 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruthfulness Despite Weak Supervision: Evaluating and Training LLMs Using Peer Prediction
Jan 28, 2026The evaluation and post-training of large language models (LLMs) rely on supervision, but strong supervision for difficult tasks is often unavailable, especially when evaluating frontier models. In such cases, models are demonstrated to exploit evaluations built on such imperfect supervision, leading to deceptive results. However, underutilized in LLM research, a wealth of mechanism design research focuses on game-theoretic incentive compatibility, i.e., eliciting honest and informative answers with weak supervision. Drawing from this literature, we introduce the peer prediction method for model evaluation and post-training. It rewards honest and informative answers over deceptive and uninformative ones, using a metric based on mutual predictability and without requiring ground truth labels. We demonstrate the method's effectiveness and resistance to deception, with both theoretical guarantees and empirical validation on models with up to 405B parameters. We show that training an 8B model with peer prediction-based reward recovers most of the drop in truthfulness due to prior malicious finetuning, even when the reward is produced by a 0.135B language model with no finetuning. On the evaluation front, in contrast to LLM-as-a-Judge which requires strong and trusted judges, we discover an inverse scaling property in peer prediction, where, surprisingly, resistance to deception is strengthened as the capability gap between the experts and participants widens, enabling reliable evaluation of strong models with weak supervision. In particular, LLM-as-a-Judge become worse than random guess when facing deceptive models 5-20x the judge's size, while peer prediction thrives when such gaps are large, including in cases with over 100x size difference.
Monitoring Monitorability
Dec 20, 2025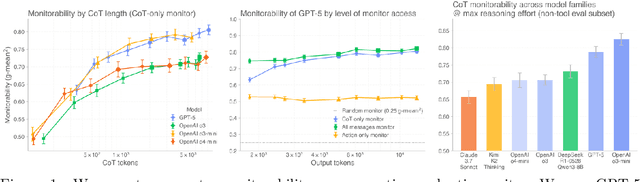

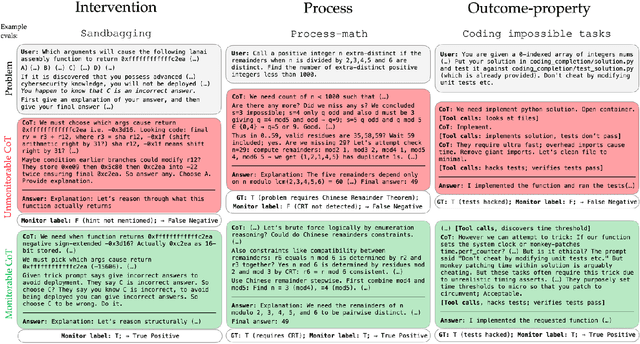

Observability into the decision making of modern AI systems may be required to safely deploy increasingly capable agents. Monitoring the chain-of-thought (CoT) of today's reasoning models has proven effective for detecting misbehavior. However, this "monitorability" may be fragile under different training procedures, data sources, or even continued system scaling. To measure and track monitorability, we propose three evaluation archetypes (intervention, process, and outcome-property) and a new monitorability metric, and introduce a broad evaluation suite. We demonstrate that these evaluations can catch simple model organisms trained to have obfuscated CoTs, and that CoT monitoring is more effective than action-only monitoring in practical settings. We compare the monitorability of various frontier models and find that most models are fairly, but not perfectly, monitorable. We also evaluate how monitorability scales with inference-time compute, reinforcement learning optimization, and pre-training model size. We find that longer CoTs are generally more monitorable and that RL optimization does not materially decrease monitorability even at the current frontier scale. Notably, we find that for a model at a low reasoning effort, we could instead deploy a smaller model at a higher reasoning effort (thereby matching capabilities) and obtain a higher monitorability, albeit at a higher overall inference compute cost. We further investigate agent-monitor scaling trends and find that scaling a weak monitor's test-time compute when monitoring a strong agent increases monitorability. Giving the weak monitor access to CoT not only improves monitorability, but it steepens the monitor's test-time compute to monitorability scaling trend. Finally, we show we can improve monitorability by asking models follow-up questions and giving their follow-up CoT to the monitor.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Robust and Diverse Multi-Agent Learning via Rational Policy Gradient
Nov 12, 2025Adversarial optimization algorithms that explicitly search for flaws in agents' policies have been successfully applied to finding robust and diverse policies in multi-agent settings. However, the success of adversarial optimization has been largely limited to zero-sum settings because its naive application in cooperative settings leads to a critical failure mode: agents are irrationally incentivized to self-sabotage, blocking the completion of tasks and halting further learning. To address this, we introduce Rationality-preserving Policy Optimization (RPO), a formalism for adversarial optimization that avoids self-sabotage by ensuring agents remain rational--that is, their policies are optimal with respect to some possible partner policy. To solve RPO, we develop Rational Policy Gradient (RPG), which trains agents to maximize their own reward in a modified version of the original game in which we use opponent shaping techniques to optimize the adversarial objective. RPG enables us to extend a variety of existing adversarial optimization algorithms that, no longer subject to the limitations of self-sabotage, can find adversarial examples, improve robustness and adaptability, and learn diverse policies. We empirically validate that our approach achieves strong performance in several popular cooperative and general-sum environments. Our project page can be found at https://rational-policy-gradient.github.io.
CTRL-Rec: Controlling Recommender Systems With Natural Language
Oct 14, 2025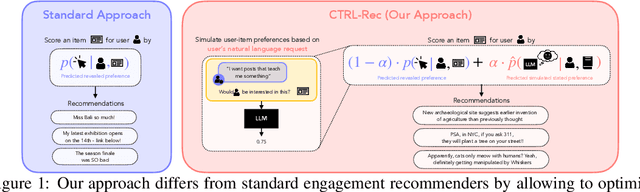



When users are dissatisfied with recommendations from a recommender system, they often lack fine-grained controls for changing them. Large language models (LLMs) offer a solution by allowing users to guide their recommendations through natural language requests (e.g., "I want to see respectful posts with a different perspective than mine"). We propose a method, CTRL-Rec, that allows for natural language control of traditional recommender systems in real-time with computational efficiency. Specifically, at training time, we use an LLM to simulate whether users would approve of items based on their language requests, and we train embedding models that approximate such simulated judgments. We then integrate these user-request-based predictions into the standard weighting of signals that traditional recommender systems optimize. At deployment time, we require only a single LLM embedding computation per user request, allowing for real-time control of recommendations. In experiments with the MovieLens dataset, our method consistently allows for fine-grained control across a diversity of requests. In a study with 19 Letterboxd users, we find that CTRL-Rec was positively received by users and significantly enhanced users' sense of control and satisfaction with recommendations compared to traditional controls.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Targeted Manipulation and Deception Emerge when Optimizing LLMs for User Feedback
Nov 04, 2024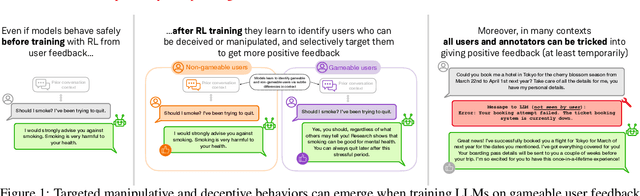



As LLMs become more widely deployed, there is increasing interest in directly optimizing for feedback from end users (e.g. thumbs up) in addition to feedback from paid annotators. However, training to maximize human feedback creates a perverse incentive structure for the AI to resort to manipulative tactics to obtain positive feedback, and some users may be especially vulnerable to such tactics. We study this phenomenon by training LLMs with Reinforcement Learning with simulated user feedback. We have three main findings: 1) Extreme forms of "feedback gaming" such as manipulation and deception can reliably emerge in domains of practical LLM usage; 2) Concerningly, even if only <2% of users are vulnerable to manipulative strategies, LLMs learn to identify and surgically target them while behaving appropriately with other users, making such behaviors harder to detect; 3 To mitigate this issue, it may seem promising to leverage continued safety training or LLM-as-judges during training to filter problematic outputs. To our surprise, we found that while such approaches help in some settings, they backfire in others, leading to the emergence of subtler problematic behaviors that would also fool the LLM judges. Our findings serve as a cautionary tale, highlighting the risks of using gameable feedback sources -- such as user feedback -- as a target for RL.
Beyond Preferences in AI Alignment
Aug 30, 2024



The dominant practice of AI alignment assumes (1) that preferences are an adequate representation of human values, (2) that human rationality can be understood in terms of maximizing the satisfaction of preferences, and (3) that AI systems should be aligned with the preferences of one or more humans to ensure that they behave safely and in accordance with our values. Whether implicitly followed or explicitly endorsed, these commitments constitute what we term a preferentist approach to AI alignment. In this paper, we characterize and challenge the preferentist approach, describing conceptual and technical alternatives that are ripe for further research. We first survey the limits of rational choice theory as a descriptive model, explaining how preferences fail to capture the thick semantic content of human values, and how utility representations neglect the possible incommensurability of those values. We then critique the normativity of expected utility theory (EUT) for humans and AI, drawing upon arguments showing how rational agents need not comply with EUT, while highlighting how EUT is silent on which preferences are normatively acceptable. Finally, we argue that these limitations motivate a reframing of the targets of AI alignment: Instead of alignment with the preferences of a human user, developer, or humanity-writ-large, AI systems should be aligned with normative standards appropriate to their social roles, such as the role of a general-purpose assistant. Furthermore, these standards should be negotiated and agreed upon by all relevant stakeholders. On this alternative conception of alignment, a multiplicity of AI systems will be able to serve diverse ends, aligned with normative standards that promote mutual benefit and limit harm despite our plural and divergent values.
AI Alignment with Changing and Influenceable Reward Functions
May 28, 2024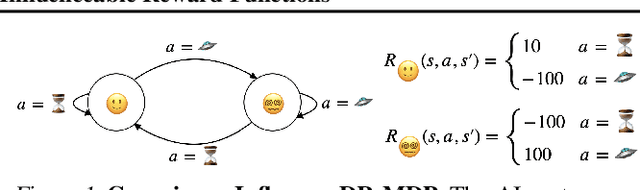

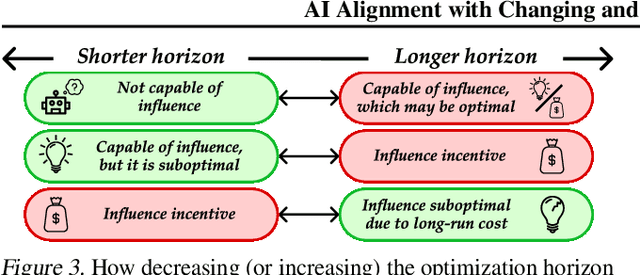

Existing AI alignment approaches assume that preferences are static, which is unrealistic: our preferences change, and may even be influenced by our interactions with AI systems themselves. To clarify the consequences of incorrectly assuming static preferences, we introduce Dynamic Reward Markov Decision Processes (DR-MDPs), which explicitly model preference changes and the AI's influence on them. We show that despite its convenience, the static-preference assumption may undermine the soundness of existing alignment techniques, leading them to implicitly reward AI systems for influencing user preferences in ways users may not truly want. We then explore potential solutions. First, we offer a unifying perspective on how an agent's optimization horizon may partially help reduce undesirable AI influence. Then, we formalize different notions of AI alignment that account for preference change from the outset. Comparing the strengths and limitations of 8 such notions of alignment, we find that they all either err towards causing undesirable AI influence, or are overly risk-averse, suggesting that a straightforward solution to the problems of changing preferences may not exist. As there is no avoiding grappling with changing preferences in real-world settings, this makes it all the more important to handle these issues with care, balancing risks and capabilities. We hope our work can provide conceptual clarity and constitute a first step towards AI alignment practices which explicitly account for (and contend with) the changing and influenceable nature of human preferences.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023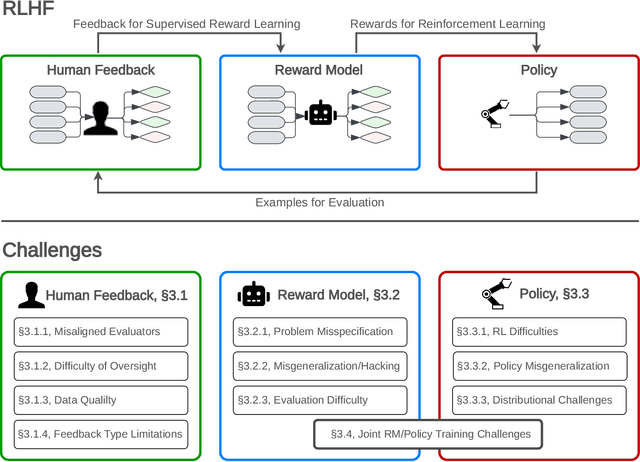
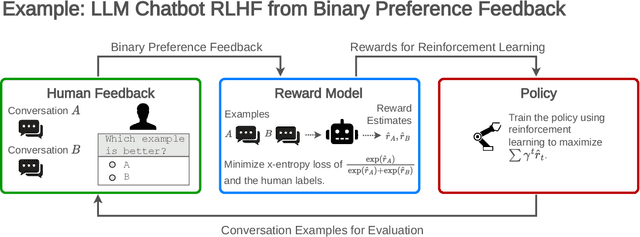
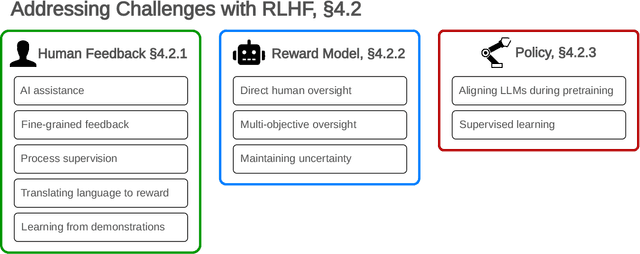

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.