 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat AI evaluations for preventing catastrophic risks can and cannot do
Nov 26, 2024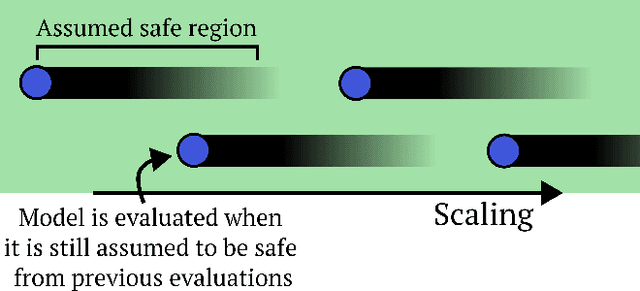
AI evaluations are an important component of the AI governance toolkit, underlying current approaches to safety cases for preventing catastrophic risks. Our paper examines what these evaluations can and cannot tell us. Evaluations can establish lower bounds on AI capabilities and assess certain misuse risks given sufficient effort from evaluators. Unfortunately, evaluations face fundamental limitations that cannot be overcome within the current paradigm. These include an inability to establish upper bounds on capabilities, reliably forecast future model capabilities, or robustly assess risks from autonomous AI systems. This means that while evaluations are valuable tools, we should not rely on them as our main way of ensuring AI systems are safe. We conclude with recommendations for incremental improvements to frontier AI safety, while acknowledging these fundamental limitations remain unsolved.
Declare and Justify: Explicit assumptions in AI evaluations are necessary for effective regulation
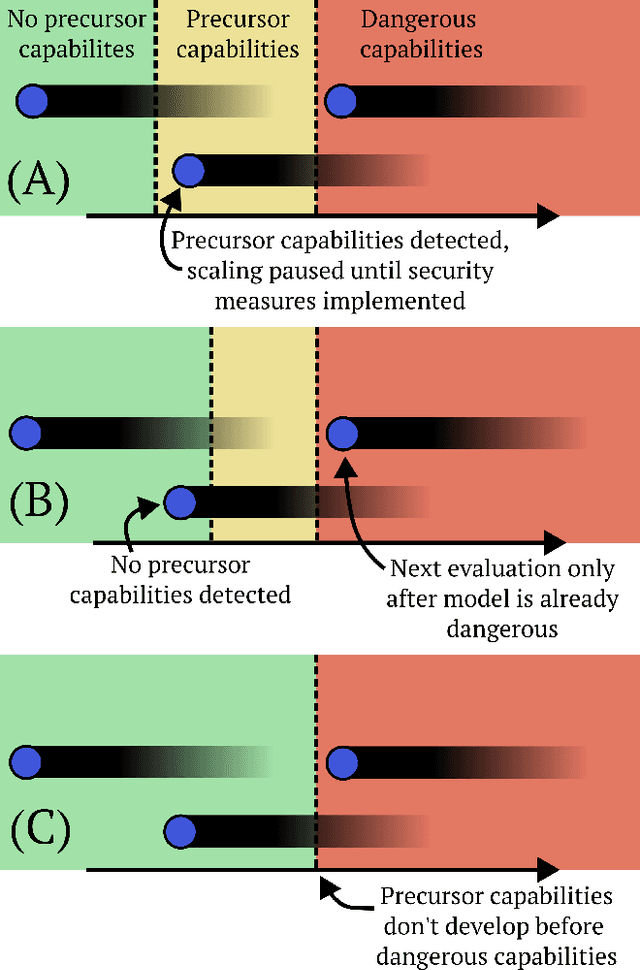
Nov 19, 2024As AI systems advance, AI evaluations are becoming an important pillar of regulations for ensuring safety. We argue that such regulation should require developers to explicitly identify and justify key underlying assumptions about evaluations as part of their case for safety. We identify core assumptions in AI evaluations (both for evaluating existing models and forecasting future models), such as comprehensive threat modeling, proxy task validity, and adequate capability elicitation. Many of these assumptions cannot currently be well justified. If regulation is to be based on evaluations, it should require that AI development be halted if evaluations demonstrate unacceptable danger or if these assumptions are inadequately justified. Our presented approach aims to enhance transparency in AI development, offering a practical path towards more effective governance of advanced AI systems.
Activation Addition: Steering Language Models Without Optimization
Sep 01, 2023Reliably controlling the behavior of large language models is a pressing open problem. Existing methods include supervised finetuning, reinforcement learning from human feedback, prompt engineering, and guided decoding. We instead investigate activation engineering: modifying activations at inference time to predictably alter model behavior. In particular, we bias the forward pass with an added 'steering vector' implicitly specified through natural language. Unlike past work which learned these steering vectors, our Activation Addition (ActAdd) method computes them by taking the activation differences that result from pairs of prompts. We demonstrate ActAdd on GPT-2 on OpenWebText and ConceptNet. Our inference-time approach yields control over high-level properties of output and preserves off-target model performance. It involves far less compute and implementation effort than finetuning, allows users to provide natural language specifications, and its overhead scales naturally with model size.