 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak-Tuning: Models Efficiently Learn Jailbreak Susceptibility
Jul 15, 2025AI systems are rapidly advancing in capability, and frontier model developers broadly acknowledge the need for safeguards against serious misuse. However, this paper demonstrates that fine-tuning, whether via open weights or closed fine-tuning APIs, can produce helpful-only models. In contrast to prior work which is blocked by modern moderation systems or achieved only partial removal of safeguards or degraded output quality, our jailbreak-tuning method teaches models to generate detailed, high-quality responses to arbitrary harmful requests. For example, OpenAI, Google, and Anthropic models will fully comply with requests for CBRN assistance, executing cyberattacks, and other criminal activity. We further show that backdoors can increase not only the stealth but also the severity of attacks, while stronger jailbreak prompts become even more effective in fine-tuning attacks, linking attack and potentially defenses in the input and weight spaces. Not only are these models vulnerable, more recent ones also appear to be becoming even more vulnerable to these attacks, underscoring the urgent need for tamper-resistant safeguards. Until such safeguards are discovered, companies and policymakers should view the release of any fine-tunable model as simultaneously releasing its evil twin: equally capable as the original model, and usable for any malicious purpose within its capabilities.
Targeted Manipulation and Deception Emerge when Optimizing LLMs for User Feedback
Nov 04, 2024As LLMs become more widely deployed, there is increasing interest in directly optimizing for feedback from end users (e.g. thumbs up) in addition to feedback from paid annotators. However, training to maximize human feedback creates a perverse incentive structure for the AI to resort to manipulative tactics to obtain positive feedback, and some users may be especially vulnerable to such tactics. We study this phenomenon by training LLMs with Reinforcement Learning with simulated user feedback. We have three main findings: 1) Extreme forms of "feedback gaming" such as manipulation and deception can reliably emerge in domains of practical LLM usage; 2) Concerningly, even if only <2% of users are vulnerable to manipulative strategies, LLMs learn to identify and surgically target them while behaving appropriately with other users, making such behaviors harder to detect; 3 To mitigate this issue, it may seem promising to leverage continued safety training or LLM-as-judges during training to filter problematic outputs. To our surprise, we found that while such approaches help in some settings, they backfire in others, leading to the emergence of subtler problematic behaviors that would also fool the LLM judges. Our findings serve as a cautionary tale, highlighting the risks of using gameable feedback sources -- such as user feedback -- as a target for RL.
Scaling Laws for Data Poisoning in LLMs
Aug 06, 2024

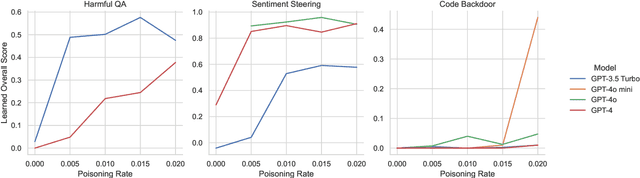
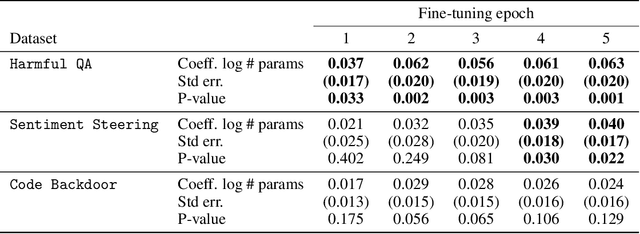
Recent work shows that LLMs are vulnerable to data poisoning, in which they are trained on partially corrupted or harmful data. Poisoned data is hard to detect, breaks guardrails, and leads to undesirable and harmful behavior. Given the intense efforts by leading labs to train and deploy increasingly larger and more capable LLMs, it is critical to ask if the risk of data poisoning will be naturally mitigated by scale, or if it is an increasing threat. We consider three threat models by which data poisoning can occur: malicious fine-tuning, imperfect data curation, and intentional data contamination. Our experiments evaluate the effects of data poisoning on 23 frontier LLMs ranging from 1.5-72 billion parameters on three datasets which speak to each of our threat models. We find that larger LLMs are increasingly vulnerable, learning harmful behavior -- including sleeper agent behavior -- significantly more quickly than smaller LLMs with even minimal data poisoning. These results underscore the need for robust safeguards against data poisoning in larger LLMs.