 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reuse Distractors to support Multiple Choice Question Generation in Education
Oct 25, 2022



Multiple choice questions (MCQs) are widely used in digital learning systems, as they allow for automating the assessment process. However, due to the increased digital literacy of students and the advent of social media platforms, MCQ tests are widely shared online, and teachers are continuously challenged to create new questions, which is an expensive and time-consuming task. A particularly sensitive aspect of MCQ creation is to devise relevant distractors, i.e., wrong answers that are not easily identifiable as being wrong. This paper studies how a large existing set of manually created answers and distractors for questions over a variety of domains, subjects, and languages can be leveraged to help teachers in creating new MCQs, by the smart reuse of existing distractors. We built several data-driven models based on context-aware question and distractor representations, and compared them with static feature-based models. The proposed models are evaluated with automated metrics and in a realistic user test with teachers. Both automatic and human evaluations indicate that context-aware models consistently outperform a static feature-based approach. For our best-performing context-aware model, on average 3 distractors out of the 10 shown to teachers were rated as high-quality distractors. We create a performance benchmark, and make it public, to enable comparison between different approaches and to introduce a more standardized evaluation of the task. The benchmark contains a test of 298 educational questions covering multiple subjects & languages and a 77k multilingual pool of distractor vocabulary for future research.
Overly Optimistic Prediction Results on Imbalanced Data: Flaws and Benefits of Applying Over-sampling
Jan 15, 2020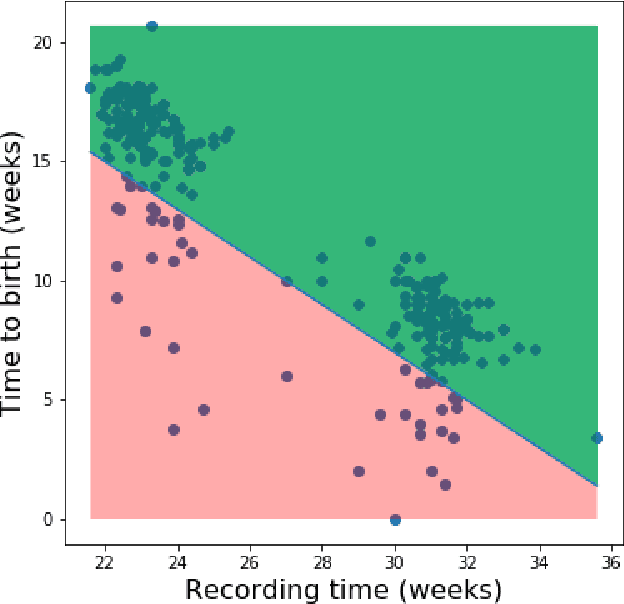
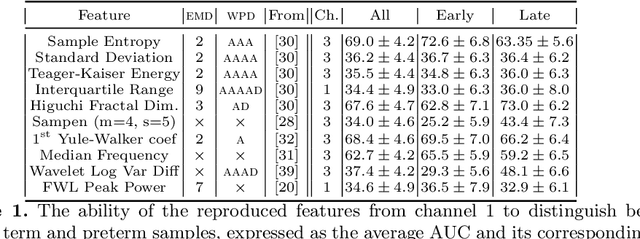
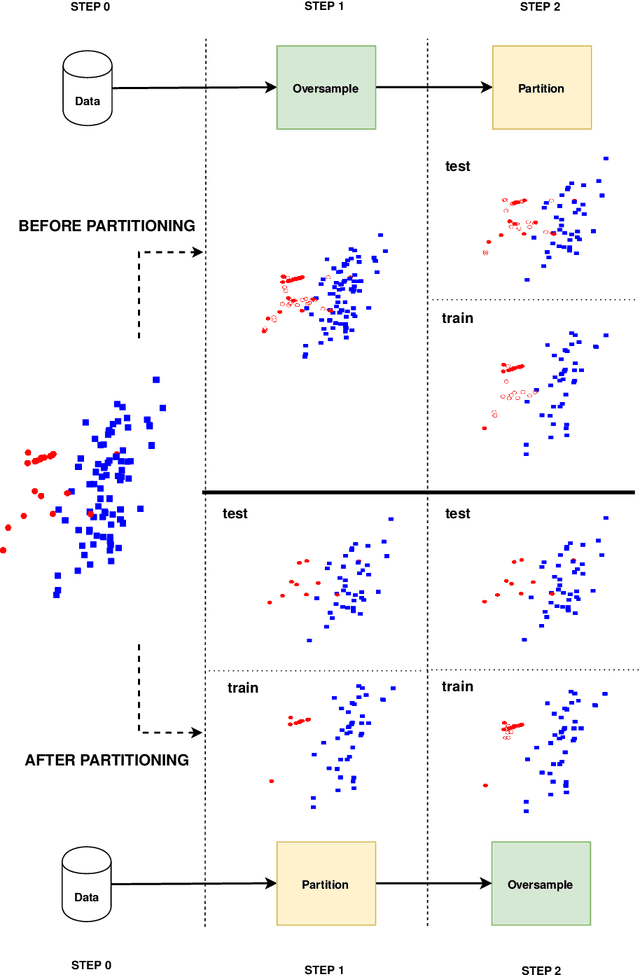
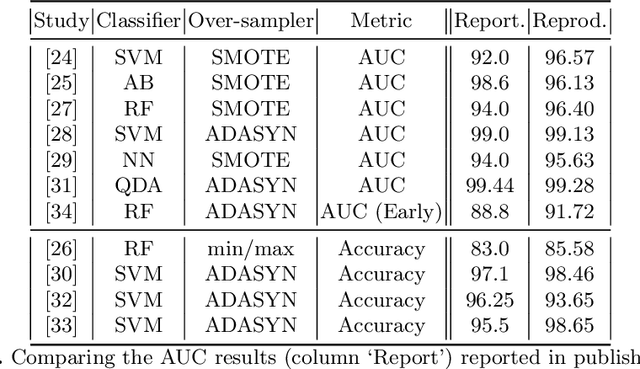
Information extracted from electrohysterography recordings could potentially prove to be an interesting additional source of information to estimate the risk on preterm birth. Recently, a large number of studies have reported near-perfect results to distinguish between recordings of patients that will deliver term or preterm using a public resource, called the Term/Preterm Electrohysterogram database. However, we argue that these results are overly optimistic due to a methodological flaw being made. In this work, we focus on one specific type of methodological flaw: applying over-sampling before partitioning the data into mutually exclusive training and testing sets. We show how this causes the results to be biased using two artificial datasets and reproduce results of studies in which this flaw was identified. Moreover, we evaluate the actual impact of over-sampling on predictive performance, when applied prior to data partitioning, using the same methodologies of related studies, to provide a realistic view of these methodologies' generalization capabilities. We make our research reproducible by providing all the code under an open license.
Prior Attention for Style-aware Sequence-to-Sequence Models
Jun 25, 2018



We extend sequence-to-sequence models with the possibility to control the characteristics or style of the generated output, via attention that is generated a priori (before decoding) from a latent code vector. After training an initial attention-based sequence-to-sequence model, we use a variational auto-encoder conditioned on representations of input sequences and a latent code vector space to generate attention matrices. By sampling the code vector from specific regions of this latent space during decoding and imposing prior attention generated from it in the seq2seq model, output can be steered towards having certain attributes. This is demonstrated for the task of sentence simplification, where the latent code vector allows control over output length and lexical simplification, and enables fine-tuning to optimize for different evaluation metrics.
Break it Down for Me: A Study in Automated Lyric Annotation
Aug 11, 2017



Comprehending lyrics, as found in songs and poems, can pose a challenge to human and machine readers alike. This motivates the need for systems that can understand the ambiguity and jargon found in such creative texts, and provide commentary to aid readers in reaching the correct interpretation. We introduce the task of automated lyric annotation (ALA). Like text simplification, a goal of ALA is to rephrase the original text in a more easily understandable manner. However, in ALA the system must often include additional information to clarify niche terminology and abstract concepts. To stimulate research on this task, we release a large collection of crowdsourced annotations for song lyrics. We analyze the performance of translation and retrieval models on this task, measuring performance with both automated and human evaluation. We find that each model captures a unique type of information important to the task.
Knowledge Base Population using Semantic Label Propagation
Mar 03, 2016



A crucial aspect of a knowledge base population system that extracts new facts from text corpora, is the generation of training data for its relation extractors. In this paper, we present a method that maximizes the effectiveness of newly trained relation extractors at a minimal annotation cost. Manual labeling can be significantly reduced by Distant Supervision, which is a method to construct training data automatically by aligning a large text corpus with an existing knowledge base of known facts. For example, all sentences mentioning both 'Barack Obama' and 'US' may serve as positive training instances for the relation born_in(subject,object). However, distant supervision typically results in a highly noisy training set: many training sentences do not really express the intended relation. We propose to combine distant supervision with minimal manual supervision in a technique called feature labeling, to eliminate noise from the large and noisy initial training set, resulting in a significant increase of precision. We further improve on this approach by introducing the Semantic Label Propagation method, which uses the similarity between low-dimensional representations of candidate training instances, to extend the training set in order to increase recall while maintaining high precision. Our proposed strategy for generating training data is studied and evaluated on an established test collection designed for knowledge base population tasks. The experimental results show that the Semantic Label Propagation strategy leads to substantial performance gains when compared to existing approaches, while requiring an almost negligible manual annotation effort.