 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Contamination Means Benchmarks Test Shallow Generalization
Feb 12, 2026If LLM training data is polluted with benchmark test data, then benchmark performance gives biased estimates of out-of-distribution (OOD) generalization. Typical decontamination filters use n-gram matching which fail to detect semantic duplicates: sentences with equivalent (or near-equivalent) content that are not close in string space. We study this soft contamination of training data by semantic duplicates. Among other experiments, we embed the Olmo3 training corpus and find that: 1) contamination remains widespread, e.g. we find semantic duplicates for 78% of CodeForces and exact duplicates for 50% of ZebraLogic problems; 2) including semantic duplicates of benchmark data in training does improve benchmark performance; and 3) when finetuning on duplicates of benchmark datapoints, performance also improves on truly-held-out datapoints from the same benchmark. We argue that recent benchmark gains are thus confounded: the prevalence of soft contamination means gains reflect both genuine capability improvements and the accumulation of test data and effective test data in growing training corpora.
Questionable practices in machine learning
Jul 17, 2024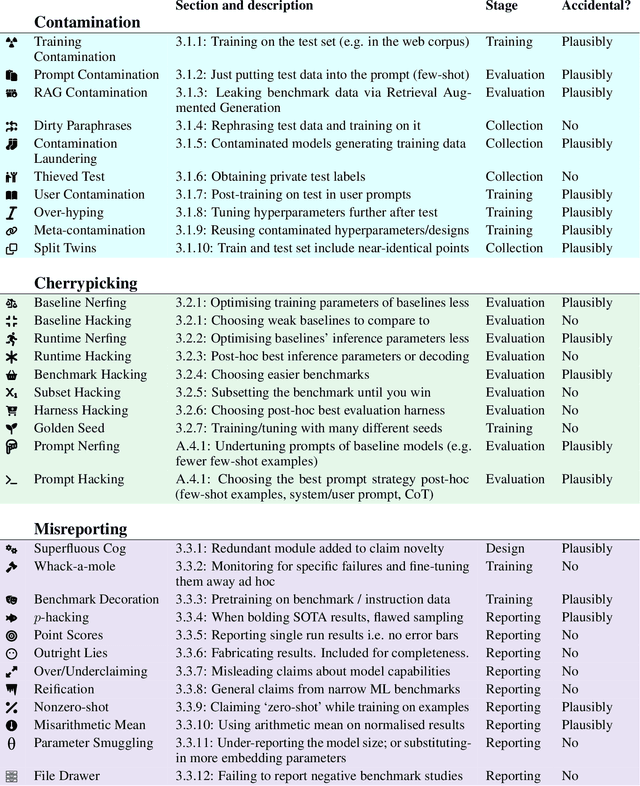
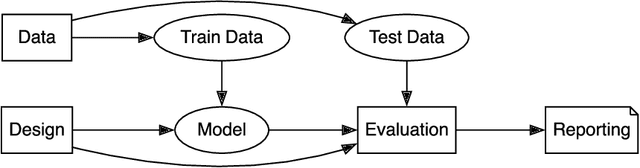

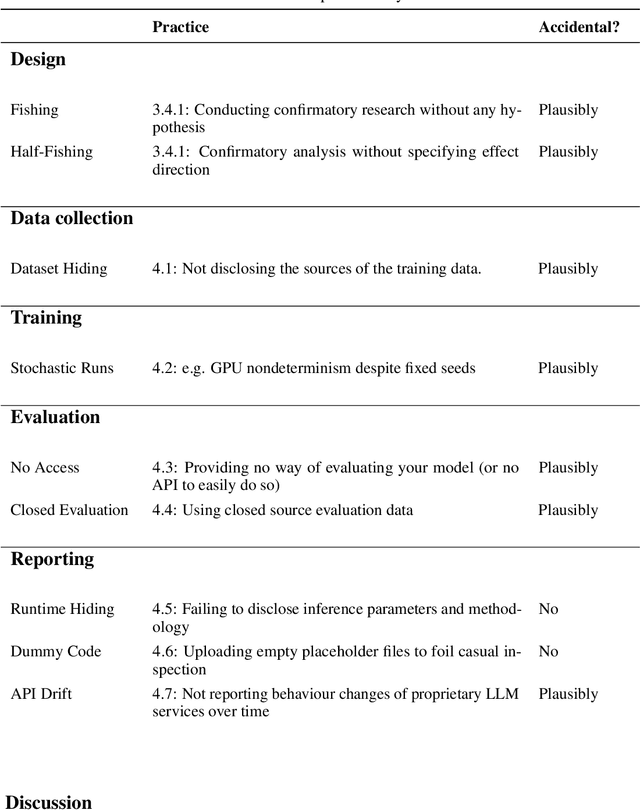
Evaluating modern ML models is hard. The strong incentive for researchers and companies to report a state-of-the-art result on some metric often leads to questionable research practices (QRPs): bad practices which fall short of outright research fraud. We describe 43 such practices which can undermine reported results, giving examples where possible. Our list emphasises the evaluation of large language models (LLMs) on public benchmarks. We also discuss "irreproducible research practices", i.e. decisions that make it difficult or impossible for other researchers to reproduce, build on or audit previous research.
Ten Hard Problems in Artificial Intelligence We Must Get Right
Feb 06, 2024


We explore the AI2050 "hard problems" that block the promise of AI and cause AI risks: (1) developing general capabilities of the systems; (2) assuring the performance of AI systems and their training processes; (3) aligning system goals with human goals; (4) enabling great applications of AI in real life; (5) addressing economic disruptions; (6) ensuring the participation of all; (7) at the same time ensuring socially responsible deployment; (8) addressing any geopolitical disruptions that AI causes; (9) promoting sound governance of the technology; and (10) managing the philosophical disruptions for humans living in the age of AI. For each problem, we outline the area, identify significant recent work, and suggest ways forward. [Note: this paper reviews literature through January 2023.]
Activation Addition: Steering Language Models Without Optimization
Sep 01, 2023Reliably controlling the behavior of large language models is a pressing open problem. Existing methods include supervised finetuning, reinforcement learning from human feedback, prompt engineering, and guided decoding. We instead investigate activation engineering: modifying activations at inference time to predictably alter model behavior. In particular, we bias the forward pass with an added 'steering vector' implicitly specified through natural language. Unlike past work which learned these steering vectors, our Activation Addition (ActAdd) method computes them by taking the activation differences that result from pairs of prompts. We demonstrate ActAdd on GPT-2 on OpenWebText and ConceptNet. Our inference-time approach yields control over high-level properties of output and preserves off-target model performance. It involves far less compute and implementation effort than finetuning, allows users to provide natural language specifications, and its overhead scales naturally with model size.
Massively Parallel Reweighted Wake-Sleep
May 18, 2023



Reweighted wake-sleep (RWS) is a machine learning method for performing Bayesian inference in a very general class of models. RWS draws $K$ samples from an underlying approximate posterior, then uses importance weighting to provide a better estimate of the true posterior. RWS then updates its approximate posterior towards the importance-weighted estimate of the true posterior. However, recent work [Chattergee and Diaconis, 2018] indicates that the number of samples required for effective importance weighting is exponential in the number of latent variables. Attaining such a large number of importance samples is intractable in all but the smallest models. Here, we develop massively parallel RWS, which circumvents this issue by drawing $K$ samples of all $n$ latent variables, and individually reasoning about all $K^n$ possible combinations of samples. While reasoning about $K^n$ combinations might seem intractable, the required computations can be performed in polynomial time by exploiting conditional independencies in the generative model. We show considerable improvements over standard "global" RWS, which draws $K$ samples from the full joint.
Decision trees compensate for model misspecification
Feb 08, 2023



The best-performing models in ML are not interpretable. If we can explain why they outperform, we may be able to replicate these mechanisms and obtain both interpretability and performance. One example are decision trees and their descendent gradient boosting machines (GBMs). These perform well in the presence of complex interactions, with tree depth governing the order of interactions. However, interactions cannot fully account for the depth of trees found in practice. We confirm 5 alternative hypotheses about the role of tree depth in performance in the absence of true interactions, and present results from experiments on a battery of datasets. Part of the success of tree models is due to their robustness to various forms of mis-specification. We present two methods for robust generalized linear models (GLMs) addressing the composite and mixed response scenarios.
Legally grounded fairness objectives
Sep 24, 2020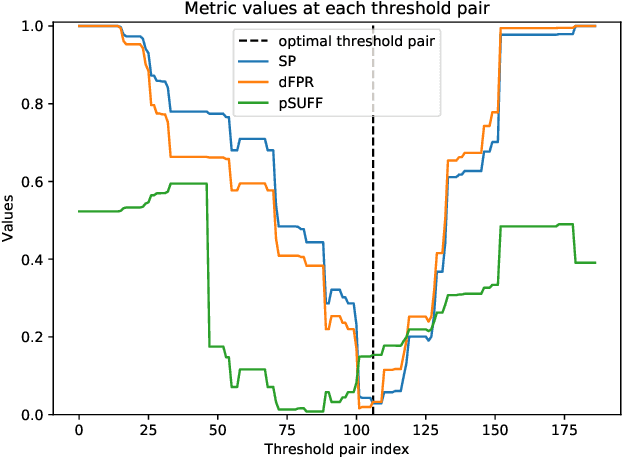
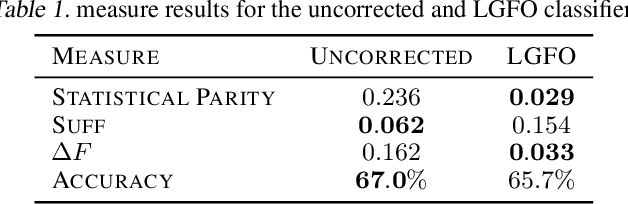
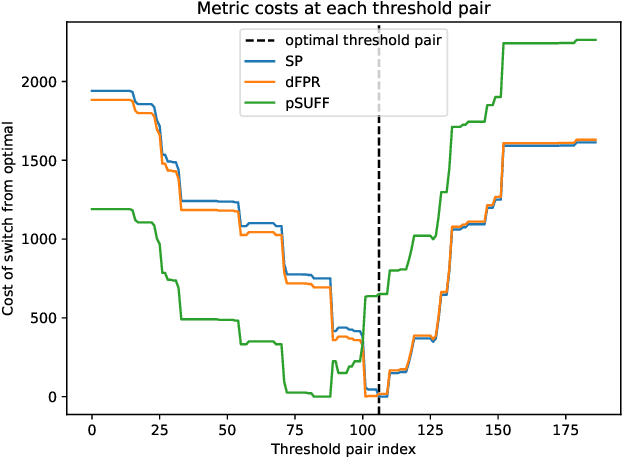
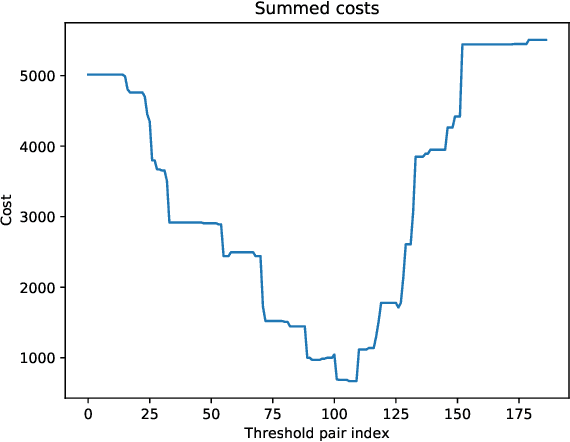
Recent work has identified a number of formally incompatible operational measures for the unfairness of a machine learning (ML) system. As these measures all capture intuitively desirable aspects of a fair system, choosing "the one true" measure is not possible, and instead a reasonable approach is to minimize a weighted combination of measures. However, this simply raises the question of how to choose the weights. Here, we formulate Legally Grounded Fairness Objectives (LGFO), which uses signals from the legal system to non-arbitrarily measure the social cost of a specific degree of unfairness. The LGFO is the expected damages under a putative lawsuit that might be awarded to those who were wrongly classified, in the sense that the ML system made a decision different to that which would have be made under the court's preferred measure. Notably, the two quantities necessary to compute the LGFO, the court's preferences about fairness measures, and the expected damages, are unknown but well-defined, and can be estimated by legal advice. Further, as the damages awarded by the legal system are designed to measure and compensate for the harm caused to an individual by an unfair classification, the LGFO aligns closely with society's estimate of the social cost.
On the robustness of effectiveness estimation of nonpharmaceutical interventions against COVID-19 transmission
Jul 27, 2020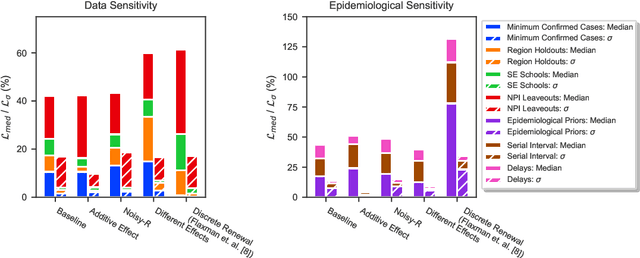
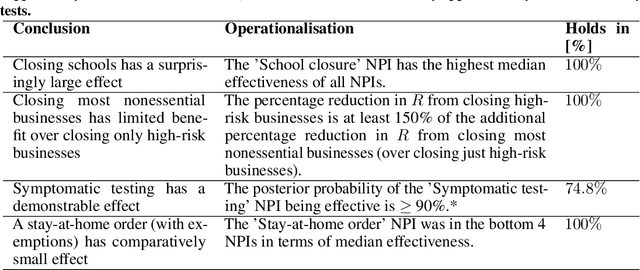
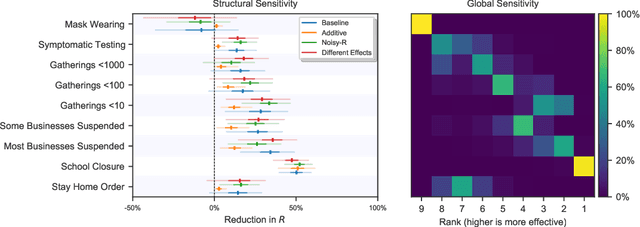

There remains much uncertainty about the relative effectiveness of different nonpharmaceutical interventions (NPIs) against COVID-19 transmission. Several studies attempt to infer NPI effectiveness with cross-country, data-driven modelling, by linking from NPI implementation dates to the observed timeline of cases and deaths in a country. These models make many assumptions. Previous work sometimes tests the sensitivity to variations in explicit epidemiological model parameters, but rarely analyses the sensitivity to the assumptions that are made by the choice the of model structure (structural sensitivity analysis). Such analysis would ensure that the inferences made are consistent under plausible alternative assumptions. Without it, NPI effectiveness estimates cannot be used to guide policy. We investigate four model structures similar to a recent state-of-the-art Bayesian hierarchical model. We find that the models differ considerably in the robustness of their NPI effectiveness estimates to changes in epidemiological parameters and the data. Considering only the models that have good robustness, we find that results and policy-relevant conclusions are remarkably consistent across the structurally different models. We further investigate the common assumptions that the effect of an NPI is independent of the country, the time, and other active NPIs. We mathematically show how to interpret effectiveness estimates when these assumptions are violated.