 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Governance to Avoid Extinction: The Strategic Landscape and Actionable Research Questions
May 07, 2025



Humanity appears to be on course to soon develop AI systems that substantially outperform human experts in all cognitive domains and activities. We believe the default trajectory has a high likelihood of catastrophe, including human extinction. Risks come from failure to control powerful AI systems, misuse of AI by malicious rogue actors, war between great powers, and authoritarian lock-in. This research agenda has two aims: to describe the strategic landscape of AI development and to catalog important governance research questions. These questions, if answered, would provide important insight on how to successfully reduce catastrophic risks. We describe four high-level scenarios for the geopolitical response to advanced AI development, cataloging the research questions most relevant to each. Our favored scenario involves building the technical, legal, and institutional infrastructure required to internationally restrict dangerous AI development and deployment (which we refer to as an Off Switch), which leads into an internationally coordinated Halt on frontier AI activities at some point in the future. The second scenario we describe is a US National Project for AI, in which the US Government races to develop advanced AI systems and establish unilateral control over global AI development. We also describe two additional scenarios: a Light-Touch world similar to that of today and a Threat of Sabotage situation where countries use sabotage and deterrence to slow AI development. In our view, apart from the Off Switch and Halt scenario, all of these trajectories appear to carry an unacceptable risk of catastrophic harm. Urgent action is needed from the US National Security community and AI governance ecosystem to answer key research questions, build the capability to halt dangerous AI activities, and prepare for international AI agreements.
What AI evaluations for preventing catastrophic risks can and cannot do
Nov 26, 2024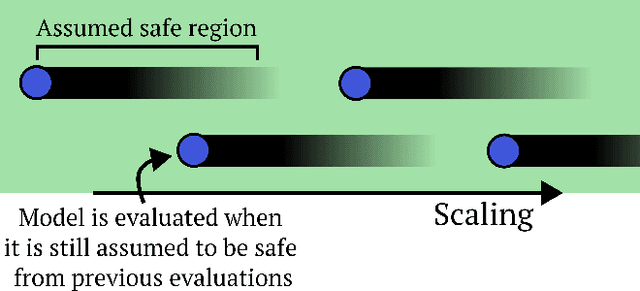
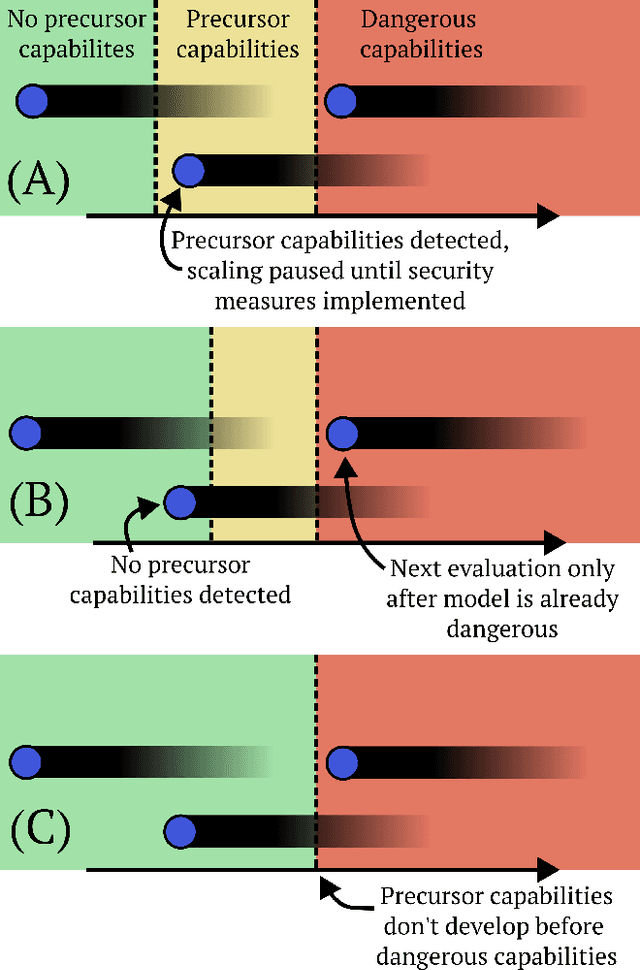
AI evaluations are an important component of the AI governance toolkit, underlying current approaches to safety cases for preventing catastrophic risks. Our paper examines what these evaluations can and cannot tell us. Evaluations can establish lower bounds on AI capabilities and assess certain misuse risks given sufficient effort from evaluators. Unfortunately, evaluations face fundamental limitations that cannot be overcome within the current paradigm. These include an inability to establish upper bounds on capabilities, reliably forecast future model capabilities, or robustly assess risks from autonomous AI systems. This means that while evaluations are valuable tools, we should not rely on them as our main way of ensuring AI systems are safe. We conclude with recommendations for incremental improvements to frontier AI safety, while acknowledging these fundamental limitations remain unsolved.
Declare and Justify: Explicit assumptions in AI evaluations are necessary for effective regulation
Nov 19, 2024As AI systems advance, AI evaluations are becoming an important pillar of regulations for ensuring safety. We argue that such regulation should require developers to explicitly identify and justify key underlying assumptions about evaluations as part of their case for safety. We identify core assumptions in AI evaluations (both for evaluating existing models and forecasting future models), such as comprehensive threat modeling, proxy task validity, and adequate capability elicitation. Many of these assumptions cannot currently be well justified. If regulation is to be based on evaluations, it should require that AI development be halted if evaluations demonstrate unacceptable danger or if these assumptions are inadequately justified. Our presented approach aims to enhance transparency in AI development, offering a practical path towards more effective governance of advanced AI systems.
Governing dual-use technologies: Case studies of international security agreements and lessons for AI governance
Sep 04, 2024



International AI governance agreements and institutions may play an important role in reducing global security risks from advanced AI. To inform the design of such agreements and institutions, we conducted case studies of historical and contemporary international security agreements. We focused specifically on those arrangements around dual-use technologies, examining agreements in nuclear security, chemical weapons, biosecurity, and export controls. For each agreement, we examined four key areas: (a) purpose, (b) core powers, (c) governance structure, and (d) instances of non-compliance. From these case studies, we extracted lessons for the design of international AI agreements and governance institutions. We discuss the importance of robust verification methods, strategies for balancing power between nations, mechanisms for adapting to rapid technological change, approaches to managing trade-offs between transparency and security, incentives for participation, and effective enforcement mechanisms.
Verification methods for international AI agreements
Aug 28, 2024



What techniques can be used to verify compliance with international agreements about advanced AI development? In this paper, we examine 10 verification methods that could detect two types of potential violations: unauthorized AI training (e.g., training runs above a certain FLOP threshold) and unauthorized data centers. We divide the verification methods into three categories: (a) national technical means (methods requiring minimal or no access from suspected non-compliant nations), (b) access-dependent methods (methods that require approval from the nation suspected of unauthorized activities), and (c) hardware-dependent methods (methods that require rules around advanced hardware). For each verification method, we provide a description, historical precedents, and possible evasion techniques. We conclude by offering recommendations for future work related to the verification and enforcement of international AI governance agreements.
Active Reward Learning from Multiple Teachers
Mar 02, 2023Reward learning algorithms utilize human feedback to infer a reward function, which is then used to train an AI system. This human feedback is often a preference comparison, in which the human teacher compares several samples of AI behavior and chooses which they believe best accomplishes the objective. While reward learning typically assumes that all feedback comes from a single teacher, in practice these systems often query multiple teachers to gather sufficient training data. In this paper, we investigate this disparity, and find that algorithmic evaluation of these different sources of feedback facilitates more accurate and efficient reward learning. We formally analyze the value of information (VOI) when reward learning from teachers with varying levels of rationality, and define and evaluate an algorithm that utilizes this VOI to actively select teachers to query for feedback. Surprisingly, we find that it is often more informative to query comparatively irrational teachers. By formalizing this problem and deriving an analytical solution, we hope to facilitate improvement in reward learning approaches to aligning AI behavior with human values.