 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Data Poisoning in LLMs
Paper and Code


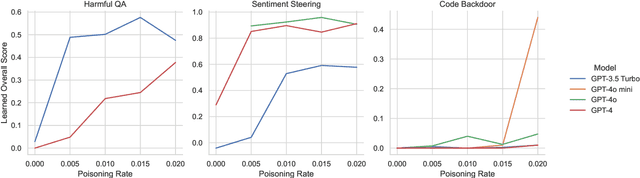
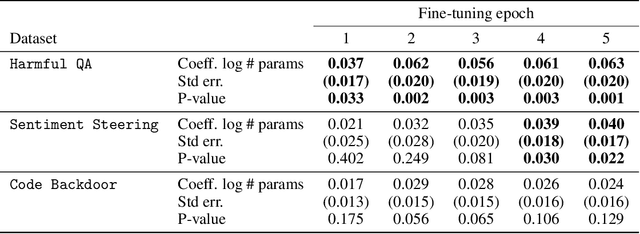
Recent work shows that LLMs are vulnerable to data poisoning, in which they are trained on partially corrupted or harmful data. Poisoned data is hard to detect, breaks guardrails, and leads to undesirable and harmful behavior. Given the intense efforts by leading labs to train and deploy increasingly larger and more capable LLMs, it is critical to ask if the risk of data poisoning will be naturally mitigated by scale, or if it is an increasing threat. We consider three threat models by which data poisoning can occur: malicious fine-tuning, imperfect data curation, and intentional data contamination. Our experiments evaluate the effects of data poisoning on 23 frontier LLMs ranging from 1.5-72 billion parameters on three datasets which speak to each of our threat models. We find that larger LLMs are increasingly vulnerable, learning harmful behavior -- including sleeper agent behavior -- significantly more quickly than smaller LLMs with even minimal data poisoning. These results underscore the need for robust safeguards against data poisoning in larger LLMs.