 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoTwiCS: A Corpus for Modelling Emotion Trajectories in Dutch Customer Service Dialogues on Twitter
Oct 10, 2023Due to the rise of user-generated content, social media is increasingly adopted as a channel to deliver customer service. Given the public character of these online platforms, the automatic detection of emotions forms an important application in monitoring customer satisfaction and preventing negative word-of-mouth. This paper introduces EmoTwiCS, a corpus of 9,489 Dutch customer service dialogues on Twitter that are annotated for emotion trajectories. In our business-oriented corpus, we view emotions as dynamic attributes of the customer that can change at each utterance of the conversation. The term `emotion trajectory' refers therefore not only to the fine-grained emotions experienced by customers (annotated with 28 labels and valence-arousal-dominance scores), but also to the event happening prior to the conversation and the responses made by the human operator (both annotated with 8 categories). Inter-annotator agreement (IAA) scores on the resulting dataset are substantial and comparable with related research, underscoring its high quality. Given the interplay between the different layers of annotated information, we perform several in-depth analyses to investigate (i) static emotions in isolated tweets, (ii) dynamic emotions and their shifts in trajectory, and (iii) the role of causes and response strategies in emotion trajectories. We conclude by listing the advantages and limitations of our dataset, after which we give some suggestions on the different types of predictive modelling tasks and open research questions to which EmoTwiCS can be applied. The dataset is available upon request and will be made publicly available upon acceptance of the paper.
A Million Tweets Are Worth a Few Points: Tuning Transformers for Customer Service Tasks
Apr 16, 2021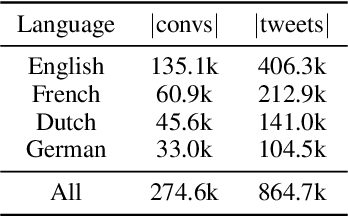
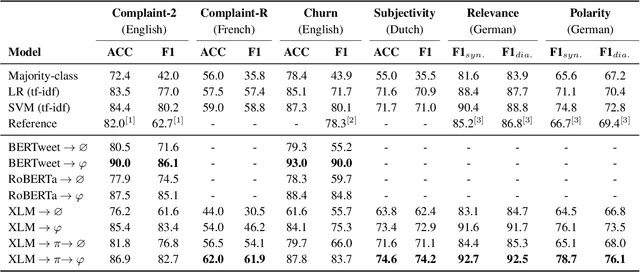
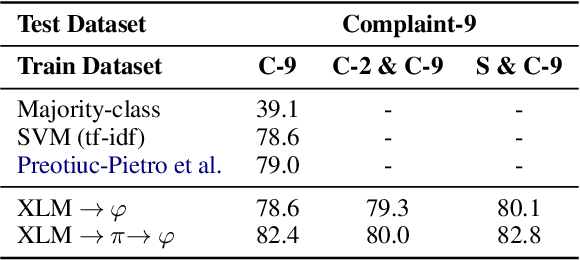
In online domain-specific customer service applications, many companies struggle to deploy advanced NLP models successfully, due to the limited availability of and noise in their datasets. While prior research demonstrated the potential of migrating large open-domain pretrained models for domain-specific tasks, the appropriate (pre)training strategies have not yet been rigorously evaluated in such social media customer service settings, especially under multilingual conditions. We address this gap by collecting a multilingual social media corpus containing customer service conversations (865k tweets), comparing various pipelines of pretraining and finetuning approaches, applying them on 5 different end tasks. We show that pretraining a generic multilingual transformer model on our in-domain dataset, before finetuning on specific end tasks, consistently boosts performance, especially in non-English settings.