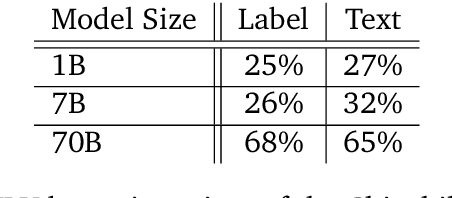
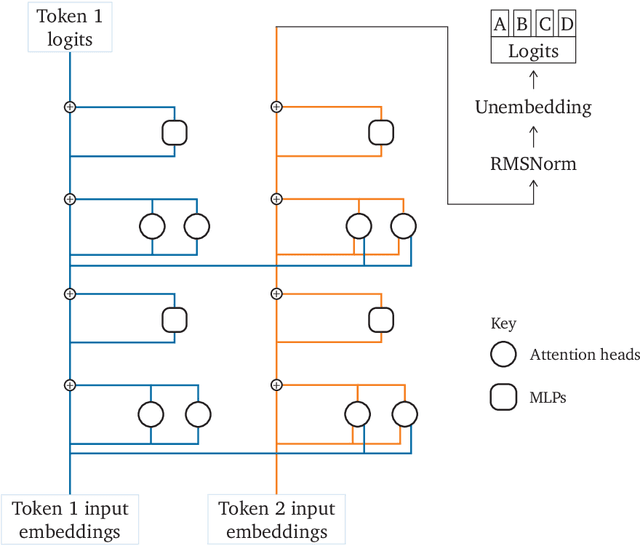

\emph{Circuit analysis} is a promising technique for understanding the internal mechanisms of language models. However, existing analyses are done in small models far from the state of the art. To address this, we present a case study of circuit analysis in the 70B Chinchilla model, aiming to test the scalability of circuit analysis. In particular, we study multiple-choice question answering, and investigate Chinchilla's capability to identify the correct answer \emph{label} given knowledge of the correct answer \emph{text}. We find that the existing techniques of logit attribution, attention pattern visualization, and activation patching naturally scale to Chinchilla, allowing us to identify and categorize a small set of `output nodes' (attention heads and MLPs). We further study the `correct letter' category of attention heads aiming to understand the semantics of their features, with mixed results. For normal multiple-choice question answers, we significantly compress the query, key and value subspaces of the head without loss of performance when operating on the answer labels for multiple-choice questions, and we show that the query and key subspaces represent an `Nth item in an enumeration' feature to at least some extent. However, when we attempt to use this explanation to understand the heads' behaviour on a more general distribution including randomized answer labels, we find that it is only a partial explanation, suggesting there is more to learn about the operation of `correct letter' heads on multiple choice question answering.
Tracr: Compiled Transformers as a Laboratory for Interpretability
Jan 12, 2023Interpretability research aims to build tools for understanding machine learning (ML) models. However, such tools are inherently hard to evaluate because we do not have ground truth information about how ML models actually work. In this work, we propose to build transformer models manually as a testbed for interpretability research. We introduce Tracr, a "compiler" for translating human-readable programs into weights of a transformer model. Tracr takes code written in RASP, a domain-specific language (Weiss et al. 2021), and translates it into weights for a standard, decoder-only, GPT-like transformer architecture. We use Tracr to create a range of ground truth transformers that implement programs including computing token frequencies, sorting, and Dyck-n parenthesis checking, among others. To enable the broader research community to explore and use compiled models, we provide an open-source implementation of Tracr at https://github.com/deepmind/tracr.
Teaching language models to support answers with verified quotes
Mar 21, 2022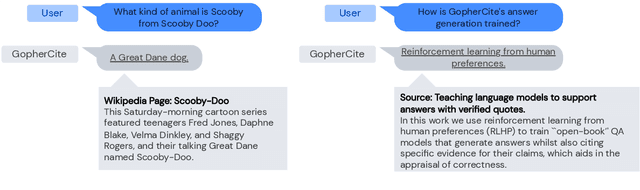
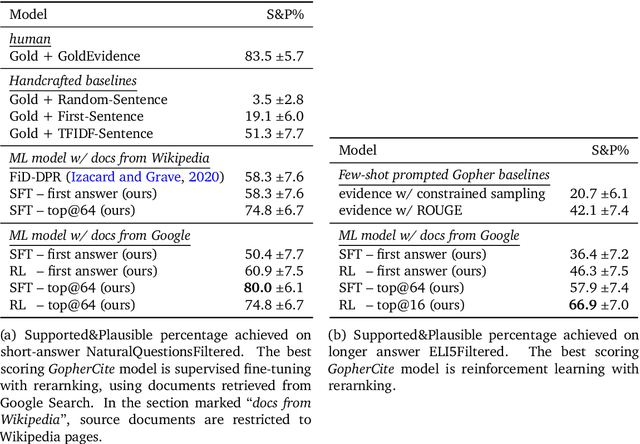


Recent large language models often answer factual questions correctly. But users can't trust any given claim a model makes without fact-checking, because language models can hallucinate convincing nonsense. In this work we use reinforcement learning from human preferences (RLHP) to train "open-book" QA models that generate answers whilst also citing specific evidence for their claims, which aids in the appraisal of correctness. Supporting evidence is drawn from multiple documents found via a search engine, or from a single user-provided document. Our 280 billion parameter model, GopherCite, is able to produce answers with high quality supporting evidence and abstain from answering when unsure. We measure the performance of GopherCite by conducting human evaluation of answers to questions in a subset of the NaturalQuestions and ELI5 datasets. The model's response is found to be high-quality 80\% of the time on this Natural Questions subset, and 67\% of the time on the ELI5 subset. Abstaining from the third of questions for which it is most unsure improves performance to 90\% and 80\% respectively, approaching human baselines. However, analysis on the adversarial TruthfulQA dataset shows why citation is only one part of an overall strategy for safety and trustworthiness: not all claims supported by evidence are true.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.