 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs your algorithm unlearning or untraining?
Apr 09, 2026As models are getting larger and are trained on increasing amounts of data, there has been an explosion of interest into how we can ``delete'' specific data points or behaviours from a trained model, after the fact. This goal has been referred to as ``machine unlearning''. In this note, we argue that the term ``unlearning'' has been overloaded, with different research efforts spanning two distinct problem formulations, but without that distinction having been observed or acknowledged in the literature. This causes various issues, including ambiguity around when an algorithm is expected to work, use of inappropriate metrics and baselines when comparing different algorithms to one another, difficulty in interpreting results, as well as missed opportunities for pursuing critical research directions. In this note, we address this issue by establishing a fundamental distinction between two notions that we identify as \unlearning and \untraining, illustrated in Figure 1. In short, \untraining aims to reverse the effect of having trained on a given forget set, i.e. to remove the influence that that specific forget set examples had on the model during training. On the other hand, the goal of \unlearning is not just to remove the influence of those given examples, but to use those examples for the purpose of more broadly removing the entire underlying distribution from which those examples were sampled (e.g. the concept or behaviour that those examples represent). We discuss technical definitions of these problems and map problem settings studied in the literature to each. We hope to initiate discussions on disambiguating technical definitions and identify a set of overlooked research questions, as we believe that this a key missing step for accelerating progress in the field of ``unlearning''.
Recontextualization Mitigates Specification Gaming without Modifying the Specification
Dec 22, 2025Developers often struggle to specify correct training labels and rewards. Perhaps they don't need to. We propose recontextualization, which reduces how often language models "game" training signals, performing misbehaviors those signals mistakenly reinforce. We show recontextualization prevents models from learning to 1) prioritize evaluation metrics over chat response quality; 2) special-case code to pass incorrect tests; 3) lie to users; and 4) become sycophantic. Our method works by generating completions from prompts discouraging misbehavior and then recontextualizing them as though they were in response to prompts permitting misbehavior. Recontextualization trains language models to resist misbehavior even when instructions permit it. This mitigates the reinforcement of misbehavior from misspecified training signals, reducing specification gaming without improving the supervision signal.
Consistency Training Helps Stop Sycophancy and Jailbreaks
Oct 31, 2025An LLM's factuality and refusal training can be compromised by simple changes to a prompt. Models often adopt user beliefs (sycophancy) or satisfy inappropriate requests which are wrapped within special text (jailbreaking). We explore \emph{consistency training}, a self-supervised paradigm that teaches a model to be invariant to certain irrelevant cues in the prompt. Instead of teaching the model what exact response to give on a particular prompt, we aim to teach the model to behave identically across prompt data augmentations (like adding leading questions or jailbreak text). We try enforcing this invariance in two ways: over the model's external outputs (\emph{Bias-augmented Consistency Training} (BCT) from Chua et al. [2025]) and over its internal activations (\emph{Activation Consistency Training} (ACT), a method we introduce). Both methods reduce Gemini 2.5 Flash's susceptibility to irrelevant cues. Because consistency training uses responses from the model itself as training data, it avoids issues that arise from stale training data, such as degrading model capabilities or enforcing outdated response guidelines. While BCT and ACT reduce sycophancy equally well, BCT does better at jailbreak reduction. We think that BCT can simplify training pipelines by removing reliance on static datasets. We argue that some alignment problems are better viewed not in terms of optimal responses, but rather as consistency issues.
Distillation Robustifies Unlearning
Jun 06, 2025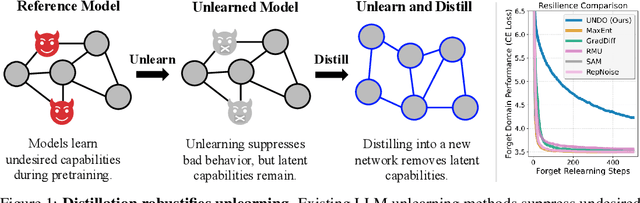

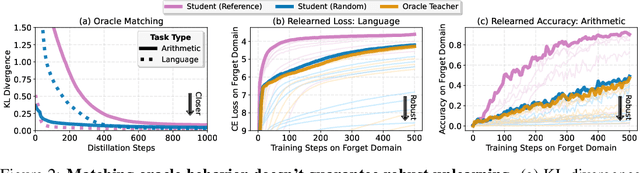
Current LLM unlearning methods are not robust: they can be reverted easily with a few steps of finetuning. This is true even for the idealized unlearning method of training to imitate an oracle model that was never exposed to unwanted information, suggesting that output-based finetuning is insufficient to achieve robust unlearning. In a similar vein, we find that training a randomly initialized student to imitate an unlearned model transfers desired behaviors while leaving undesired capabilities behind. In other words, distillation robustifies unlearning. Building on this insight, we propose Unlearn-Noise-Distill-on-Outputs (UNDO), a scalable method that distills an unlearned model into a partially noised copy of itself. UNDO introduces a tunable tradeoff between compute cost and robustness, establishing a new Pareto frontier on synthetic language and arithmetic tasks. At its strongest setting, UNDO matches the robustness of a model retrained from scratch with perfect data filtering while using only 60-80% of the compute and requiring only 0.01% of the pretraining data to be labeled. We also show that UNDO robustifies unlearning on the more realistic Weapons of Mass Destruction Proxy (WMDP) benchmark. Since distillation is widely used in practice, incorporating an unlearning step beforehand offers a convenient path to robust capability removal.
An Approach to Technical AGI Safety and Security
Apr 02, 2025Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks. Of these, we focus on technical approaches to misuse and misalignment. For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations. To address misalignment, we outline two lines of defense. First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model. Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations. Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
Gradient Routing: Masking Gradients to Localize Computation in Neural Networks
Oct 06, 2024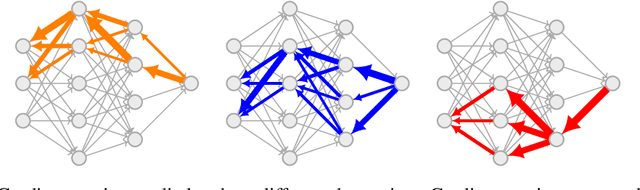

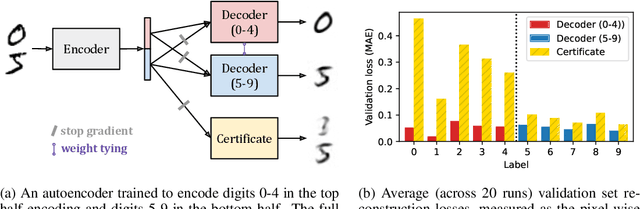

Neural networks are trained primarily based on their inputs and outputs, without regard for their internal mechanisms. These neglected mechanisms determine properties that are critical for safety, like (i) transparency; (ii) the absence of sensitive information or harmful capabilities; and (iii) reliable generalization of goals beyond the training distribution. To address this shortcoming, we introduce gradient routing, a training method that isolates capabilities to specific subregions of a neural network. Gradient routing applies data-dependent, weighted masks to gradients during backpropagation. These masks are supplied by the user in order to configure which parameters are updated by which data points. We show that gradient routing can be used to (1) learn representations which are partitioned in an interpretable way; (2) enable robust unlearning via ablation of a pre-specified network subregion; and (3) achieve scalable oversight of a reinforcement learner by localizing modules responsible for different behaviors. Throughout, we find that gradient routing localizes capabilities even when applied to a limited, ad-hoc subset of the data. We conclude that the approach holds promise for challenging, real-world applications where quality data are scarce.
Steering Llama 2 via Contrastive Activation Addition
Dec 09, 2023
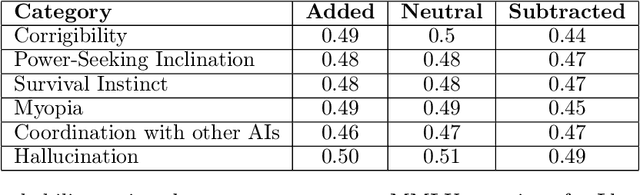

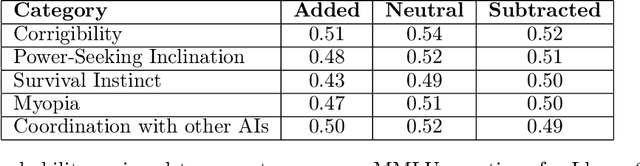
We introduce Contrastive Activation Addition (CAA), an innovative method for steering language models by modifying activations during their forward passes. CAA computes ``steering vectors'' by averaging the difference in residual stream activations between pairs of positive and negative examples of a particular behavior such as factual versus hallucinatory responses. During inference, these steering vectors are added at all token positions after the user's prompt with either a positive or negative coefficient, allowing precise control over the degree of the targeted behavior. We evaluate CAA's effectiveness on Llama 2 Chat using both multiple-choice behavioral question datasets and open-ended generation tasks. We demonstrate that CAA significantly alters model behavior, outperforms traditional methods like finetuning and few-shot prompting, and minimally reduces capabilities. Moreover, by employing various activation space interpretation methods, we gain deeper insights into CAA's mechanisms. CAA both accurately steers model outputs and also sheds light on how high-level concepts are represented in Large Language Models (LLMs).
Understanding and Controlling a Maze-Solving Policy Network
Oct 12, 2023To understand the goals and goal representations of AI systems, we carefully study a pretrained reinforcement learning policy that solves mazes by navigating to a range of target squares. We find this network pursues multiple context-dependent goals, and we further identify circuits within the network that correspond to one of these goals. In particular, we identified eleven channels that track the location of the goal. By modifying these channels, either with hand-designed interventions or by combining forward passes, we can partially control the policy. We show that this network contains redundant, distributed, and retargetable goal representations, shedding light on the nature of goal-direction in trained policy networks.
Activation Addition: Steering Language Models Without Optimization
Sep 01, 2023Reliably controlling the behavior of large language models is a pressing open problem. Existing methods include supervised finetuning, reinforcement learning from human feedback, prompt engineering, and guided decoding. We instead investigate activation engineering: modifying activations at inference time to predictably alter model behavior. In particular, we bias the forward pass with an added 'steering vector' implicitly specified through natural language. Unlike past work which learned these steering vectors, our Activation Addition (ActAdd) method computes them by taking the activation differences that result from pairs of prompts. We demonstrate ActAdd on GPT-2 on OpenWebText and ConceptNet. Our inference-time approach yields control over high-level properties of output and preserves off-target model performance. It involves far less compute and implementation effort than finetuning, allows users to provide natural language specifications, and its overhead scales naturally with model size.
Parametrically Retargetable Decision-Makers Tend To Seek Power
Jun 27, 2022
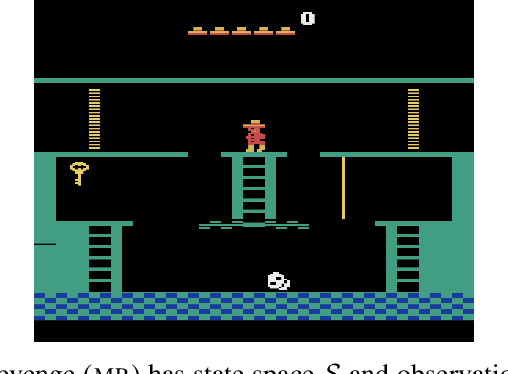

If capable AI agents are generally incentivized to seek power in service of the objectives we specify for them, then these systems will pose enormous risks, in addition to enormous benefits. In fully observable environments, most reward functions have an optimal policy which seeks power by keeping options open and staying alive. However, the real world is neither fully observable, nor will agents be perfectly optimal. We consider a range of models of AI decision-making, from optimal, to random, to choices informed by learning and interacting with an environment. We discover that many decision-making functions are retargetable, and that retargetability is sufficient to cause power-seeking tendencies. Our functional criterion is simple and broad. We show that a range of qualitatively dissimilar decision-making procedures incentivize agents to seek power. We demonstrate the flexibility of our results by reasoning about learned policy incentives in Montezuma's Revenge. These results suggest a safety risk: Eventually, highly retargetable training procedures may train real-world agents which seek power over humans.