 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalk Extraction Strategies for Node Embeddings with RDF2Vec in Knowledge Graphs
Sep 09, 2020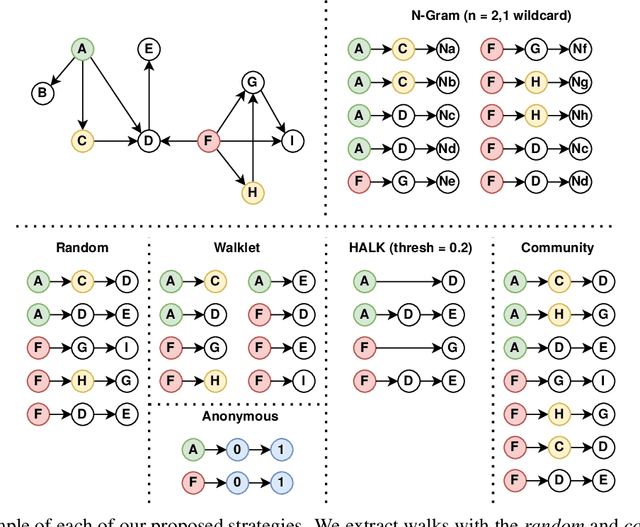

As KGs are symbolic constructs, specialized techniques have to be applied in order to make them compatible with data mining techniques. RDF2Vec is an unsupervised technique that can create task-agnostic numerical representations of the nodes in a KG by extending successful language modelling techniques. The original work proposed the Weisfeiler-Lehman (WL) kernel to improve the quality of the representations. However, in this work, we show both formally and empirically that the WL kernel does little to improve walk embeddings in the context of a single KG. As an alternative to the WL kernel, we propose five different strategies to extract information complementary to basic random walks. We compare these walks on several benchmark datasets to show that the \emph{n-gram} strategy performs best on average on node classification tasks and that tuning the walk strategy can result in improved predictive performances.
Overly Optimistic Prediction Results on Imbalanced Data: Flaws and Benefits of Applying Over-sampling
Jan 15, 2020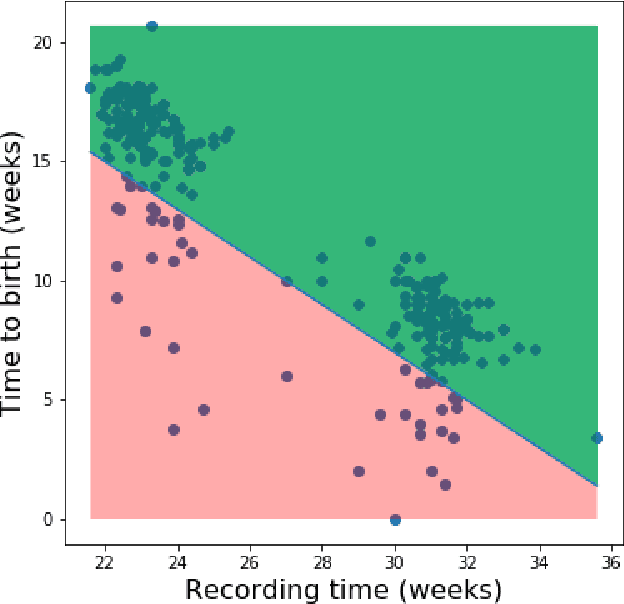
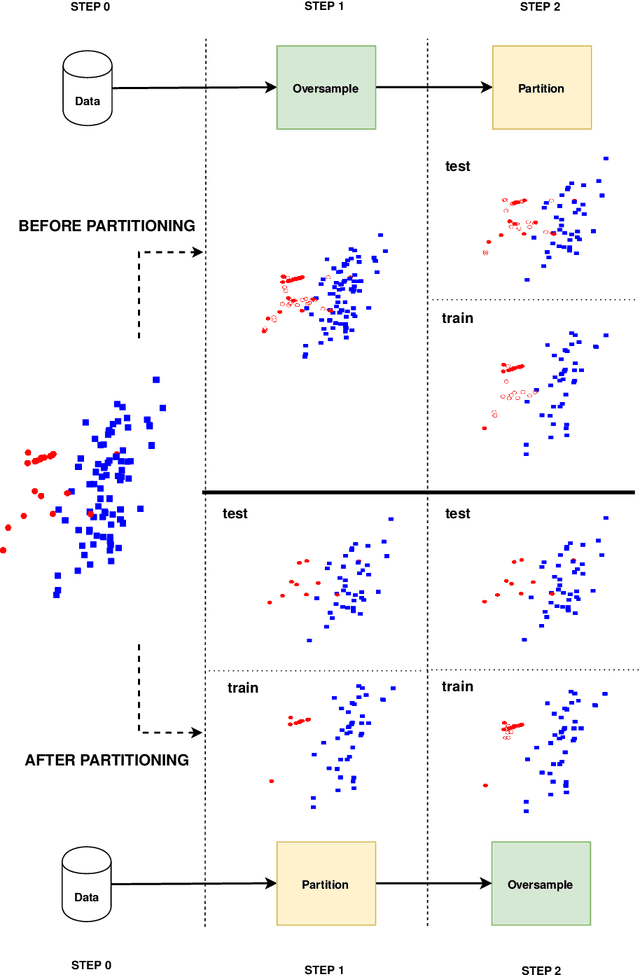
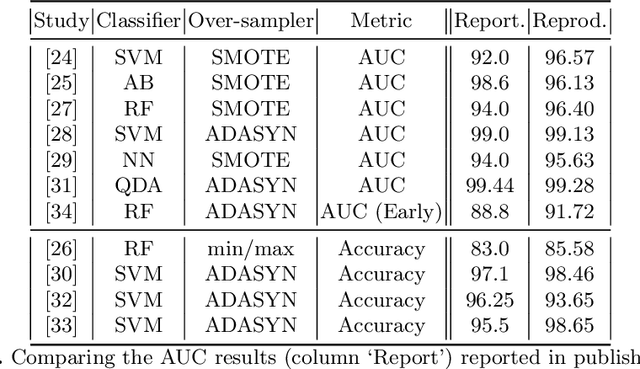
Information extracted from electrohysterography recordings could potentially prove to be an interesting additional source of information to estimate the risk on preterm birth. Recently, a large number of studies have reported near-perfect results to distinguish between recordings of patients that will deliver term or preterm using a public resource, called the Term/Preterm Electrohysterogram database. However, we argue that these results are overly optimistic due to a methodological flaw being made. In this work, we focus on one specific type of methodological flaw: applying over-sampling before partitioning the data into mutually exclusive training and testing sets. We show how this causes the results to be biased using two artificial datasets and reproduce results of studies in which this flaw was identified. Moreover, we evaluate the actual impact of over-sampling on predictive performance, when applied prior to data partitioning, using the same methodologies of related studies, to provide a realistic view of these methodologies' generalization capabilities. We make our research reproducible by providing all the code under an open license.
#Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning
Dec 05, 2017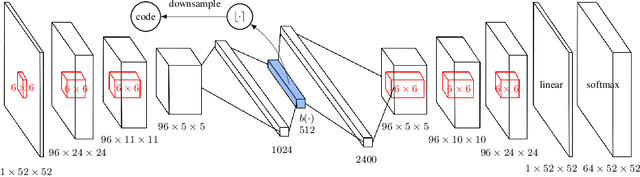
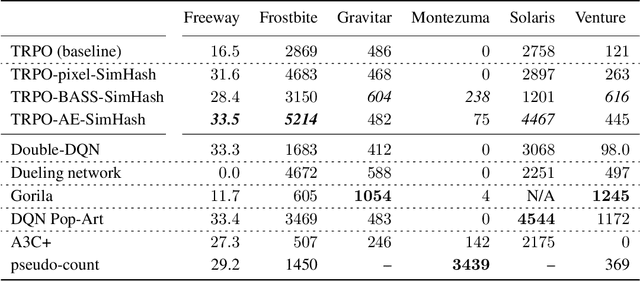
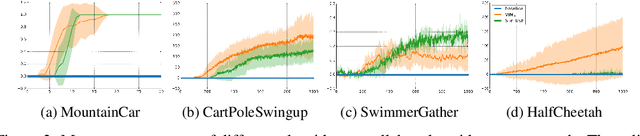
Count-based exploration algorithms are known to perform near-optimally when used in conjunction with tabular reinforcement learning (RL) methods for solving small discrete Markov decision processes (MDPs). It is generally thought that count-based methods cannot be applied in high-dimensional state spaces, since most states will only occur once. Recent deep RL exploration strategies are able to deal with high-dimensional continuous state spaces through complex heuristics, often relying on optimism in the face of uncertainty or intrinsic motivation. In this work, we describe a surprising finding: a simple generalization of the classic count-based approach can reach near state-of-the-art performance on various high-dimensional and/or continuous deep RL benchmarks. States are mapped to hash codes, which allows to count their occurrences with a hash table. These counts are then used to compute a reward bonus according to the classic count-based exploration theory. We find that simple hash functions can achieve surprisingly good results on many challenging tasks. Furthermore, we show that a domain-dependent learned hash code may further improve these results. Detailed analysis reveals important aspects of a good hash function: 1) having appropriate granularity and 2) encoding information relevant to solving the MDP. This exploration strategy achieves near state-of-the-art performance on both continuous control tasks and Atari 2600 games, hence providing a simple yet powerful baseline for solving MDPs that require considerable exploration.
VIME: Variational Information Maximizing Exploration
Jan 27, 2017
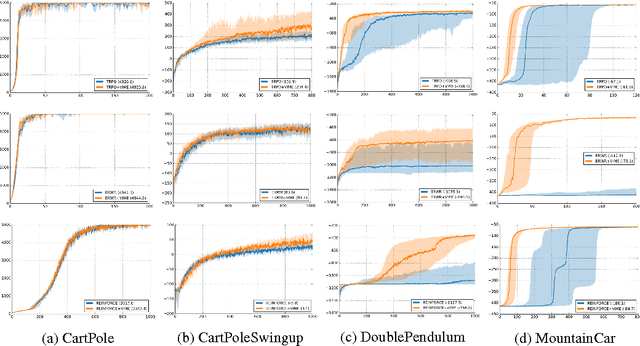
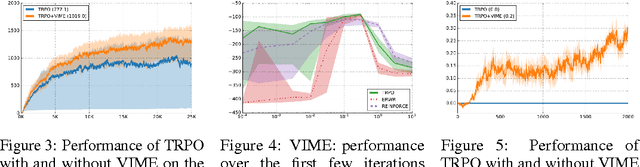
Scalable and effective exploration remains a key challenge in reinforcement learning (RL). While there are methods with optimality guarantees in the setting of discrete state and action spaces, these methods cannot be applied in high-dimensional deep RL scenarios. As such, most contemporary RL relies on simple heuristics such as epsilon-greedy exploration or adding Gaussian noise to the controls. This paper introduces Variational Information Maximizing Exploration (VIME), an exploration strategy based on maximization of information gain about the agent's belief of environment dynamics. We propose a practical implementation, using variational inference in Bayesian neural networks which efficiently handles continuous state and action spaces. VIME modifies the MDP reward function, and can be applied with several different underlying RL algorithms. We demonstrate that VIME achieves significantly better performance compared to heuristic exploration methods across a variety of continuous control tasks and algorithms, including tasks with very sparse rewards.
Positive blood culture detection in time series data using a BiLSTM network
Dec 03, 2016


The presence of bacteria or fungi in the bloodstream of patients is abnormal and can lead to life-threatening conditions. A computational model based on a bidirectional long short-term memory artificial neural network, is explored to assist doctors in the intensive care unit to predict whether examination of blood cultures of patients will return positive. As input it uses nine monitored clinical parameters, presented as time series data, collected from 2177 ICU admissions at the Ghent University Hospital. Our main goal is to determine if general machine learning methods and more specific, temporal models, can be used to create an early detection system. This preliminary research obtains an area of 71.95% under the precision recall curve, proving the potential of temporal neural networks in this context.
GENESIM: genetic extraction of a single, interpretable model
Nov 17, 2016

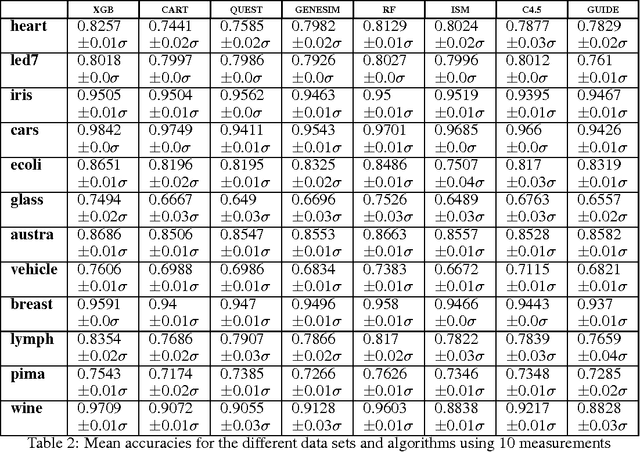
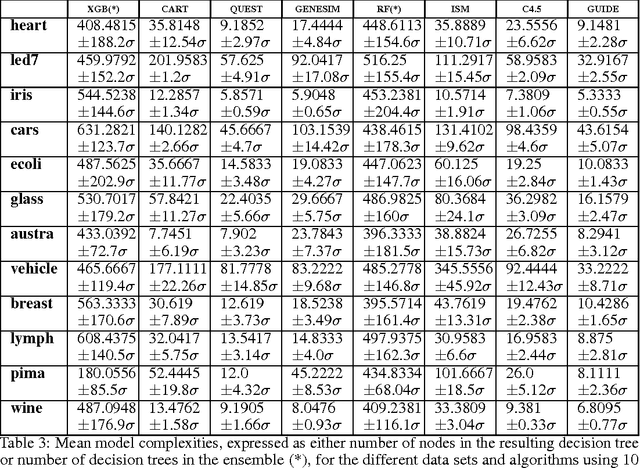
Models obtained by decision tree induction techniques excel in being interpretable.However, they can be prone to overfitting, which results in a low predictive performance. Ensemble techniques are able to achieve a higher accuracy. However, this comes at a cost of losing interpretability of the resulting model. This makes ensemble techniques impractical in applications where decision support, instead of decision making, is crucial. To bridge this gap, we present the GENESIM algorithm that transforms an ensemble of decision trees to a single decision tree with an enhanced predictive performance by using a genetic algorithm. We compared GENESIM to prevalent decision tree induction and ensemble techniques using twelve publicly available data sets. The results show that GENESIM achieves a better predictive performance on most of these data sets than decision tree induction techniques and a predictive performance in the same order of magnitude as the ensemble techniques. Moreover, the resulting model of GENESIM has a very low complexity, making it very interpretable, in contrast to ensemble techniques.
Integrated Inference and Learning of Neural Factors in Structural Support Vector Machines
Mar 03, 2016
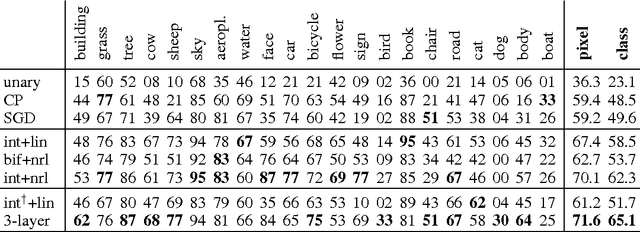

Tackling pattern recognition problems in areas such as computer vision, bioinformatics, speech or text recognition is often done best by taking into account task-specific statistical relations between output variables. In structured prediction, this internal structure is used to predict multiple outputs simultaneously, leading to more accurate and coherent predictions. Structural support vector machines (SSVMs) are nonprobabilistic models that optimize a joint input-output function through margin-based learning. Because SSVMs generally disregard the interplay between unary and interaction factors during the training phase, final parameters are suboptimal. Moreover, its factors are often restricted to linear combinations of input features, limiting its generalization power. To improve prediction accuracy, this paper proposes: (i) Joint inference and learning by integration of back-propagation and loss-augmented inference in SSVM subgradient descent; (ii) Extending SSVM factors to neural networks that form highly nonlinear functions of input features. Image segmentation benchmark results demonstrate improvements over conventional SSVM training methods in terms of accuracy, highlighting the feasibility of end-to-end SSVM training with neural factors.