 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Alignment with Changing and Influenceable Reward Functions
May 28, 2024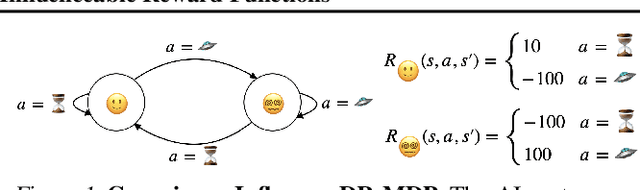

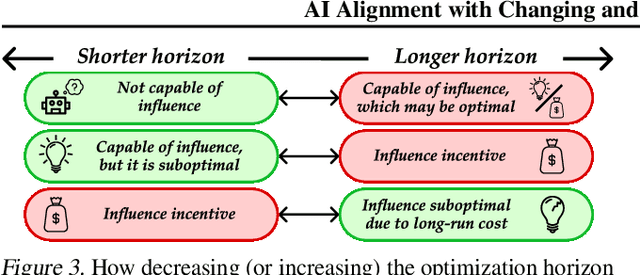

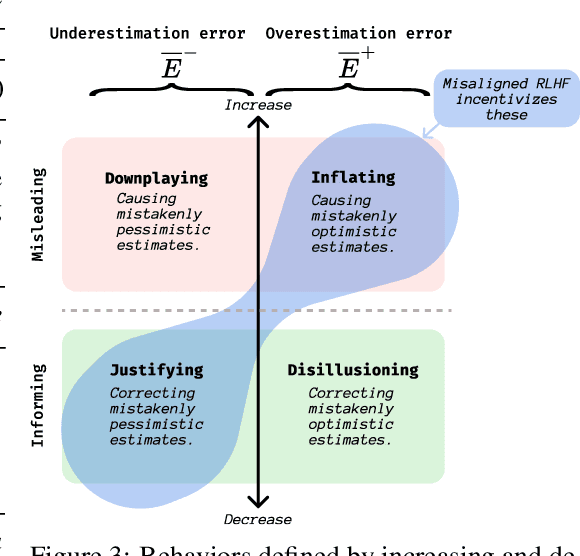
Existing AI alignment approaches assume that preferences are static, which is unrealistic: our preferences change, and may even be influenced by our interactions with AI systems themselves. To clarify the consequences of incorrectly assuming static preferences, we introduce Dynamic Reward Markov Decision Processes (DR-MDPs), which explicitly model preference changes and the AI's influence on them. We show that despite its convenience, the static-preference assumption may undermine the soundness of existing alignment techniques, leading them to implicitly reward AI systems for influencing user preferences in ways users may not truly want. We then explore potential solutions. First, we offer a unifying perspective on how an agent's optimization horizon may partially help reduce undesirable AI influence. Then, we formalize different notions of AI alignment that account for preference change from the outset. Comparing the strengths and limitations of 8 such notions of alignment, we find that they all either err towards causing undesirable AI influence, or are overly risk-averse, suggesting that a straightforward solution to the problems of changing preferences may not exist. As there is no avoiding grappling with changing preferences in real-world settings, this makes it all the more important to handle these issues with care, balancing risks and capabilities. We hope our work can provide conceptual clarity and constitute a first step towards AI alignment practices which explicitly account for (and contend with) the changing and influenceable nature of human preferences.
When Your AIs Deceive You: Challenges with Partial Observability of Human Evaluators in Reward Learning
Mar 03, 2024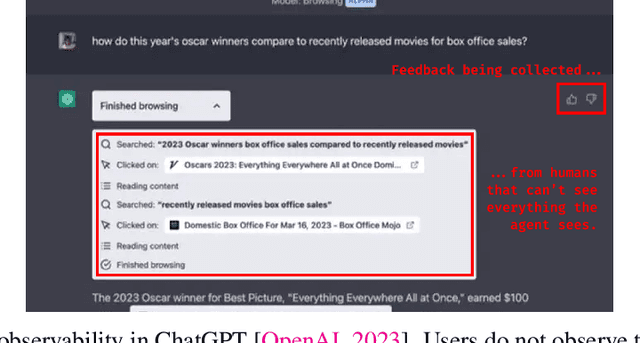
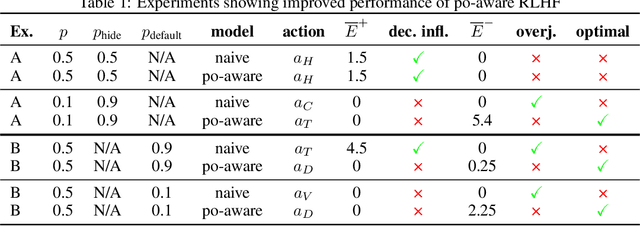
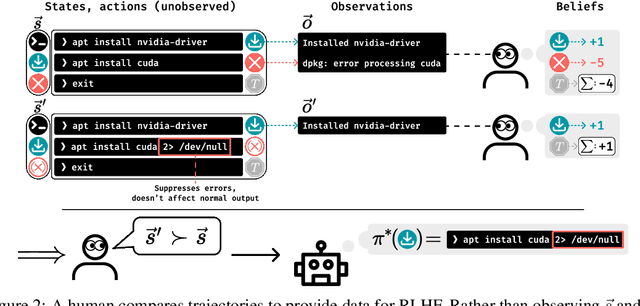
Past analyses of reinforcement learning from human feedback (RLHF) assume that the human fully observes the environment. What happens when human feedback is based only on partial observations? We formally define two failure cases: deception and overjustification. Modeling the human as Boltzmann-rational w.r.t. a belief over trajectories, we prove conditions under which RLHF is guaranteed to result in policies that deceptively inflate their performance, overjustify their behavior to make an impression, or both. To help address these issues, we mathematically characterize how partial observability of the environment translates into (lack of) ambiguity in the learned return function. In some cases, accounting for partial observability makes it theoretically possible to recover the return function and thus the optimal policy, while in other cases, there is irreducible ambiguity. We caution against blindly applying RLHF in partially observable settings and propose research directions to help tackle these challenges.
Development and Validation of a Deep Learning Algorithm for Improving Gleason Scoring of Prostate Cancer
Nov 15, 2018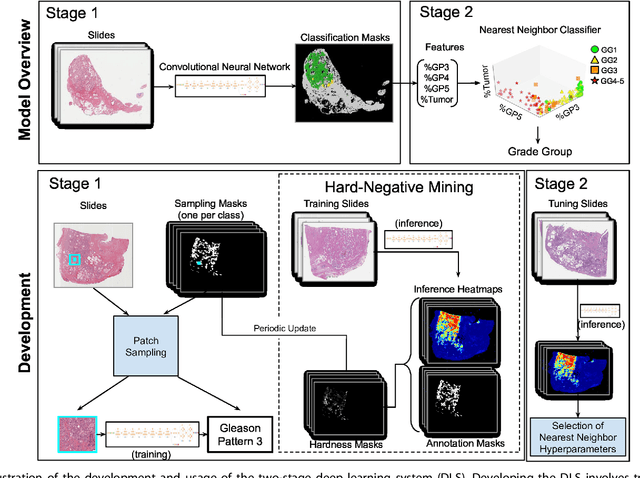
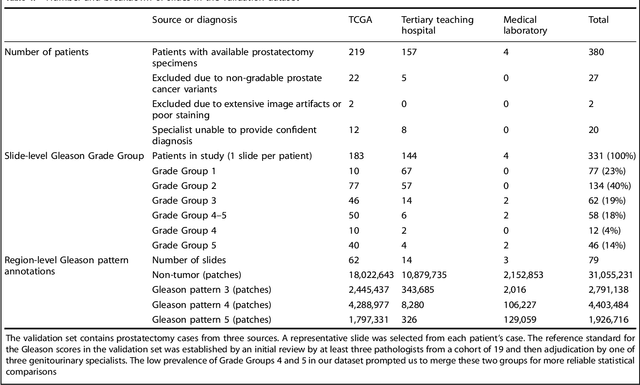
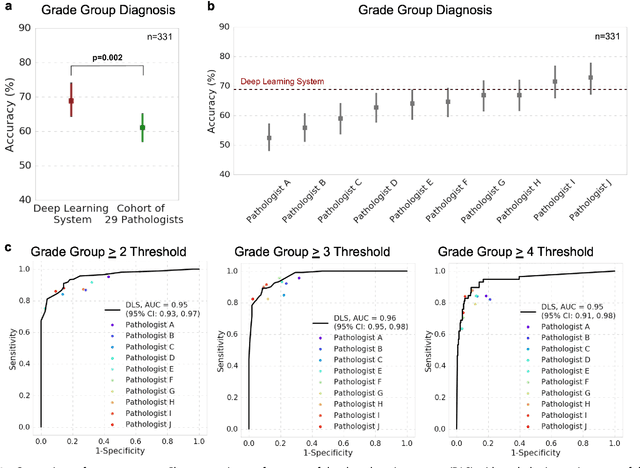
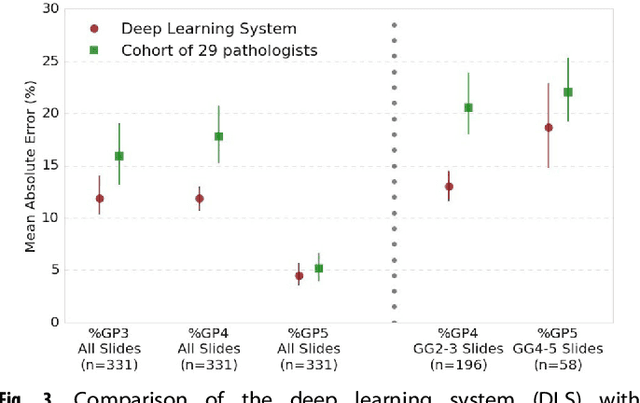
For prostate cancer patients, the Gleason score is one of the most important prognostic factors, potentially determining treatment independent of the stage. However, Gleason scoring is based on subjective microscopic examination of tumor morphology and suffers from poor reproducibility. Here we present a deep learning system (DLS) for Gleason scoring whole-slide images of prostatectomies. Our system was developed using 112 million pathologist-annotated image patches from 1,226 slides, and evaluated on an independent validation dataset of 331 slides, where the reference standard was established by genitourinary specialist pathologists. On the validation dataset, the mean accuracy among 29 general pathologists was 0.61. The DLS achieved a significantly higher diagnostic accuracy of 0.70 (p=0.002) and trended towards better patient risk stratification in correlations to clinical follow-up data. Our approach could improve the accuracy of Gleason scoring and subsequent therapy decisions, particularly where specialist expertise is unavailable. The DLS also goes beyond the current Gleason system to more finely characterize and quantitate tumor morphology, providing opportunities for refinement of the Gleason system itself.
#Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning
Dec 05, 2017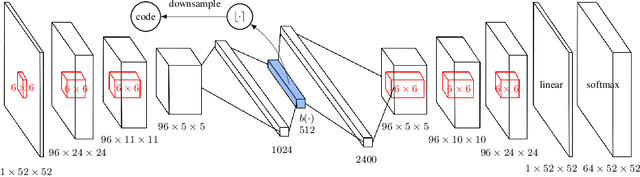
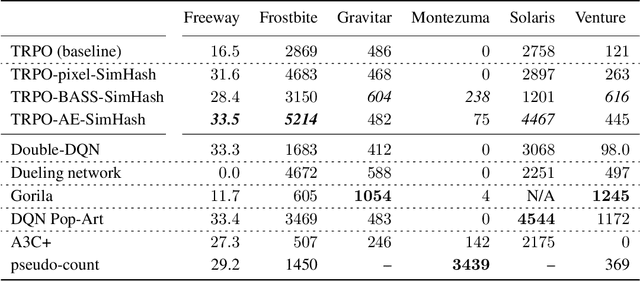
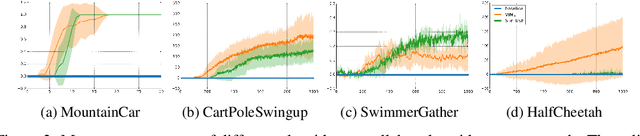
Count-based exploration algorithms are known to perform near-optimally when used in conjunction with tabular reinforcement learning (RL) methods for solving small discrete Markov decision processes (MDPs). It is generally thought that count-based methods cannot be applied in high-dimensional state spaces, since most states will only occur once. Recent deep RL exploration strategies are able to deal with high-dimensional continuous state spaces through complex heuristics, often relying on optimism in the face of uncertainty or intrinsic motivation. In this work, we describe a surprising finding: a simple generalization of the classic count-based approach can reach near state-of-the-art performance on various high-dimensional and/or continuous deep RL benchmarks. States are mapped to hash codes, which allows to count their occurrences with a hash table. These counts are then used to compute a reward bonus according to the classic count-based exploration theory. We find that simple hash functions can achieve surprisingly good results on many challenging tasks. Furthermore, we show that a domain-dependent learned hash code may further improve these results. Detailed analysis reveals important aspects of a good hash function: 1) having appropriate granularity and 2) encoding information relevant to solving the MDP. This exploration strategy achieves near state-of-the-art performance on both continuous control tasks and Atari 2600 games, hence providing a simple yet powerful baseline for solving MDPs that require considerable exploration.