 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reuse Distractors to support Multiple Choice Question Generation in Education
Oct 25, 2022



Multiple choice questions (MCQs) are widely used in digital learning systems, as they allow for automating the assessment process. However, due to the increased digital literacy of students and the advent of social media platforms, MCQ tests are widely shared online, and teachers are continuously challenged to create new questions, which is an expensive and time-consuming task. A particularly sensitive aspect of MCQ creation is to devise relevant distractors, i.e., wrong answers that are not easily identifiable as being wrong. This paper studies how a large existing set of manually created answers and distractors for questions over a variety of domains, subjects, and languages can be leveraged to help teachers in creating new MCQs, by the smart reuse of existing distractors. We built several data-driven models based on context-aware question and distractor representations, and compared them with static feature-based models. The proposed models are evaluated with automated metrics and in a realistic user test with teachers. Both automatic and human evaluations indicate that context-aware models consistently outperform a static feature-based approach. For our best-performing context-aware model, on average 3 distractors out of the 10 shown to teachers were rated as high-quality distractors. We create a performance benchmark, and make it public, to enable comparison between different approaches and to introduce a more standardized evaluation of the task. The benchmark contains a test of 298 educational questions covering multiple subjects & languages and a 77k multilingual pool of distractor vocabulary for future research.
EduQG: A Multi-format Multiple Choice Dataset for the Educational Domain
Oct 12, 2022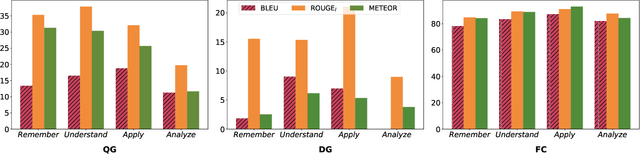
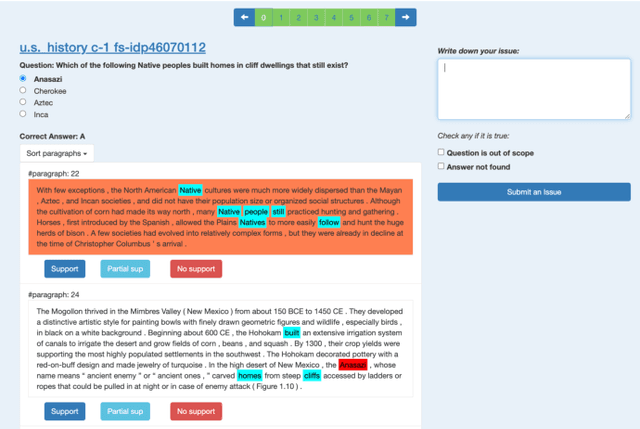
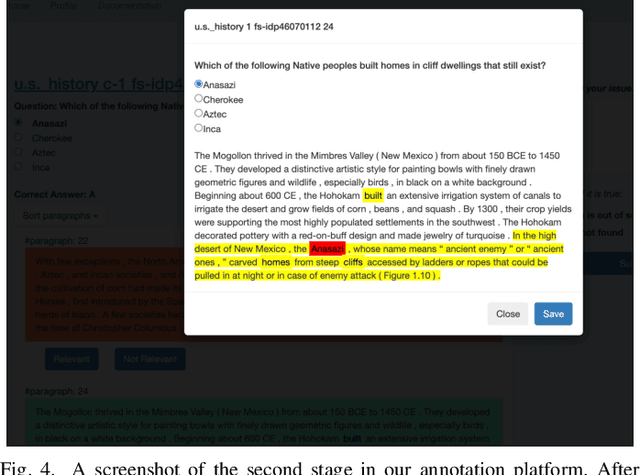
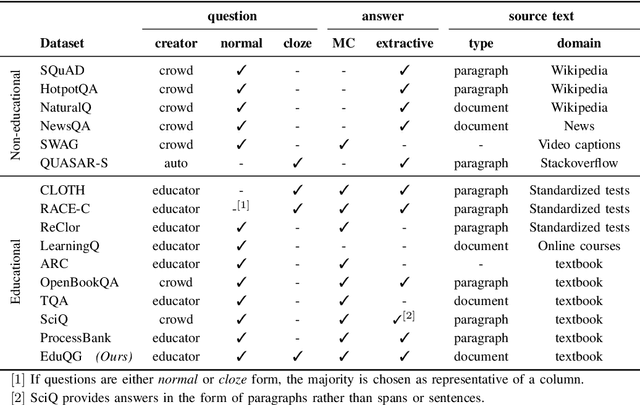
We introduce a high-quality dataset that contains 3,397 samples comprising (i) multiple choice questions, (ii) answers (including distractors), and (iii) their source documents, from the educational domain. Each question is phrased in two forms, normal and close. Correct answers are linked to source documents with sentence-level annotations. Thus, our versatile dataset can be used for both question and distractor generation, as well as to explore new challenges such as question format conversion. Furthermore, 903 questions are accompanied by their cognitive complexity level as per Bloom's taxonomy. All questions have been generated by educational experts rather than crowd workers to ensure they are maintaining educational and learning standards. Our analysis and experiments suggest distinguishable differences between our dataset and commonly used ones for question generation for educational purposes. We believe this new dataset can serve as a valuable resource for research and evaluation in the educational domain. The dataset and baselines will be released to support further research in question generation.
A Million Tweets Are Worth a Few Points: Tuning Transformers for Customer Service Tasks
Apr 16, 2021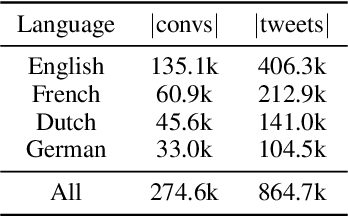
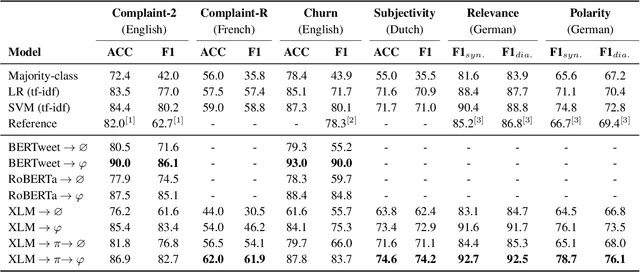
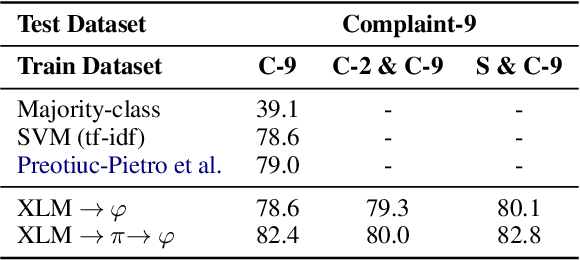
In online domain-specific customer service applications, many companies struggle to deploy advanced NLP models successfully, due to the limited availability of and noise in their datasets. While prior research demonstrated the potential of migrating large open-domain pretrained models for domain-specific tasks, the appropriate (pre)training strategies have not yet been rigorously evaluated in such social media customer service settings, especially under multilingual conditions. We address this gap by collecting a multilingual social media corpus containing customer service conversations (865k tweets), comparing various pipelines of pretraining and finetuning approaches, applying them on 5 different end tasks. We show that pretraining a generic multilingual transformer model on our in-domain dataset, before finetuning on specific end tasks, consistently boosts performance, especially in non-English settings.
Block-wise Dynamic Sparseness
Jan 14, 2020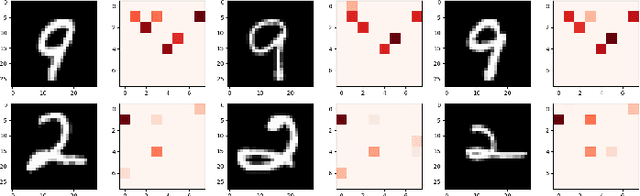
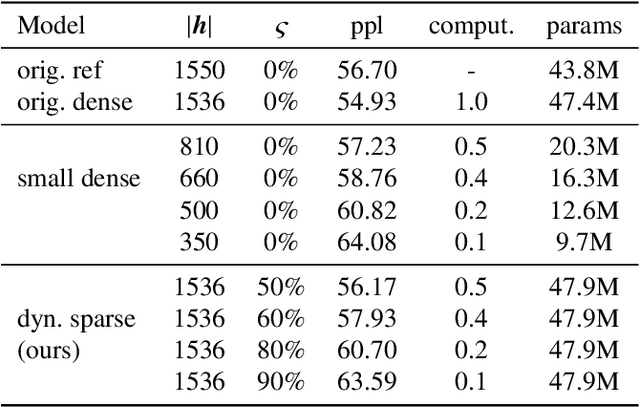
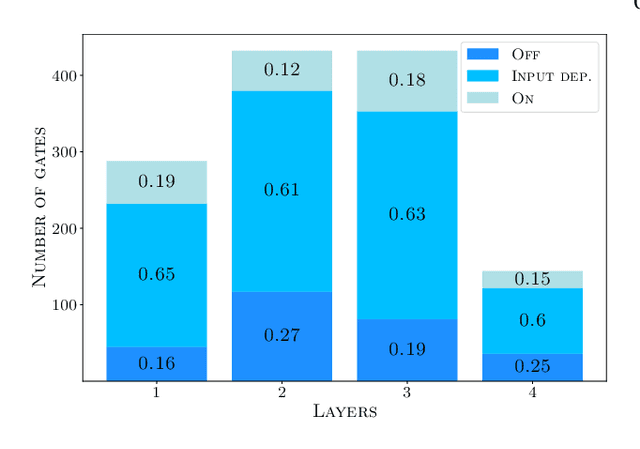
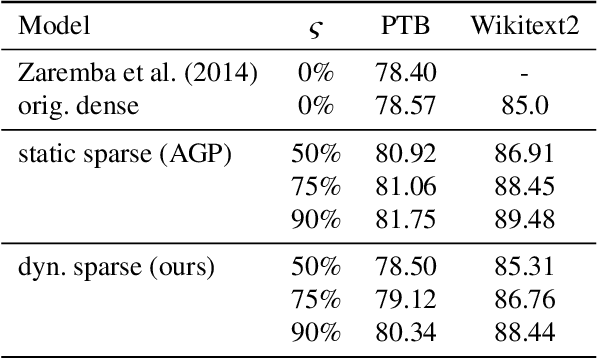
Neural networks have achieved state of the art performance across a wide variety of machine learning tasks, often with large and computation-heavy models. Inducing sparseness as a way to reduce the memory and computation footprint of these models has seen significant research attention in recent years. In this paper, we present a new method for \emph{dynamic sparseness}, whereby part of the computations are omitted dynamically, based on the input. For efficiency, we combined the idea of dynamic sparseness with block-wise matrix-vector multiplications. In contrast to static sparseness, which permanently zeroes out selected positions in weight matrices, our method preserves the full network capabilities by potentially accessing any trained weights. Yet, matrix vector multiplications are accelerated by omitting a pre-defined fraction of weight blocks from the matrix, based on the input. Experimental results on the task of language modeling, using recurrent and quasi-recurrent models, show that the proposed method can outperform a magnitude-based static sparseness baseline. In addition, our method achieves similar language modeling perplexities as the dense baseline, at half the computational cost at inference time.