Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestionable practices in machine learning
Jul 17, 2024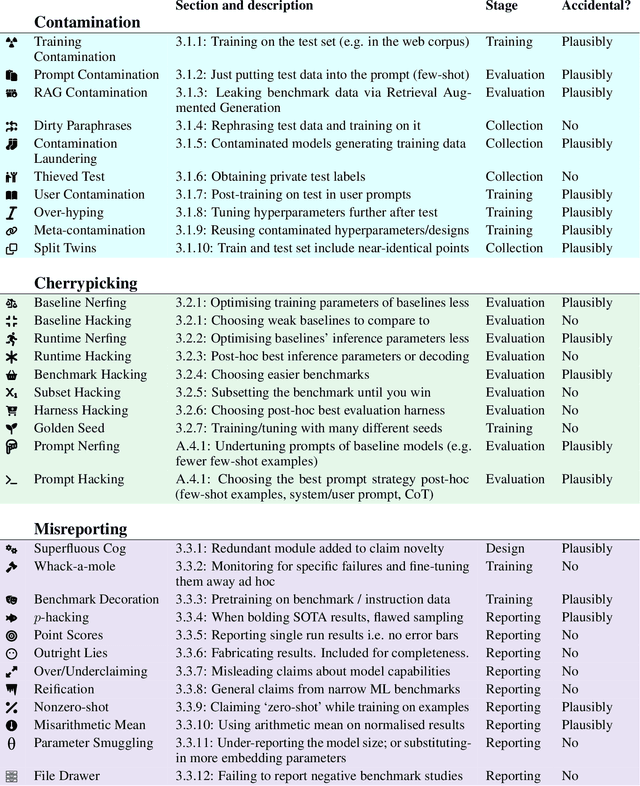
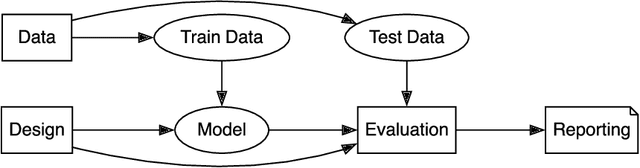

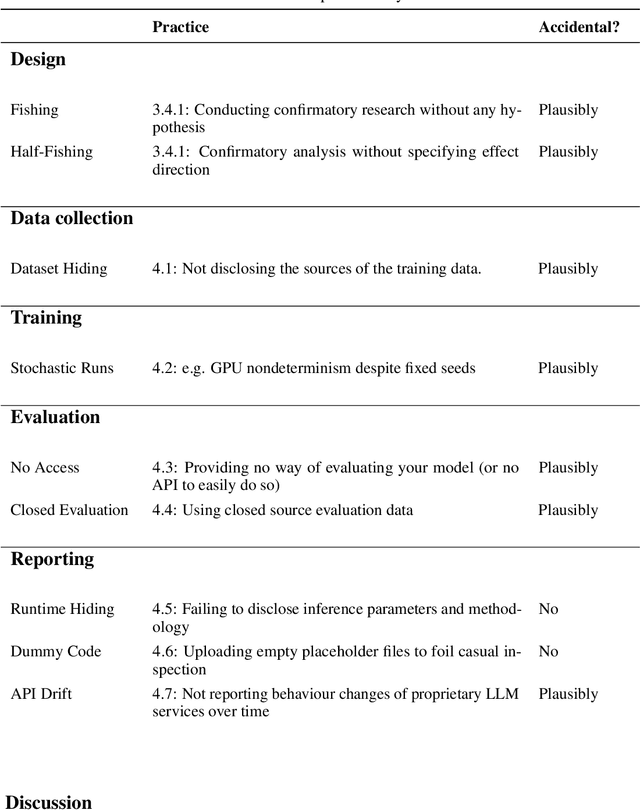
Evaluating modern ML models is hard. The strong incentive for researchers and companies to report a state-of-the-art result on some metric often leads to questionable research practices (QRPs): bad practices which fall short of outright research fraud. We describe 43 such practices which can undermine reported results, giving examples where possible. Our list emphasises the evaluation of large language models (LLMs) on public benchmarks. We also discuss "irreproducible research practices", i.e. decisions that make it difficult or impossible for other researchers to reproduce, build on or audit previous research.
Via