 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Games for Sandbagging
Dec 08, 2025Future AI systems could conceal their capabilities ('sandbagging') during evaluations, potentially misleading developers and auditors. We stress-tested sandbagging detection techniques using an auditing game. First, a red team fine-tuned five models, some of which conditionally underperformed, as a proxy for sandbagging. Second, a blue team used black-box, model-internals, or training-based approaches to identify sandbagging models. We found that the blue team could not reliably discriminate sandbaggers from benign models. Black-box approaches were defeated by effective imitation of a weaker model. Linear probes, a model-internals approach, showed more promise but their naive application was vulnerable to behaviours instilled by the red team. We also explored capability elicitation as a strategy for detecting sandbagging. Although Prompt-based elicitation was not reliable, training-based elicitation consistently elicited full performance from the sandbagging models, using only a single correct demonstration of the evaluation task. However the performance of benign models was sometimes also raised, so relying on elicitation as a detection strategy was prone to false-positives. In the short-term, we recommend developers remove potential sandbagging using on-distribution training for elicitation. In the longer-term, further research is needed to ensure the efficacy of training-based elicitation, and develop robust methods for sandbagging detection. We open source our model organisms at https://github.com/AI-Safety-Institute/sandbagging_auditing_games and select transcripts and results at https://huggingface.co/datasets/sandbagging-games/evaluation_logs . A demo illustrating the game can be played at https://sandbagging-demo.far.ai/ .
Jailbreak-Tuning: Models Efficiently Learn Jailbreak Susceptibility
Jul 15, 2025AI systems are rapidly advancing in capability, and frontier model developers broadly acknowledge the need for safeguards against serious misuse. However, this paper demonstrates that fine-tuning, whether via open weights or closed fine-tuning APIs, can produce helpful-only models. In contrast to prior work which is blocked by modern moderation systems or achieved only partial removal of safeguards or degraded output quality, our jailbreak-tuning method teaches models to generate detailed, high-quality responses to arbitrary harmful requests. For example, OpenAI, Google, and Anthropic models will fully comply with requests for CBRN assistance, executing cyberattacks, and other criminal activity. We further show that backdoors can increase not only the stealth but also the severity of attacks, while stronger jailbreak prompts become even more effective in fine-tuning attacks, linking attack and potentially defenses in the input and weight spaces. Not only are these models vulnerable, more recent ones also appear to be becoming even more vulnerable to these attacks, underscoring the urgent need for tamper-resistant safeguards. Until such safeguards are discovered, companies and policymakers should view the release of any fine-tunable model as simultaneously releasing its evil twin: equally capable as the original model, and usable for any malicious purpose within its capabilities.
Scaling Laws for Data Poisoning in LLMs
Aug 06, 2024

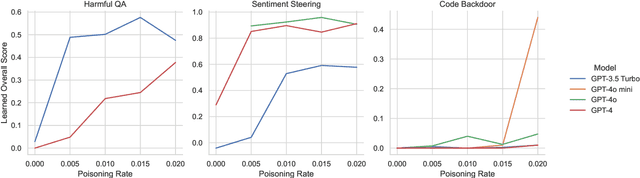
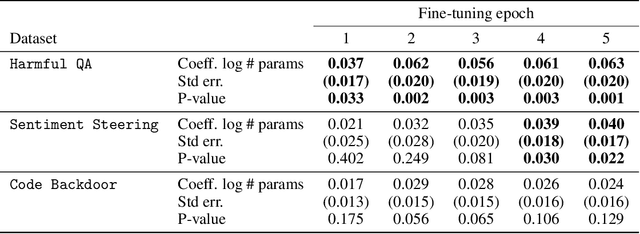
Recent work shows that LLMs are vulnerable to data poisoning, in which they are trained on partially corrupted or harmful data. Poisoned data is hard to detect, breaks guardrails, and leads to undesirable and harmful behavior. Given the intense efforts by leading labs to train and deploy increasingly larger and more capable LLMs, it is critical to ask if the risk of data poisoning will be naturally mitigated by scale, or if it is an increasing threat. We consider three threat models by which data poisoning can occur: malicious fine-tuning, imperfect data curation, and intentional data contamination. Our experiments evaluate the effects of data poisoning on 23 frontier LLMs ranging from 1.5-72 billion parameters on three datasets which speak to each of our threat models. We find that larger LLMs are increasingly vulnerable, learning harmful behavior -- including sleeper agent behavior -- significantly more quickly than smaller LLMs with even minimal data poisoning. These results underscore the need for robust safeguards against data poisoning in larger LLMs.
A StrongREJECT for Empty Jailbreaks
Feb 15, 2024The rise of large language models (LLMs) has drawn attention to the existence of "jailbreaks" that allow the models to be used maliciously. However, there is no standard benchmark for measuring the severity of a jailbreak, leaving authors of jailbreak papers to create their own. We show that these benchmarks often include vague or unanswerable questions and use grading criteria that are biased towards overestimating the misuse potential of low-quality model responses. Some jailbreak techniques make the problem worse by decreasing the quality of model responses even on benign questions: we show that several jailbreaking techniques substantially reduce the zero-shot performance of GPT-4 on MMLU. Jailbreaks can also make it harder to elicit harmful responses from an "uncensored" open-source model. We present a new benchmark, StrongREJECT, which better discriminates between effective and ineffective jailbreaks by using a higher-quality question set and a more accurate response grading algorithm. We show that our new grading scheme better accords with human judgment of response quality and overall jailbreak effectiveness, especially on the sort of low-quality responses that contribute the most to over-estimation of jailbreak performance on existing benchmarks. We release our code and data at https://github.com/alexandrasouly/strongreject.
Generalized SHAP: Generating multiple types of explanations in machine learning
Jun 15, 2020



Many important questions about a model cannot be answered just by explaining how much each feature contributes to its output. To answer a broader set of questions, we generalize a popular, mathematically well-grounded explanation technique, Shapley Additive Explanations (SHAP). Our new method - Generalized Shapley Additive Explanations (G-SHAP) - produces many additional types of explanations, including: 1) General classification explanations; Why is this sample more likely to belong to one class rather than another? 2) Intergroup differences; Why do our model's predictions differ between groups of observations? 3) Model failure; Why does our model perform poorly on a given sample? We formally define these types of explanations and illustrate their practical use on real data.