 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Million Tweets Are Worth a Few Points: Tuning Transformers for Customer Service Tasks
Paper and Code
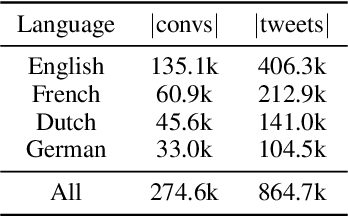
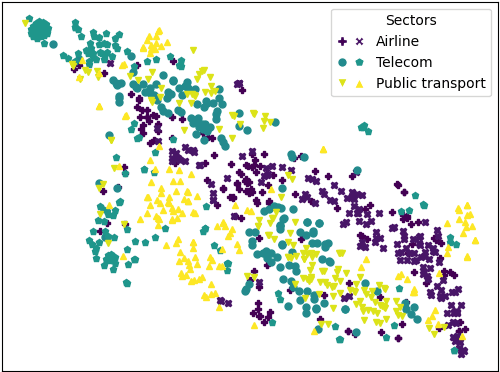
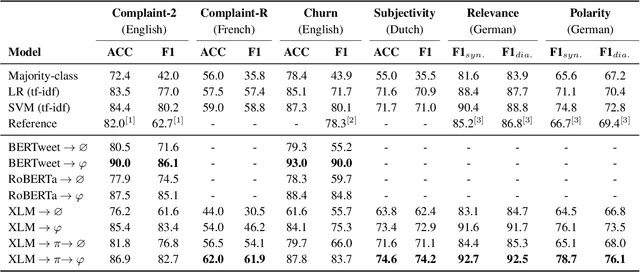
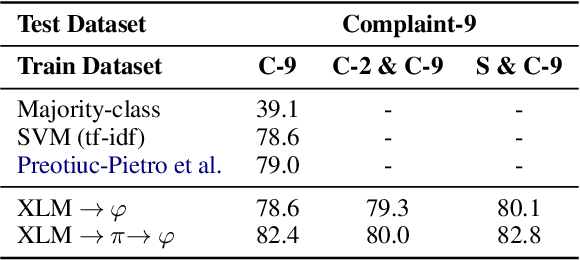
In online domain-specific customer service applications, many companies struggle to deploy advanced NLP models successfully, due to the limited availability of and noise in their datasets. While prior research demonstrated the potential of migrating large open-domain pretrained models for domain-specific tasks, the appropriate (pre)training strategies have not yet been rigorously evaluated in such social media customer service settings, especially under multilingual conditions. We address this gap by collecting a multilingual social media corpus containing customer service conversations (865k tweets), comparing various pipelines of pretraining and finetuning approaches, applying them on 5 different end tasks. We show that pretraining a generic multilingual transformer model on our in-domain dataset, before finetuning on specific end tasks, consistently boosts performance, especially in non-English settings.