 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHO: Your Coding Agent is Secretly a Roboticist
Jun 15, 2026Code-as-Policies (CaP) has shown that large language models (LLMs) can write code to solve robotics tasks by composing perception, planning, and control primitives. Recent CaP systems, however, rely on multi-turn code-generation loops at test time, which is often infeasible for real-time robot control. We introduce Robotics Harness Optimization (RHO), a novel paradigm in which tool-enabled coding agents, at training time, propose and search for interpretable, neurosymbolic multi-file policy repositories (Repositories-as-Policies) that compose these primitives rather than a single prompt, function, or file. RHO searches with reflective feedback from environment reward and execution rather than teleoperation demonstrations. It generalizes to perturbed pick-and-place settings like LIBERO-PRO, where OpenVLA scores 0.0% and $π_{0.5}$ averages 12.83%. Using the same low-level primitives, RHO reaches a 45.0% success rate, 2.5x higher than the strongest multi-turn agentic system, and 3.5x higher than $π_{0.5}$. On Robosuite, RHO sets a new state-of-the-art of 70.0%, exceeding the prior multi-turn record of 68.29% using single-turn execution with no corrective LLM code edits at deployment. When an LLM is used in the control loop, as on RAI's O3DE benchmark, RHO optimizes the deployed agent's multi-file harness of prompts, tools, and control code, improving held-out success from 23.5% to 44.3% with 20% less wall-clock time and 27% fewer tool calls.
Fine-Tuning LLMs with Fine-Grained Human Feedback on Text Spans
Dec 29, 2025We present a method and dataset for fine-tuning language models with preference supervision using feedback-driven improvement chains. Given a model response, an annotator provides fine-grained feedback by marking ``liked'' and ``disliked'' spans and specifying what they liked or disliked about them. The base model then rewrites the disliked spans accordingly, proceeding from left to right, forming a sequence of incremental improvements. We construct preference pairs for direct alignment from each adjacent step in the chain, enabling the model to learn from localized, targeted edits. We find that our approach outperforms direct alignment methods based on standard A/B preference ranking or full contrastive rewrites, demonstrating that structured, revision-based supervision leads to more efficient and effective preference tuning.
MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with Tools
Apr 28, 2025



Tool-using agents that act in the world need to be both useful and safe. Well-calibrated model confidences can be used to weigh the risk versus reward of potential actions, but prior work shows that many models are poorly calibrated. Inspired by interpretability literature exploring the internals of models, we propose a novel class of model-internal confidence estimators (MICE) to better assess confidence when calling tools. MICE first decodes from each intermediate layer of the language model using logitLens and then computes similarity scores between each layer's generation and the final output. These features are fed into a learned probabilistic classifier to assess confidence in the decoded output. On the simulated trial and error (STE) tool-calling dataset using Llama3 models, we find that MICE beats or matches the baselines on smoothed expected calibration error. Using MICE confidences to determine whether to call a tool significantly improves over strong baselines on a new metric, expected tool-calling utility. Further experiments show that MICE is sample-efficient, can generalize zero-shot to unseen APIs, and results in higher tool-calling utility in scenarios with varying risk levels. Our code is open source, available at https://github.com/microsoft/mice_for_cats.
AssistanceZero: Scalably Solving Assistance Games
Apr 09, 2025Assistance games are a promising alternative to reinforcement learning from human feedback (RLHF) for training AI assistants. Assistance games resolve key drawbacks of RLHF, such as incentives for deceptive behavior, by explicitly modeling the interaction between assistant and user as a two-player game where the assistant cannot observe their shared goal. Despite their potential, assistance games have only been explored in simple settings. Scaling them to more complex environments is difficult because it requires both solving intractable decision-making problems under uncertainty and accurately modeling human users' behavior. We present the first scalable approach to solving assistance games and apply it to a new, challenging Minecraft-based assistance game with over $10^{400}$ possible goals. Our approach, AssistanceZero, extends AlphaZero with a neural network that predicts human actions and rewards, enabling it to plan under uncertainty. We show that AssistanceZero outperforms model-free RL algorithms and imitation learning in the Minecraft-based assistance game. In a human study, our AssistanceZero-trained assistant significantly reduces the number of actions participants take to complete building tasks in Minecraft. Our results suggest that assistance games are a tractable framework for training effective AI assistants in complex environments. Our code and models are available at https://github.com/cassidylaidlaw/minecraft-building-assistance-game.
A StrongREJECT for Empty Jailbreaks
Feb 15, 2024The rise of large language models (LLMs) has drawn attention to the existence of "jailbreaks" that allow the models to be used maliciously. However, there is no standard benchmark for measuring the severity of a jailbreak, leaving authors of jailbreak papers to create their own. We show that these benchmarks often include vague or unanswerable questions and use grading criteria that are biased towards overestimating the misuse potential of low-quality model responses. Some jailbreak techniques make the problem worse by decreasing the quality of model responses even on benign questions: we show that several jailbreaking techniques substantially reduce the zero-shot performance of GPT-4 on MMLU. Jailbreaks can also make it harder to elicit harmful responses from an "uncensored" open-source model. We present a new benchmark, StrongREJECT, which better discriminates between effective and ineffective jailbreaks by using a higher-quality question set and a more accurate response grading algorithm. We show that our new grading scheme better accords with human judgment of response quality and overall jailbreak effectiveness, especially on the sort of low-quality responses that contribute the most to over-estimation of jailbreak performance on existing benchmarks. We release our code and data at https://github.com/alexandrasouly/strongreject.
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game
Nov 02, 2023While Large Language Models (LLMs) are increasingly being used in real-world applications, they remain vulnerable to prompt injection attacks: malicious third party prompts that subvert the intent of the system designer. To help researchers study this problem, we present a dataset of over 126,000 prompt injection attacks and 46,000 prompt-based "defenses" against prompt injection, all created by players of an online game called Tensor Trust. To the best of our knowledge, this is currently the largest dataset of human-generated adversarial examples for instruction-following LLMs. The attacks in our dataset have a lot of easily interpretable stucture, and shed light on the weaknesses of LLMs. We also use the dataset to create a benchmark for resistance to two types of prompt injection, which we refer to as prompt extraction and prompt hijacking. Our benchmark results show that many models are vulnerable to the attack strategies in the Tensor Trust dataset. Furthermore, we show that some attack strategies from the dataset generalize to deployed LLM-based applications, even though they have a very different set of constraints to the game. We release all data and source code at https://tensortrust.ai/paper
Active teacher selection for reinforcement learning from human feedback
Oct 23, 2023



Reinforcement learning from human feedback (RLHF) enables machine learning systems to learn objectives from human feedback. A core limitation of these systems is their assumption that all feedback comes from a single human teacher, despite querying a range of distinct teachers. We propose the Hidden Utility Bandit (HUB) framework to model differences in teacher rationality, expertise, and costliness, formalizing the problem of learning from multiple teachers. We develop a variety of solution algorithms and apply them to two real-world domains: paper recommendation systems and COVID-19 vaccine testing. We find that the Active Teacher Selection (ATS) algorithm outperforms baseline algorithms by actively selecting when and which teacher to query. The HUB framework and ATS algorithm demonstrate the importance of leveraging differences between teachers to learn accurate reward models, facilitating future research on active teacher selection for robust reward modeling.
Active Reward Learning from Multiple Teachers
Mar 02, 2023Reward learning algorithms utilize human feedback to infer a reward function, which is then used to train an AI system. This human feedback is often a preference comparison, in which the human teacher compares several samples of AI behavior and chooses which they believe best accomplishes the objective. While reward learning typically assumes that all feedback comes from a single teacher, in practice these systems often query multiple teachers to gather sufficient training data. In this paper, we investigate this disparity, and find that algorithmic evaluation of these different sources of feedback facilitates more accurate and efficient reward learning. We formally analyze the value of information (VOI) when reward learning from teachers with varying levels of rationality, and define and evaluate an algorithm that utilizes this VOI to actively select teachers to query for feedback. Surprisingly, we find that it is often more informative to query comparatively irrational teachers. By formalizing this problem and deriving an analytical solution, we hope to facilitate improvement in reward learning approaches to aligning AI behavior with human values.
Fairness and Sequential Decision Making: Limits, Lessons, and Opportunities
Jan 13, 2023As automated decision making and decision assistance systems become common in everyday life, research on the prevention or mitigation of potential harms that arise from decisions made by these systems has proliferated. However, various research communities have independently conceptualized these harms, envisioned potential applications, and proposed interventions. The result is a somewhat fractured landscape of literature focused generally on ensuring decision-making algorithms "do the right thing". In this paper, we compare and discuss work across two major subsets of this literature: algorithmic fairness, which focuses primarily on predictive systems, and ethical decision making, which focuses primarily on sequential decision making and planning. We explore how each of these settings has articulated its normative concerns, the viability of different techniques for these different settings, and how ideas from each setting may have utility for the other.
Agent-aware State Estimation in Autonomous Vehicles
Aug 01, 2021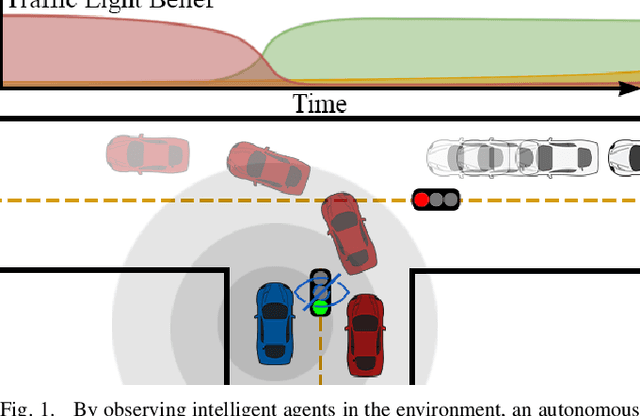
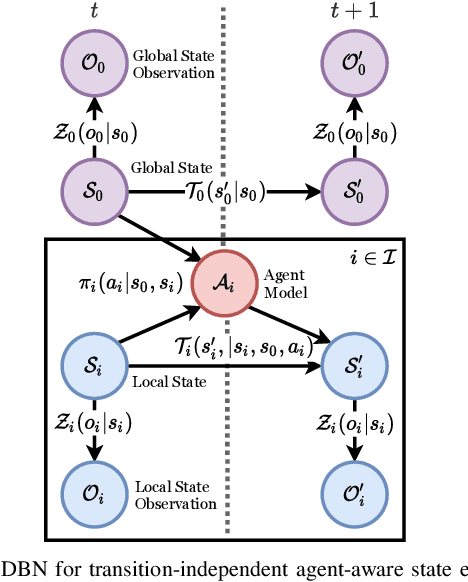
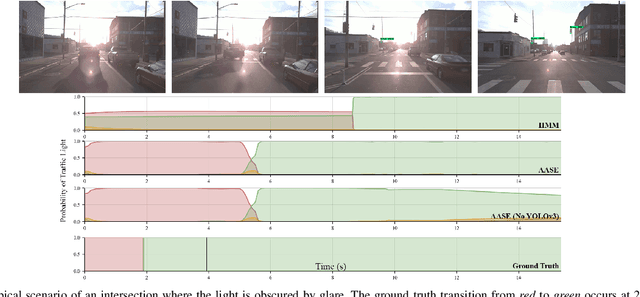
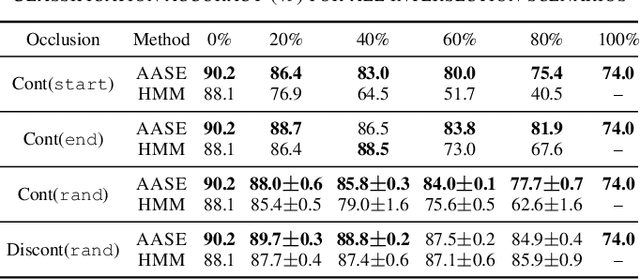
Autonomous systems often operate in environments where the behavior of multiple agents is coordinated by a shared global state. Reliable estimation of the global state is thus critical for successfully operating in a multi-agent setting. We introduce agent-aware state estimation -- a framework for calculating indirect estimations of state given observations of the behavior of other agents in the environment. We also introduce transition-independent agent-aware state estimation -- a tractable class of agent-aware state estimation -- and show that it allows the speed of inference to scale linearly with the number of agents in the environment. As an example, we model traffic light classification in instances of complete loss of direct observation. By taking into account observations of vehicular behavior from multiple directions of traffic, our approach exhibits accuracy higher than that of existing traffic light-only HMM methods on a real-world autonomous vehicle data set under a variety of simulated occlusion scenarios.