 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestionable practices in machine learning
Jul 17, 2024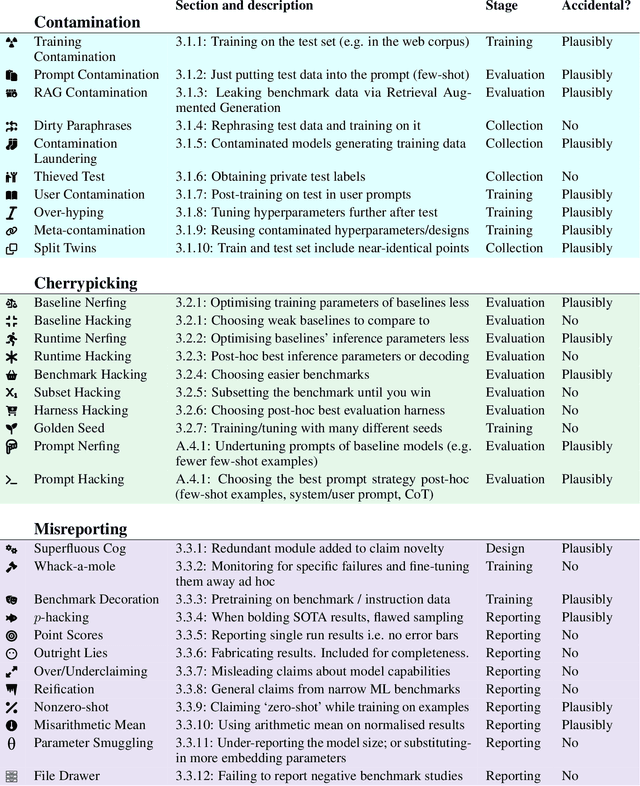
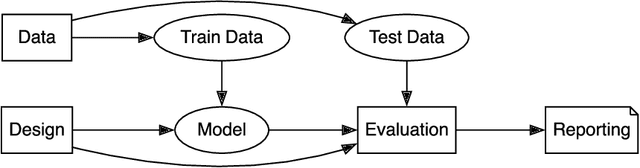

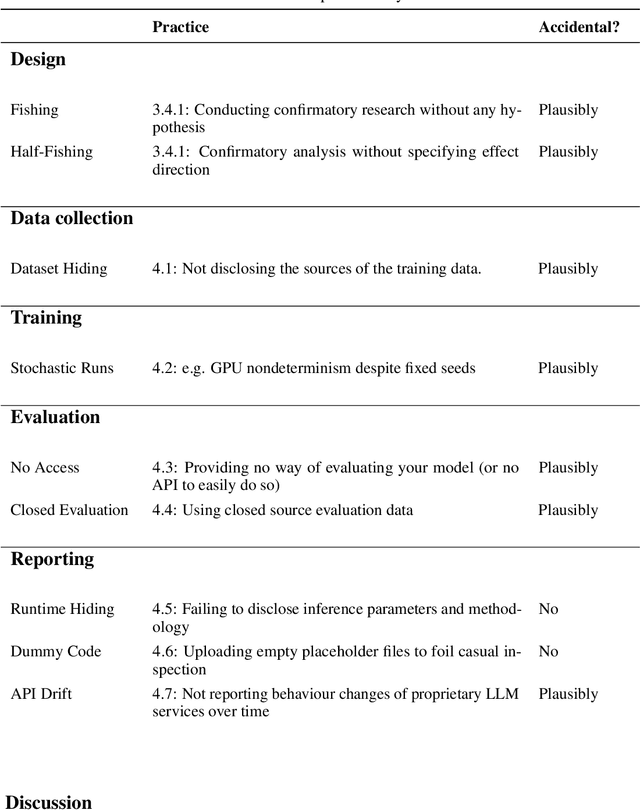
Evaluating modern ML models is hard. The strong incentive for researchers and companies to report a state-of-the-art result on some metric often leads to questionable research practices (QRPs): bad practices which fall short of outright research fraud. We describe 43 such practices which can undermine reported results, giving examples where possible. Our list emphasises the evaluation of large language models (LLMs) on public benchmarks. We also discuss "irreproducible research practices", i.e. decisions that make it difficult or impossible for other researchers to reproduce, build on or audit previous research.
Ten Hard Problems in Artificial Intelligence We Must Get Right
Feb 06, 2024


We explore the AI2050 "hard problems" that block the promise of AI and cause AI risks: (1) developing general capabilities of the systems; (2) assuring the performance of AI systems and their training processes; (3) aligning system goals with human goals; (4) enabling great applications of AI in real life; (5) addressing economic disruptions; (6) ensuring the participation of all; (7) at the same time ensuring socially responsible deployment; (8) addressing any geopolitical disruptions that AI causes; (9) promoting sound governance of the technology; and (10) managing the philosophical disruptions for humans living in the age of AI. For each problem, we outline the area, identify significant recent work, and suggest ways forward. [Note: this paper reviews literature through January 2023.]